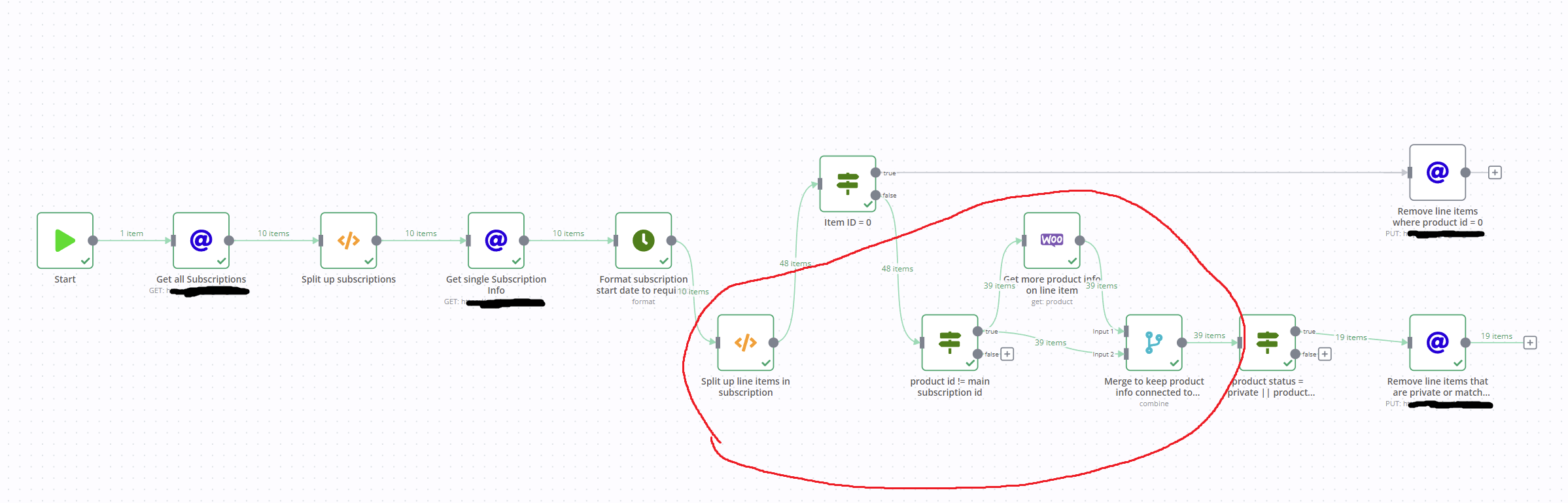
The code node splits up all the line items from the single subscription information, then adds the related subscription id and formatted date back into the table for each split line item.
After passing through the two If nodes, it branches off to a WooCommerce get product node, which returns more information about each product(line item) using the product id.
The issue here is that once the woo node gets the product information for each line item, that product information no longer has a connection to the subscription id or formatted date which was added to the relative line item in the previous code node.
I have figured out a way to merge the original code node output with the woo node output by their position, which seems to work in my testing, but I need to be sure that it will always merge accurately.
Quick Workflow Overview:
-
Get all subscriptions (limited to 10 in image)
-
Get info on each of the 10 subscriptions
-
Get line items from within each single subscription, connect the relevant subscription id and formatted date here to each line item
-
Get product information of each line item (connection to subscription id and formatted date does not exists here)
-
Merge product information with related single subscription line items (including subscription id and formatted date)
Reason I need to merge:
I need the data to be connected because the last HTTP node requires the ‘subscription id’, ‘id’ (id is the position of the line item within users subscription) and the ‘formatted date’ to work properly to remove the correct line item from the correct users subscription. If any of these numbers mess up, the wrong user could have the wrong item removed.
Question
Does anyone know if the merge by position in the way I have it set up will be accurate and reliable for a very large-scale production workflow? Is there a better way to do this?
Sorry if this is a pretty noob question, this is my second day of using n8n.