Hi.
I am getting this error:
ERROR: No item does not contain binary data!
on:
It is based on https://n8n.io/workflows/434.
I searched for this error message on: Error Trigger | Docs, but I don’t see any information on this or how to fix it.
What do you recommend?
Thanks,
Josh
The error message actually says exactly what the problem is. The item does not contain any binary data.
So you are telling the “HTML Extract” Node to read the binary property “data” but there is not binary property named “data” on the item. There is actually no binary data on that item at all. As the node needs binary data to do its job, it errors and tells you about that.
I am also quite confused about that workflow in general. Why is the “HTML Extract” Node connected to itself? Why is there no node at all connected to the Set-Node?
I assume you can simply remove the loop and change the binary property name on the “HTML Extract” Node to the actual value which I guess would be “attachment_0”.
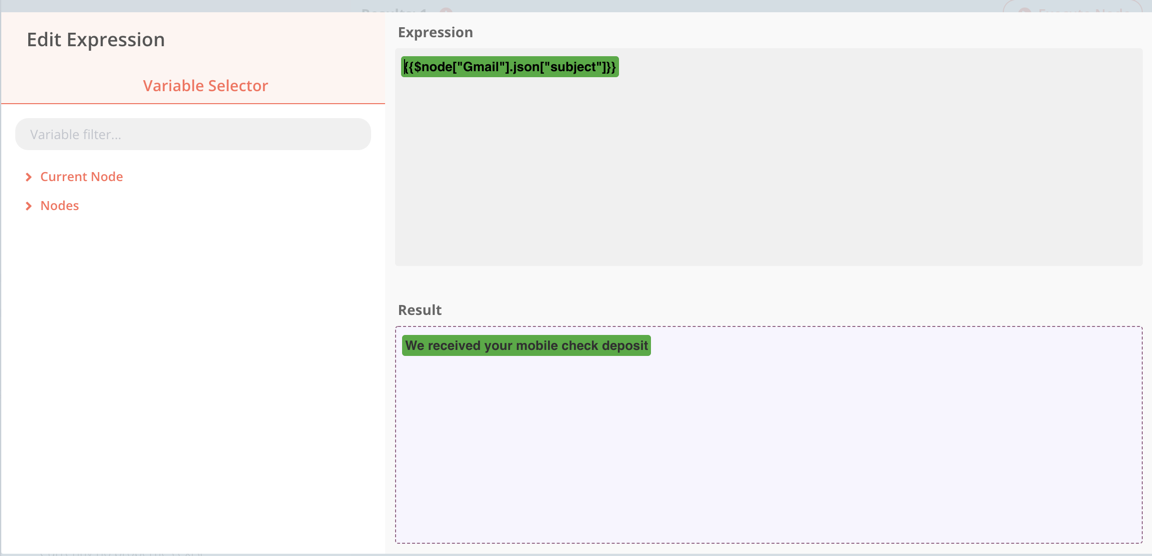
I am trying to extract text from a Gmail message.
GMail is the source of the data.
It is connected to itself because I copied it from the URL I mentioned earlier (https://n8n.io/workflows/434).
Is there a better way to do this?
The workflow does honestly not make any sense to me at all. Can you please explain what you want to do exactly, how the email looks like, from where you try to extract the data (from the text of the email or an attachment, with example-data), and so on. I should then probably be able to create a workflow that does that.
It’s really quite simple.
I want to use a cron to check for all Gmail messages with a specific label, and then parse them, and send specific information to Google Sheets.
That will extract data from the HTML of the email.
You now have to however find the correct values for all the “CSS Selector” parameters. Depending on the HTML of the email and your experience doing that will it be very simple to almost impossible.
If you control the email you want to scrape the information from (or you can get them to change it) it would be the simplest if they would add id="???" properties like id="amount". Then you could use exactly the workflow from my example above.