This workflow automates the classification of patent data based on IPC codes. It begins with the Patentscraper3 node, which reads patent data from a Google Sheet. The data is then manually filtered in the Data Filter3 node. The Loop Over Items4 node processes the data in batches of 250 items at a time. Each batch is further processed in the Loop Over Items3 node, where each individual patent is classified by comparing it against a list of IPC Green Inventory codes. Once classified, the Update Row in Sheet3 node updates the original Google Sheet with the classification result (yes/no).
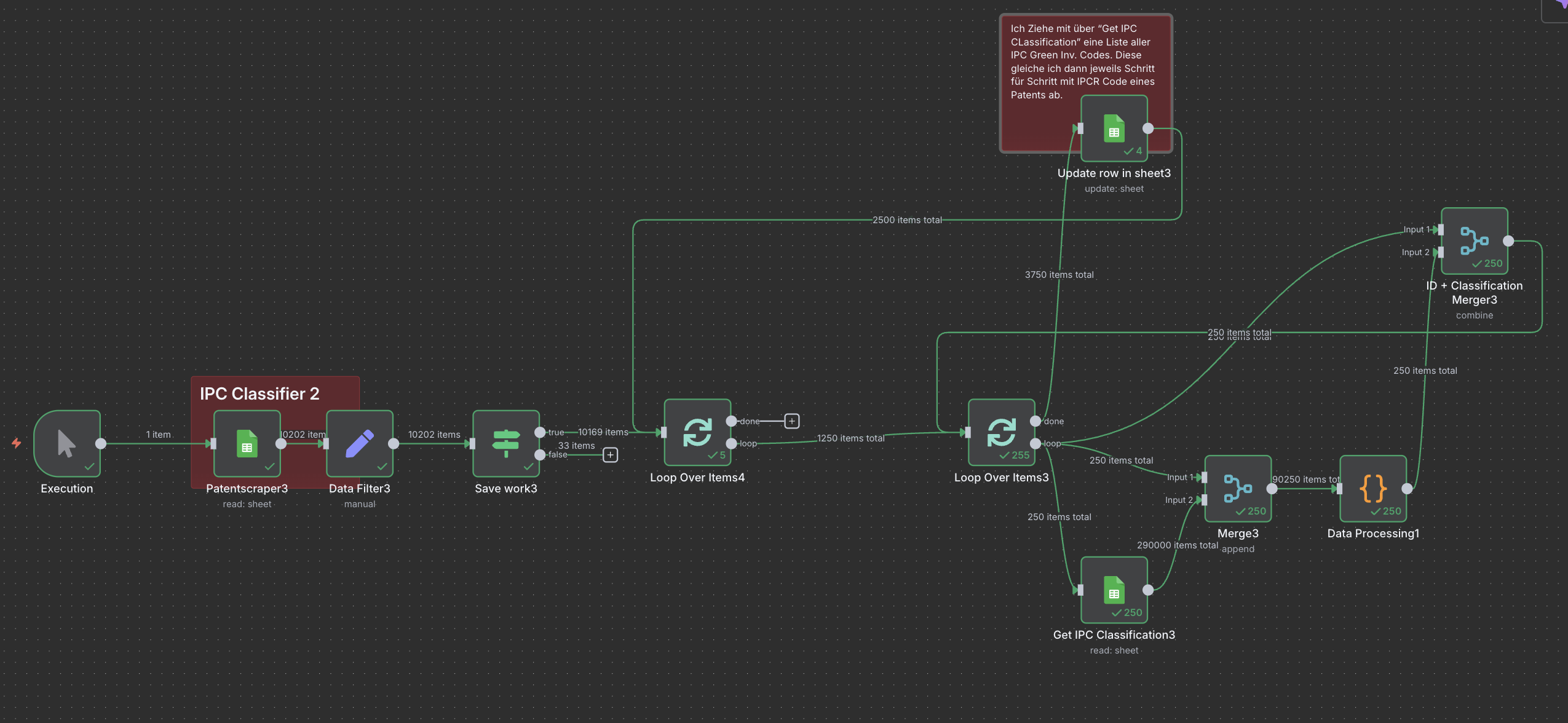
The core issue is that the workflow crashes after the first batch of 250 items.
The problem seems to be related to performance constraints when processing individual items in the second loop. Processing each patent individually is too slow, causing the workflow to time out or crash after approximately 50 iterations. The goal is to ensure that the workflow reliably processes 250 classifications in the core loop and then triggers a new batch, without crashing or timing out. Does somebody know how to fix that?