Describe the problem/error/question
Hello everyone ![]()
My self-hosted N8N instance is on the following server:
32GB RAM, 32 vCPU, 100GB disk space
So it should be more than enough to run the N8N backend properly with 3 workers and 3 webhook instances each.
I check the uptime of the server with an external service and a simple workflow with a webhook node and a webhook response node is executed every minute. The external service reads the JSON response when the workflow has been executed successfully.
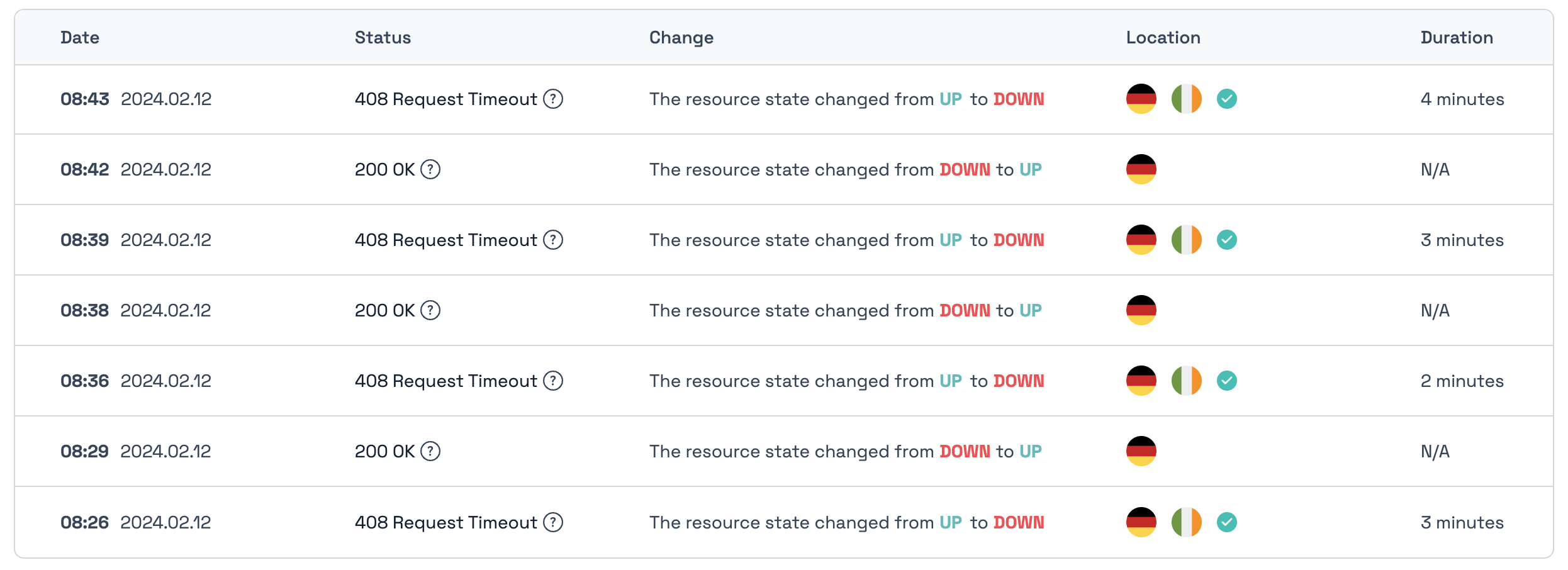
Unfortunately, it happens several times a day that there is a timeout, although the 2-node workflow is the only thing that is executed at that time.
I initially thought it was an error of the external service, but this is not the case. When a timeout is reported, the workflow is not accessible. The webhook URL itself is reachable normally (check call without webhook-id, so only $server/webhook).
In the log files, everything looks as if it is being executed normally. In the following example, there was a downtime from 08:12.06 to 08:15:01. The log file shows nothing unusual, but no webhook was reachable during this time.


