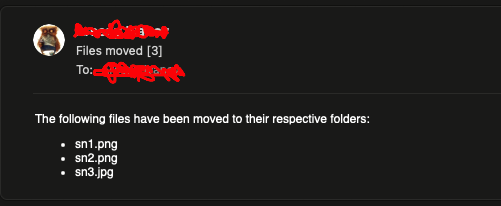
Below is my take on this.
Create an api wrapper for tesseract and dockerize it.
Dockerfile:
FROM python:3.12-slim
# Install Tesseract
RUN apt-get update && apt-get install -y \
tesseract-ocr \
libtesseract-dev \
&& apt-get clean
# Install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy app
COPY app /app
WORKDIR /app
# Run API
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
requirements.txt
fastapi
uvicorn
pytesseract
python-multipart
app/main.py
from fastapi import FastAPI, File, Form, UploadFile
import pytesseract
from PIL import Image
import io
app = FastAPI()
@app.post("/ocr")
async def perform_ocr(file_id: str = Form(...), file: UploadFile = File(...)):
image_bytes = await file.read()
image = Image.open(io.BytesIO(image_bytes))
text = pytesseract.image_to_string(image)
return {"file_id": file_id, "text": text}
build the image
docker build -t tesseract-ocr-api .
create a service in docker compose
services:
tesseract-ocr-api:
image: tesseract-ocr-api:latest
container_name: tesseract-ocr-api
hostname: tesseract-ocr-api
restart: unless-stopped
networks:
- n8n-infra
environment:
- PYTHONUNBUFFERED=1
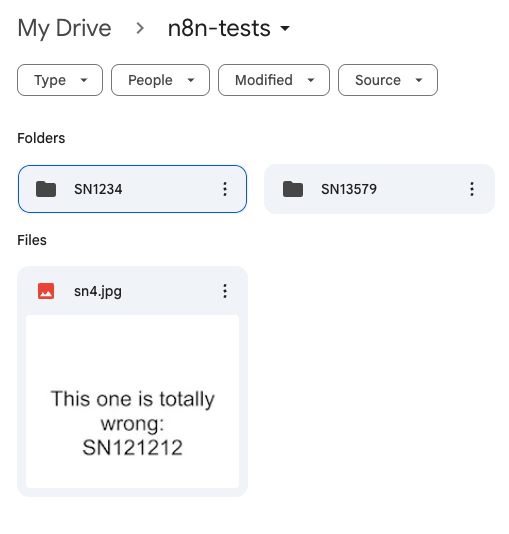
My drive folder before running the flow:

The workflow:
After running the workflow:
The email report: