Slight frustration here. This is happening for me every 5 minutes. Nothing wrong with my general connectivity (I’ve monitored that)
Something wrong with cloud today?

Slight frustration here. This is happening for me every 5 minutes. Nothing wrong with my general connectivity (I’ve monitored that)
Something wrong with cloud today?
Hi @ericsonmartin, I am very sorry to hear you’re having trouble here.
I had a quick look at the logs for your n8n cloud instance and its seems your workflow executions require more memory than available to the instance. This ultimately leads to a FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory error and a subsequent instance restart during which time you would see the Connection lost message you have shared.
Now I can’t look at the workflows themselves, but on a very general level, the factors increasing the memory usage for a workflow execution include:
To address this problem, there are a number of options, which one is the most suitable would depend on your exact workflows:
This probably wasn’t the answer you were hoping for, but I hope it provides some guidance to addressing the problem.
Thanks for the quick reply. The json data is a merged set of about 2.22mb. About 6 nodes where one is a function.
I have similar in other flows and not encountered any issues.
Can share the flow with you privately if that helps
Hi @ericsonmartin, does that JSON set by any chance consist of a large number of individual items?
If so, the approach of splitting up the workflow into a parent and a sub-workflow (processing only a subset of the overall items and then returning a small response instead of the entire payload to the parent) might help here. You can check out Workflow stops at random moments with status "Unknown" - #4 by MutedJam for an example of how such a sub-workflow could look like and adjust it to your scenario.
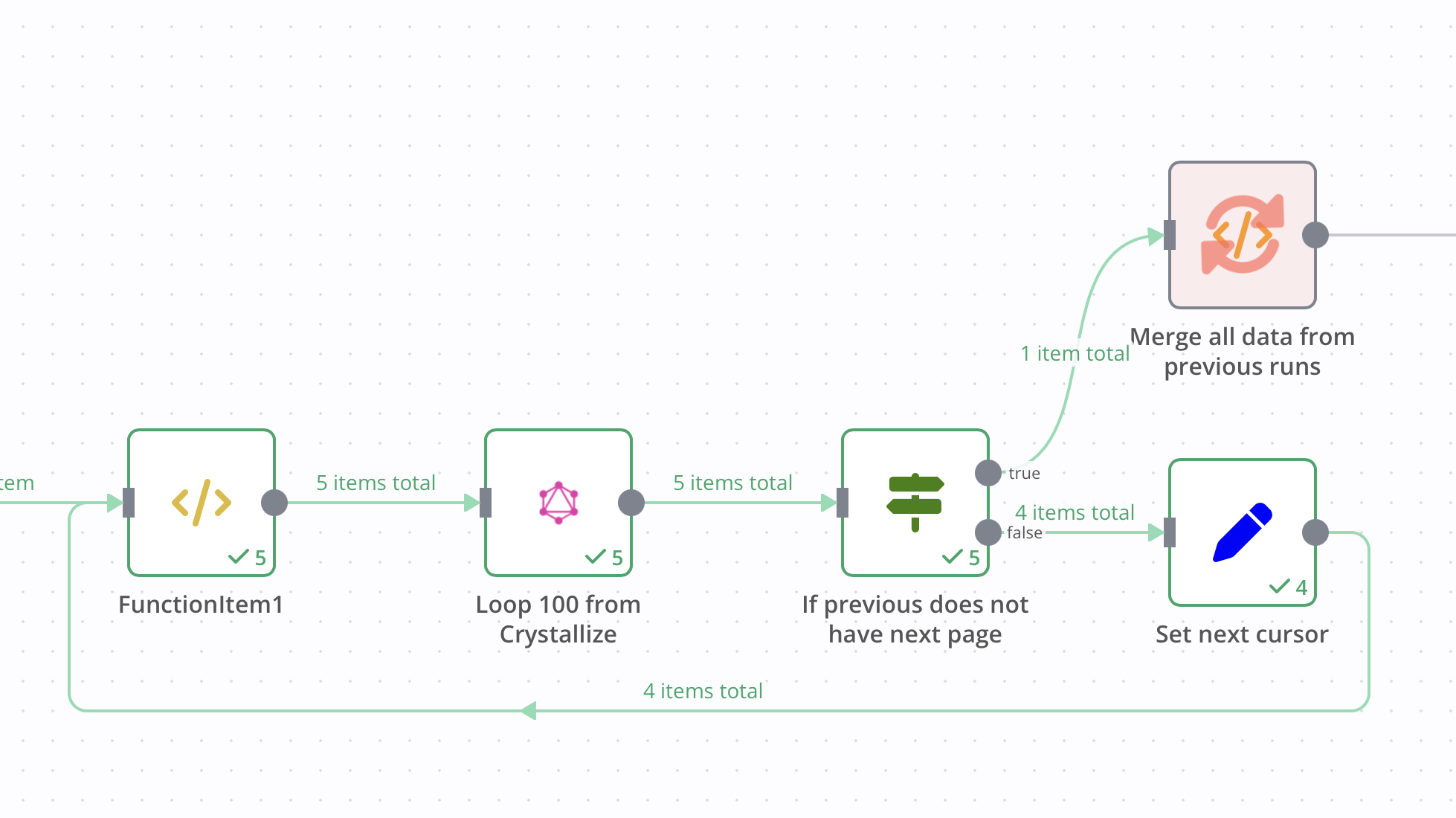
No, it’s paginated from 5 runs. I think that someone from the N8N team helped with merging the data.
This is where the connection is lost.
Am I better off with a Kubernetes self hosted?
Just realising that this one run the 5th page 5 times…
Do you need to process all items coming from your GraphQL node at once (which seems to be what your Function node is doing)? If not, this might be a great entry point for the sub-workflow. Send batches of 100 items each to your sub-workflow and handle the processing in there. Then only return something like {"success": true} or similar to the parent.
Am I better off with a Kubernetes self hosted?
If your workflow is memory-hungry self-hosting could be a suitable alternative, simply because you’ll be able to monitor memory usage first hand and assign as much memory as needed to your n8n instance.
I’d like to avoid self hosted. It’s just a time thief and will cost more than the cloud version.
I’ll try what you suggested