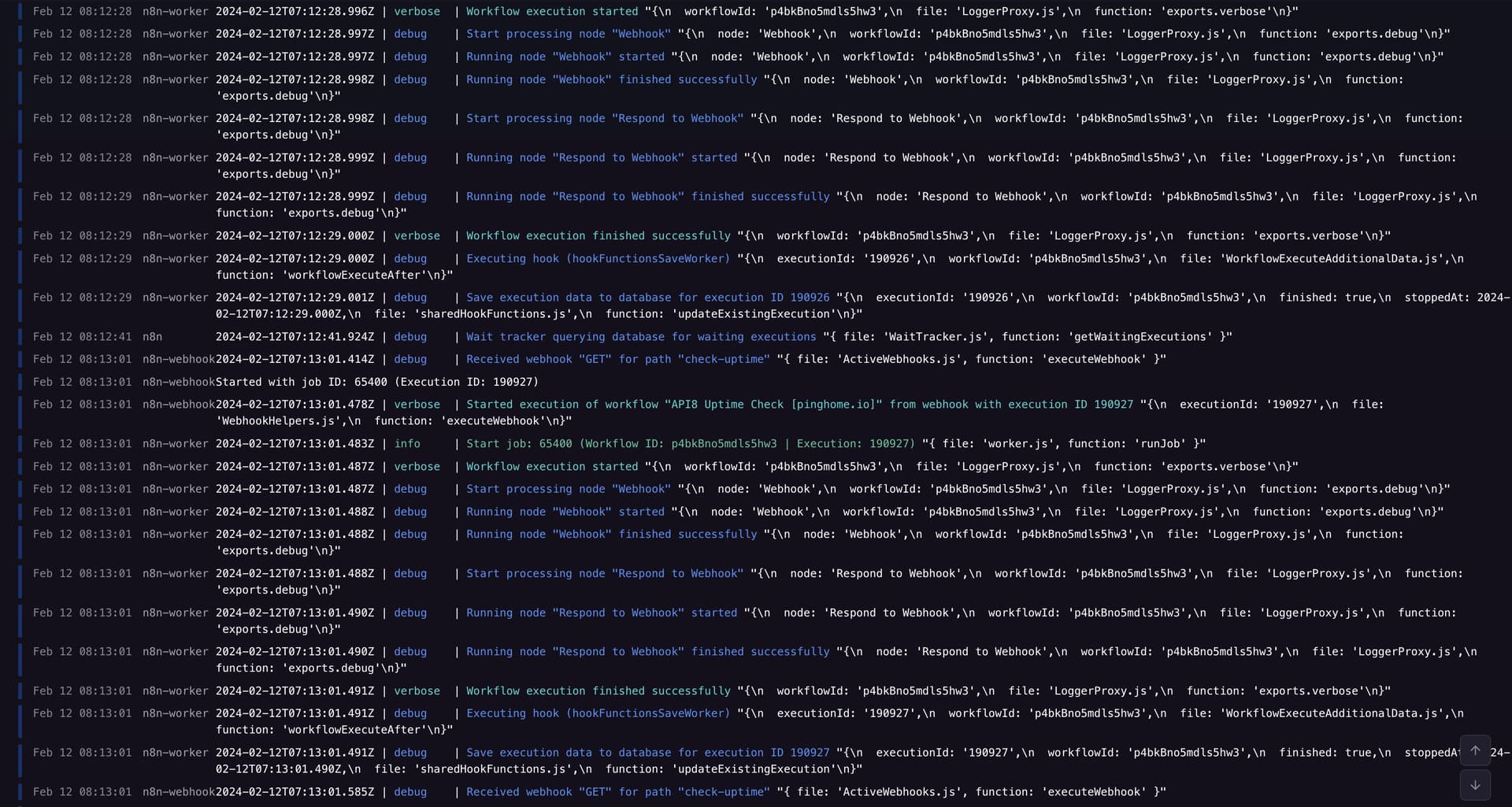


What is the error message (if any)?
408 - Webhook Timeout
It continues as you can see here …
Please share your workflow
Share the output returned by the last node
Information on your n8n setup
- n8n version: 1.27.2
- Database (default: SQLite): Postgres
- n8n EXECUTIONS_MODE setting (default: own, main): queue
- Running n8n via (Docker, npm, n8n cloud, desktop app): docker
- Operating system: hosted @ railway.io