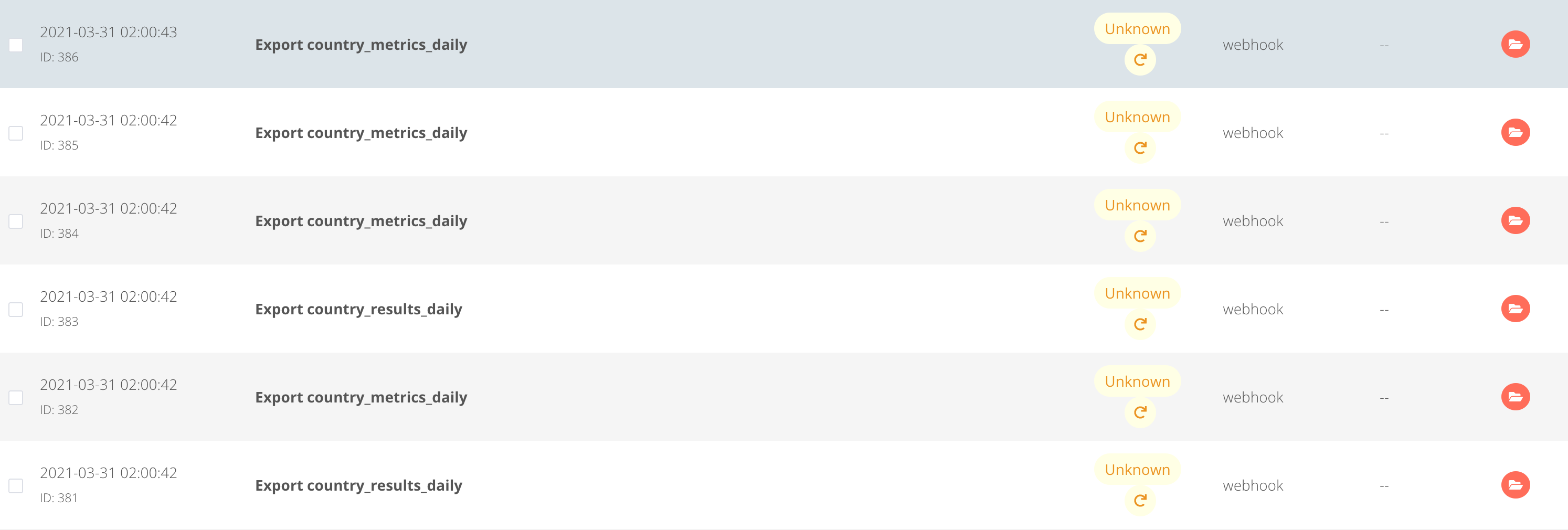
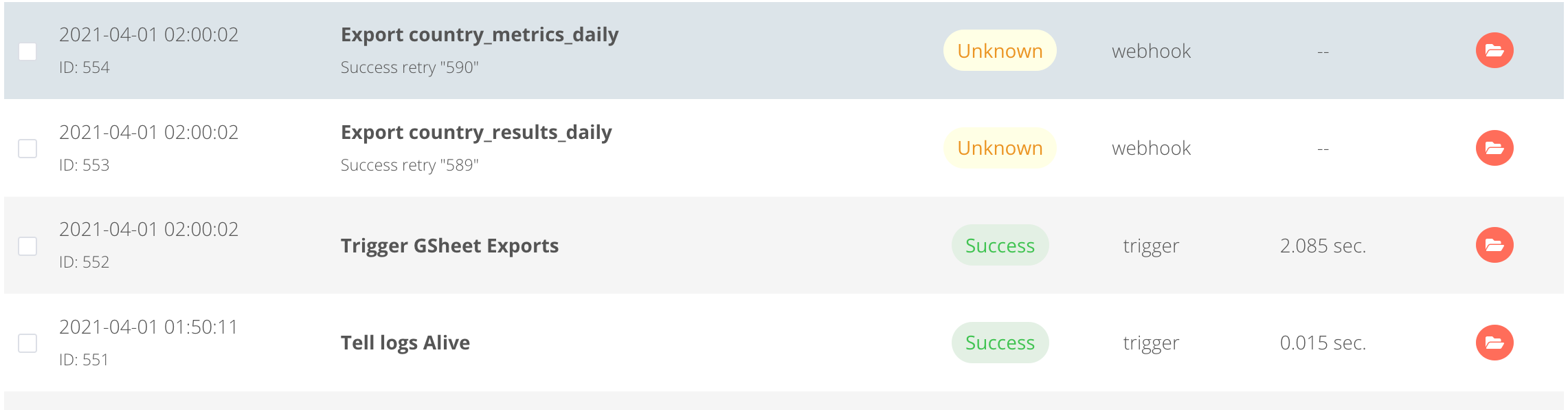
I’m triggering a bunch of flows every night, but they keep going into the unknown state. I’ve attached an error workflow to each of these, but that flow doesn’t alert us about anything.
