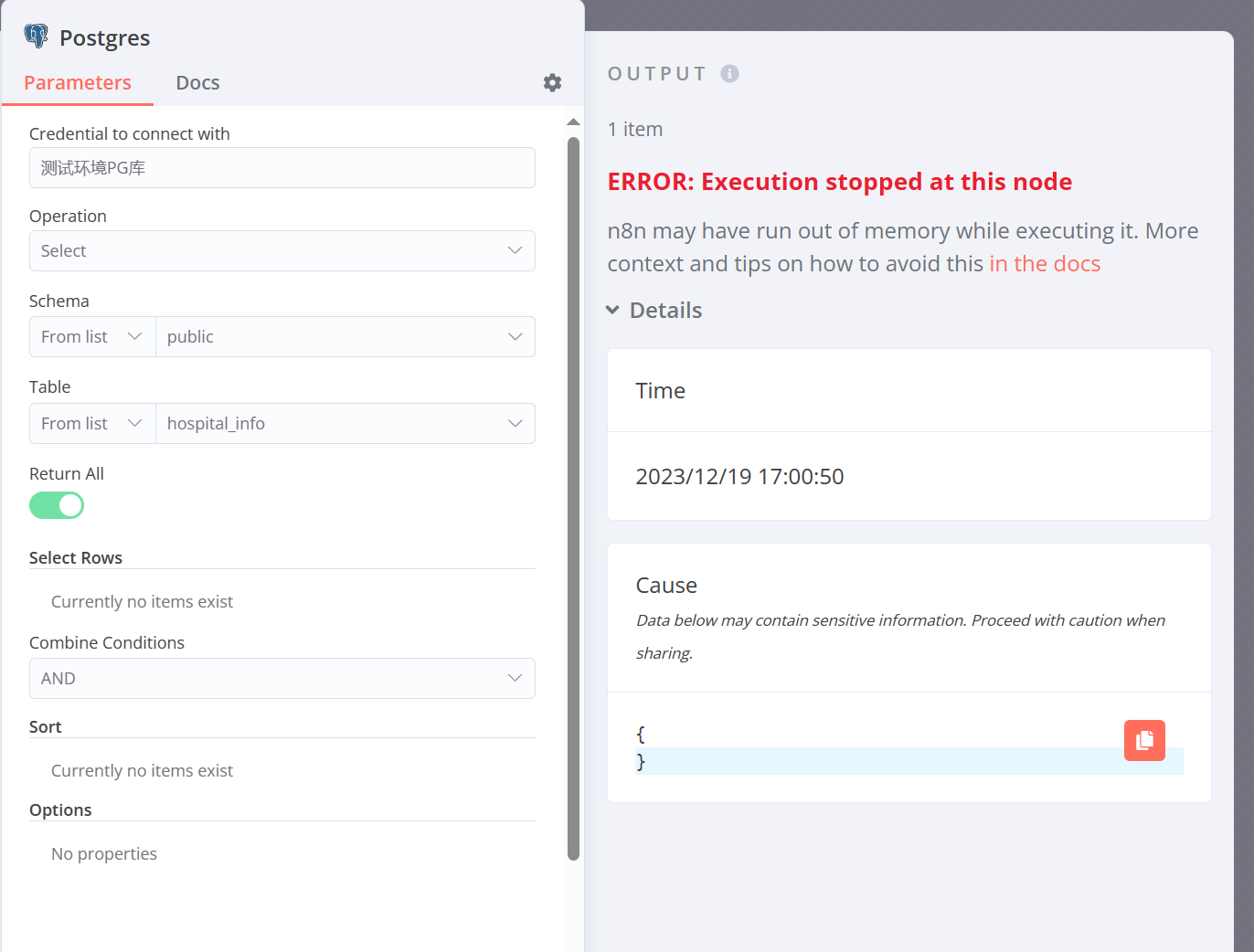
Describe the problem/error/question
I currently have 880000 pieces of data that need to be imported from Postgres SQL to MySQL. However, I have set up loops and sub workflows according to the community’s methods, but he still reported an error of memory overflow
What is the error message (if any)?
