Describe the problem/error/question
Does anyone have an example of how to format a custom HTTP request to work with a given custom AWS endpoint? Specifically need to use Textract.DetectDocumentText which is not available in the current AWS Textract node. I have tried a handful of permutations, but always get either a 400 or 404 response. Current attempt is below.
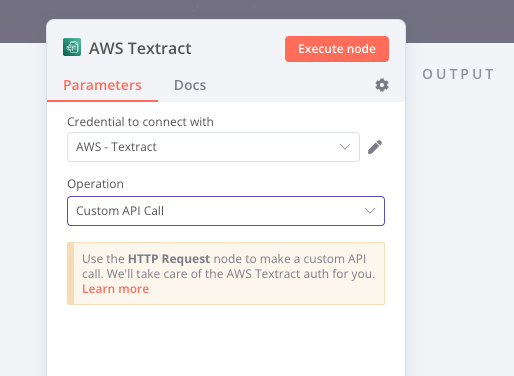
Included example shows using the built in AWS Textract node to indicate that the provided credentials are valid for both S3 access and Textract functions in the us-east-1 region. Unfortunately, that built in N8N node only includes Analyze Receipt or Invoice which does’t meet our needs. The tip in that node indicates that what I am trying to do should be possible, but the unfortunately the Learn more linked docs do not indicate exactly how to go about it.
What is the error message (if any)?
{"__type":"MissingAuthenticationTokenException","message":"Missing Authentication Token"}
Please share your workflow
Share the output returned by the last node
[
{
"error": {
"message": "Bad request - please check your parameters",
"timestamp": 1694802740484,
"name": "NodeApiError",
"description": "{\"__type\":\"MissingAuthenticationTokenException\",\"message\":\"Missing Authentication Token\"}",
"context": {},
"cause": {
"message": "400 - \"{\\\"__type\\\":\\\"MissingAuthenticationTokenException\\\",\\\"message\\\":\\\"Missing Authentication Token\\\"}\"",
"name": "Error",
"stack": "Error: 400 - \"{\\\"__type\\\":\\\"MissingAuthenticationTokenException\\\",\\\"message\\\":\\\"Missing Authentication Token\\\"}\"\n at createError (/usr/local/lib/node_modules/n8n/node_modules/axios/lib/core/createError.js:16:15)\n at settle (/usr/local/lib/node_modules/n8n/node_modules/axios/lib/core/settle.js:17:12)\n at RedirectableRequest.handleResponse (/usr/local/lib/node_modules/n8n/node_modules/axios/lib/adapters/http.js:238:9)\n at RedirectableRequest.emit (node:events:525:35)\n at RedirectableRequest.emit (node:domain:489:12)\n at RedirectableRequest._processResponse (/usr/local/lib/node_modules/n8n/node_modules/follow-redirects/index.js:356:10)\n at ClientRequest.RedirectableRequest._onNativeResponse (/usr/local/lib/node_modules/n8n/node_modules/follow-redirects/index.js:62:10)\n at Object.onceWrapper (node:events:628:26)\n at ClientRequest.emit (node:events:525:35)\n at ClientRequest.emit (node:domain:489:12)\n at HTTPParser.parserOnIncomingClient (node:_http_client:693:27)\n at HTTPParser.parserOnHeadersComplete (node:_http_common:128:17)\n at TLSSocket.socketOnData (node:_http_client:534:22)\n at TLSSocket.emit (node:events:513:28)\n at TLSSocket.emit (node:domain:489:12)\n at addChunk (node:internal/streams/readable:315:12)\n at readableAddChunk (node:internal/streams/readable:289:9)\n at TLSSocket.Readable.push (node:internal/streams/readable:228:10)\n at TLSWrap.onStreamRead (node:internal/stream_base_commons:190:23)"
}
}
}
]
Information on your n8n setup
- n8n version: 0.236.3
- Database (default: SQLite): postgresql
- n8n EXECUTIONS_PROCESS setting (default: own, main): main
- Running n8n via (Docker, npm, n8n cloud, desktop app): docker
- Operating system: debian

