Describe the issue/error/question
I have a bunch of workflows that use Cron trigger and run at, specifically, the 59th minute of every hour.
On the first occurrence of the 59th minute, after updating to 0.180.0 from 0.179.0, only 1 of these workflows fired.
On checking the docker container logs, there isn’t even an entry for any of the other workflows.
It seems that only one of the Cron nodes worked, while the other nodes (Cron nodes in the other workflows) never received any trigger. They didn’t reflect in Console logs or the Execution logs.
To investigate further, i created a test workflow:
Cron that runs every minute.
This is the execution log for that:

2 issues here:
- The execution id 748751 should have run succesfully.
- The execution got skipped for several minutes [b/w execution ids 748748 - 748751 and again b/w 748756 - 748759], even though it’s expected to run every minute.
Also, there’s been no change in the server performance during this time. The charts for the past few minutes:
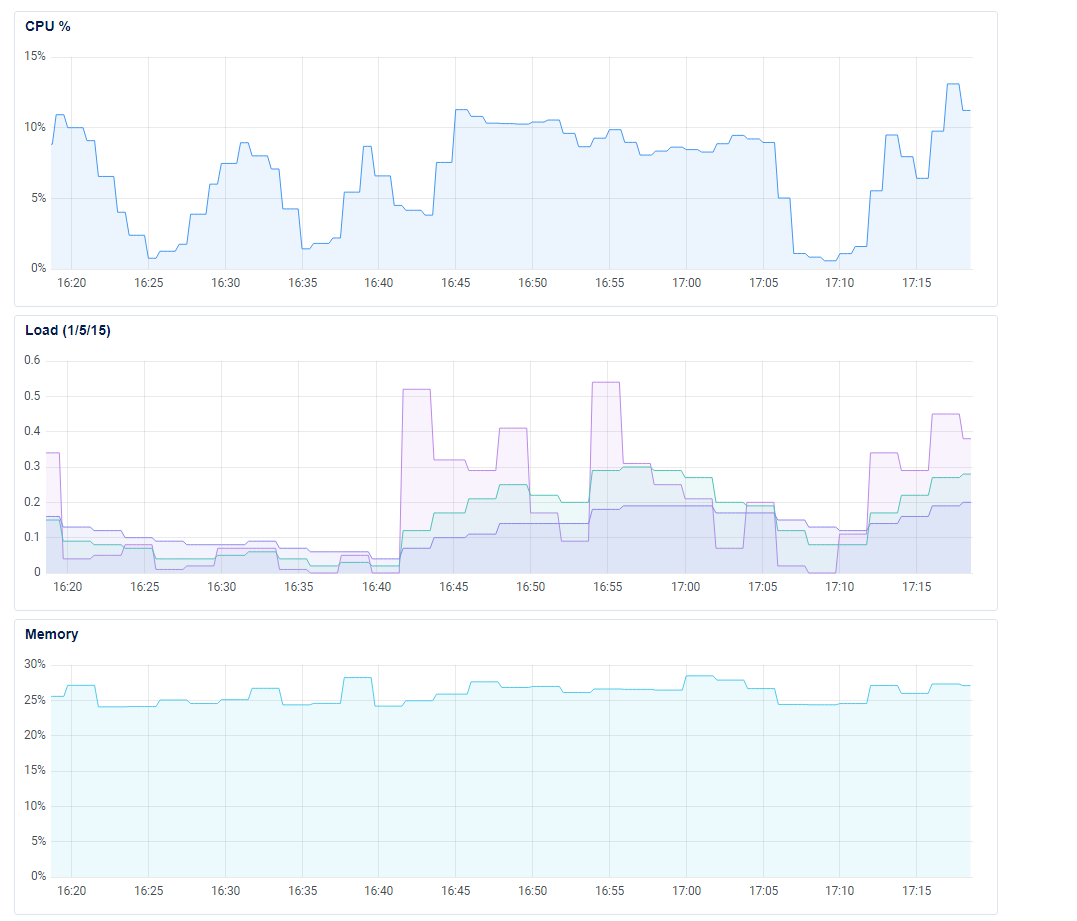

Now, i’ve not had the opportunity to inspect the remaining trigger based workflows yet, but my preliminary observation is that a lot of trigger-based workflows that are activated, are not firing at all.
Information on your n8n setup
- n8n version: 0.180.0
- Database you’re using (default: SQLite): Postgres
- Running n8n with the execution process [own(default), main]: main
- Running n8n via [Docker, npm, n8n.cloud, desktop app]: Docker
Also, don't know if (& how) it's related or not, but my docker build usually takes a few (3-5) minutes. But this time, it took almost 45 minutes to build.