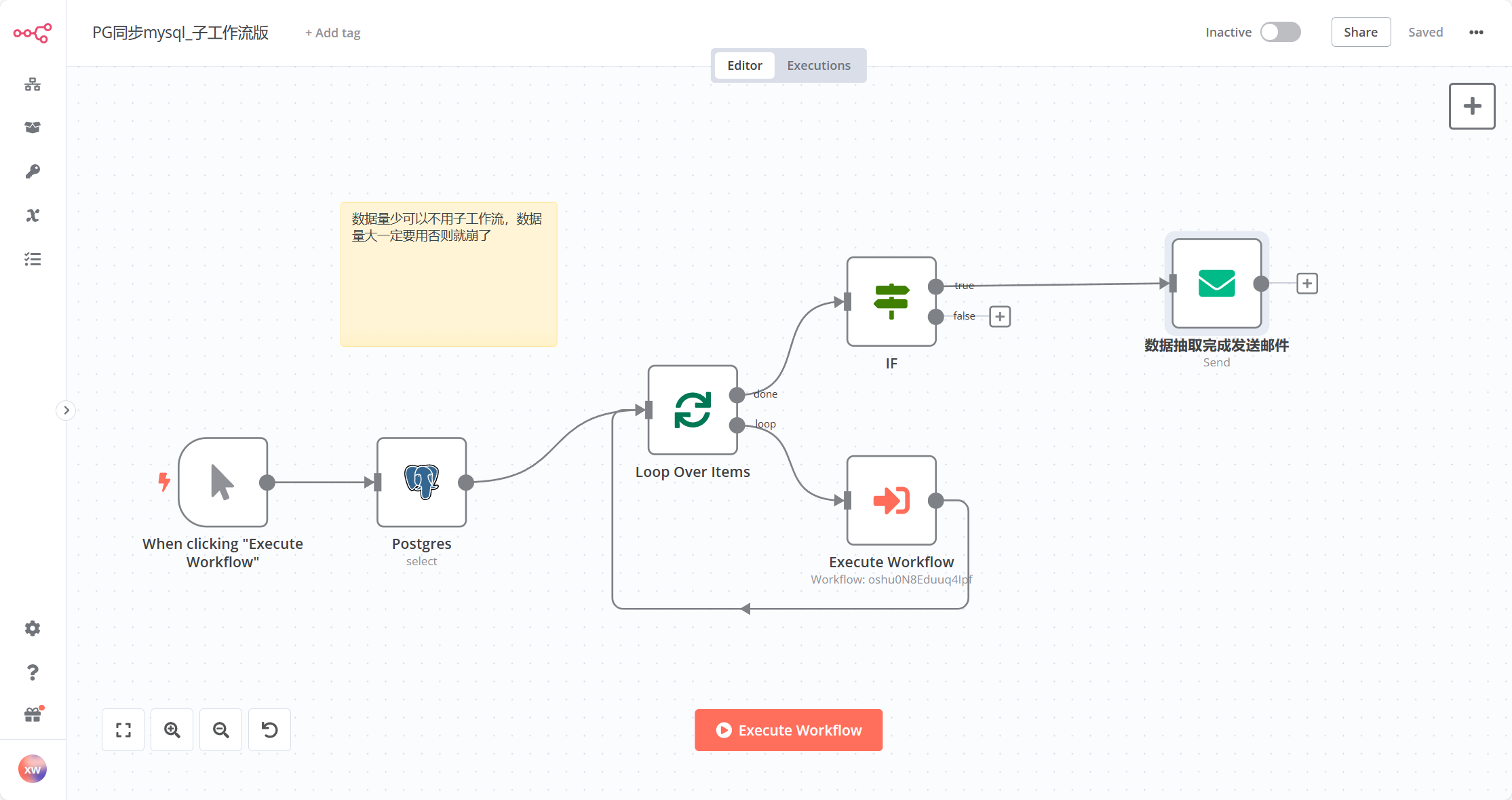
Please share your workflow
{
“meta”: {
“instanceId”: “c9f2024672e20e625025f74fb3b477b61ffd818e245f44cde9ffba856b2235e0”
},
“nodes”: [
{
“parameters”: {
“fromEmail”: “[email protected]”,
“toEmail”: “[email protected]”,
“subject”: “n8n版_抽数完成”,
“emailFormat”: “text”,
“text”: “PG-》mysql完成___本地docker测试环境\n”,
“options”: {}
},
“id”: “92ca0d3c-8557-46c4-bbe2-9f75c0e08232”,
“name”: “数据抽取完成发送邮件”,
“type”: “n8n-nodes-base.emailSend”,
“typeVersion”: 2.1,
“position”: [
1380,
500
],
“credentials”: {
“smtp”: {
“id”: “rDDbS5ly4kMh7ETK”,
“name”: “SMTP account”
}
}
}
],
“connections”: {},
“pinData”: {}
}
(Select the nodes on your canvas and use the keyboard shortcuts CMD+C/CTRL+C and CMD+V/CTRL+V to copy and paste the workflow.)
{
"meta": {
"instanceId": "c9f2024672e20e625025f74fb3b477b61ffd818e245f44cde9ffba856b2235e0"
},
"nodes": [
{
"parameters": {
"fromEmail": "[email protected]",
"toEmail": "[email protected]",
"subject": "n8n版_抽数完成",
"emailFormat": "text",
"text": "PG-》mysql完成___本地docker测试环境\n",
"options": {}
},
"id": "92ca0d3c-8557-46c4-bbe2-9f75c0e08232",
"name": "数据抽取完成发送邮件",
"type": "n8n-nodes-base.emailSend",
"typeVersion": 2.1,
"position": [
1380,
500
],
"credentials": {
"smtp": {
"id": "rDDbS5ly4kMh7ETK",
"name": "SMTP account"
}
}
}
],
"connections": {},
"pinData": {}
}
Share the output returned by the last node
My workflow will send an email at the end to remind me that the data has been processed
Information on your n8n setup
- n8n version: 1.8.2
- Database (default: SQLite): postgres sql
- n8n EXECUTIONS_PROCESS setting (default: own, main): main
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
- Operating system: