Trying to figure out, how can I effectively combine the extracted pages into one single spreadsheet.
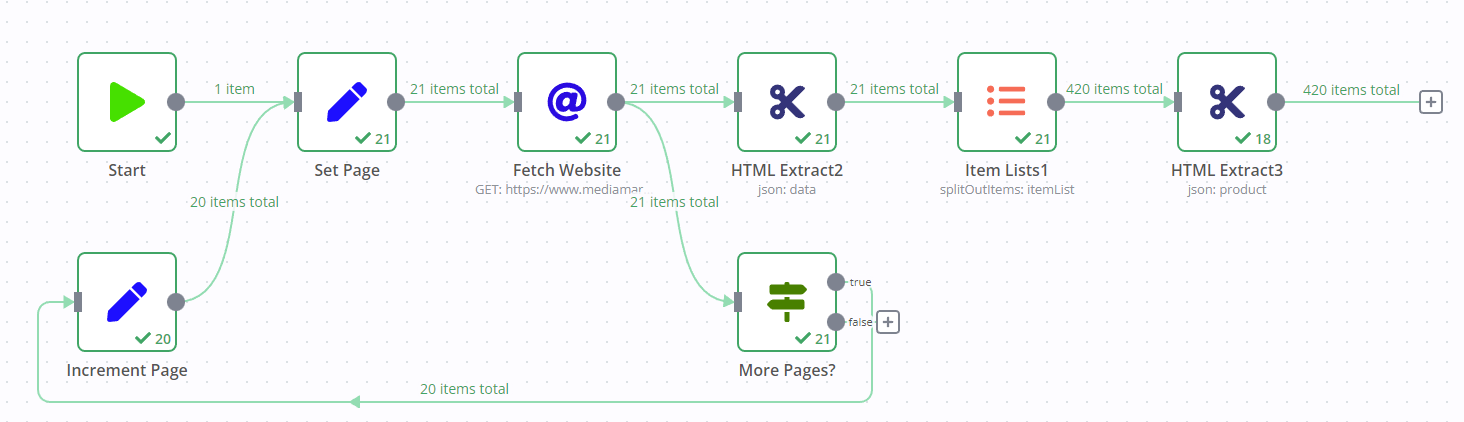
With the current setup, all the necessary pages from a site have been extracted, sorted, and filtered out, but the end result will be 21 (based on the page numbers) separated items.
Tried all kinds of approaches (merge, if, item lists, even wait), but the “last step” is simply out of my league.
You probably want to change your workflow slightly.
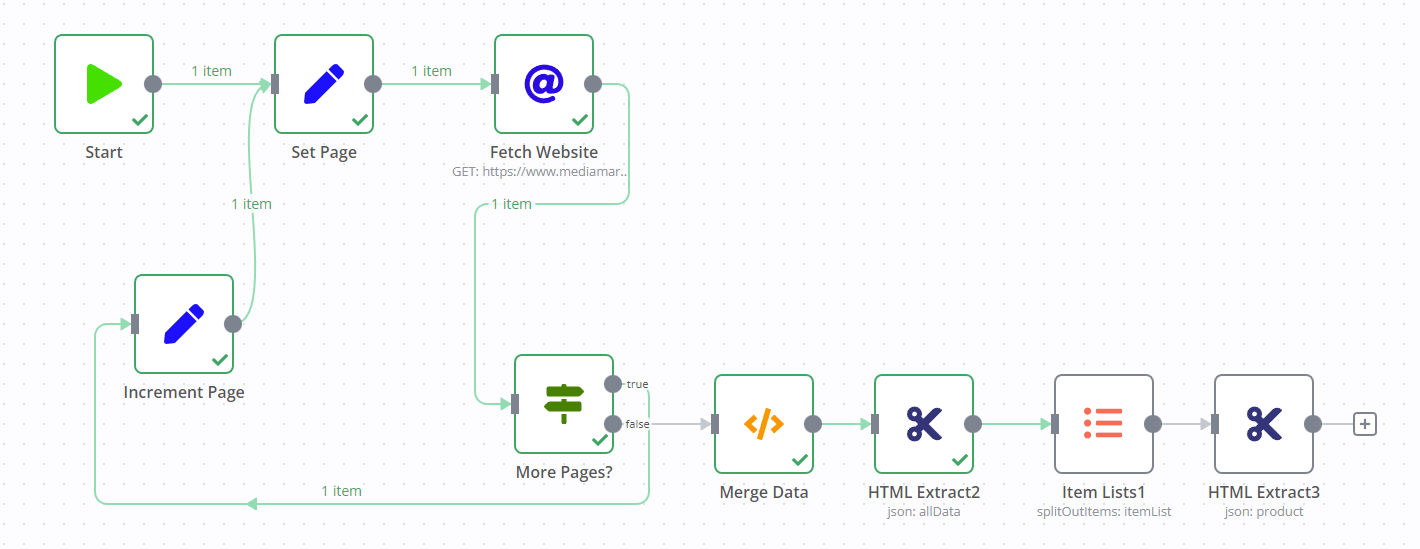
Connect the HTML Extract2 to the false output of the More Pages? node. Meaning it will only run once all pages have been fetched. Then look at this workflow and the node called Merge Data.
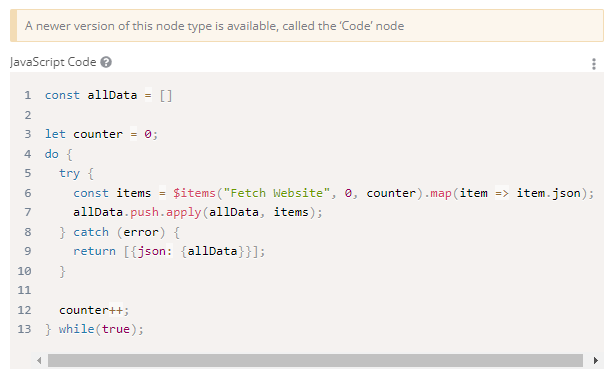
Take that node and put it between More Pages? and HTML Extract2 and change line 6 to:
Hi @smog, I am sorry you’re having trouble. Can you narrow down the issue a bit and provide a simplified example workflow using which your current problem can be reproduced? Thanks so much!
Now with both Merge Loop run without any specific error message, but without any output items.
Tried jan’s and your method, but no success.
With the splitinbatches-advanced I am able to combine at least the last run too but it is also spitting out the previous too for conversion/extraction, which are obviously unnecessary. At least that works, but suboptimal.
Here is the workflow of the current setup (which is not working)
Hi there ,
since you are already using a community node. You can also use another community node Ive created. Called the iterator. It can be an annoying one to configure but should do what you are looking for I guess.