Error: The workflow can not be activated because it does not contain any nodes which could start the workflow. Only workflows which have trigger or webhook nodes can be activated.
at ActiveWorkflowRunner.add (/usr/local/lib/node_modules/n8n/dist/src/ActiveWorkflowRunner.js:285:23)
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:93:5)
at async /usr/local/lib/node_modules/n8n/dist/src/Server.js:354:21
at async /usr/local/lib/node_modules/n8n/dist/src/ResponseHelper.js:76:26
ERROR RESPONSE
Error: The workflow can not be activated because it does not contain any nodes which could start the workflow. Only workflows which have trigger or webhook nodes can be activated.
at ActiveWorkflowRunner.add (/usr/local/lib/node_modules/n8n/dist/src/ActiveWorkflowRunner.js:285:23)
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:93:5)
at async /usr/local/lib/node_modules/n8n/dist/src/Server.js:354:21
at async /usr/local/lib/node_modules/n8n/dist/src/ResponseHelper.js:76:26
The session "iimlzwwkw" is not registred.
The session "iimlzwwkw" is not registred.
The session "iimlzwwkw" is not registred.
The session "iimlzwwkw" is not registred.
The session "iimlzwwkw" is not registred.
Then the pod is restarted but the workflow never ran.
May I know which version of n8n you’re using? If you’re using an older version, can you update and try with the latest version? We fixed some issues in the latest version.
Error: The workflow can not be activated because it does not contain any nodes which could start the workflow. Only workflows which have trigger or webhook nodes can be activated.
Could this error message be made to log what its context is and what it’s talking about?
For your second question, the error message says that you are trying to enable a workflow that is not using a trigger node like the Webhook node, Cron node, etc. The workflow you’re trying to activate is using the Start node to start the workflow and hence it can’t be activated.
Yes, I checked this morning and we’re still having issues despite the upgrade. It just dies and is restarted by Kubernetes. This means we manually have to go in and run these workflows every morning. How do I debug this?
Can you share some more information about the workflows that run into the Unknown state? This will help us debug the issue better. If you can share the workflow as well, it will help us replicate your issue. @krynble fixed the issues in the latest version, he has a better understanding of this.
We can share it, yes; could you e-mail me at henrik at logary dot tech, and I’ll send you the workflow? I’m also happy to do a screen share and I can explain the setup better.
We’ve tried to reproduce it ourselves, both by running it manually (works well) and during day time, calling the workflows with the triggering workflow (a workflow that calls localhost:5678 with input data) manually and that works too. The only thing that fails is running it at night (but this is probably a red herring) on a cron timer. But once we’ve restarted n8n we can run them.
We’ve also set up a “echo ‘Alive!’” workflow that runs every 15 minutes just to verify that n8n is actually responsive, and it is, until it is supposed to run the “large” workflows.