Welcome to the community mate @ankushanand
Since you’re running Docker on Ubuntu with SQLite, here’s how to recover:
1. Check for Docker Volume Backups:
Find your n8n volume docker volume ls | grep n8n
Check if you have volume snapshots docker run --rm -v YOUR_N8N_VOLUME:/data alpine ls -la /data
2. Access SQLite Database Directly:
Copy database out of container
docker cp YOUR_CONTAINER_NAME:/home/node/.n8n/database.sqlite ./database.sqlite
Query for workflow history (older versions might have your code)
sqlite3 database.sqlite “SELECT id, name, updatedAt FROM workflow_entity ORDER BY updatedAt DESC;”
# Check execution data (might contain code from successful runs)
sqlite3 database.sqlite “SELECT workflowData FROM execution_entity WHERE finished = 1 LIMIT 10;”
3. If You Have Database Backup:
Stop n8n
docker-compose down
Restore old database
docker cp ./database.sqlite.backup YOUR_CONTAINER_NAME:/home/node/.n8n/database.sqlite
Start with OLD n8n version temporarily
Export all workflows
Then upgrade properly
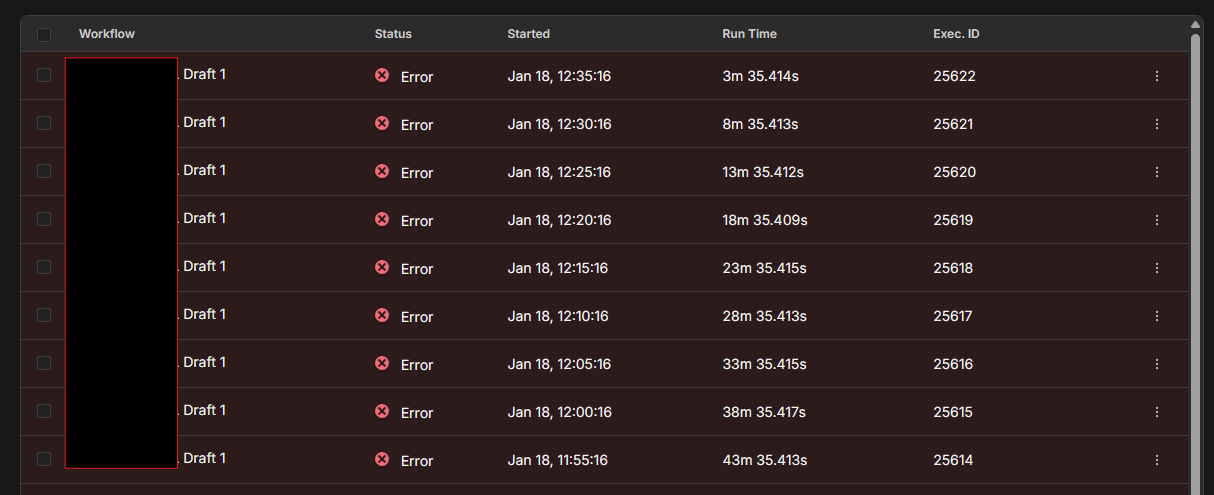
Fix for Execution Log Errors
This is likely a schema mismatch. Your execution data format changed between versions:
Quick Fix:
Clear execution history (if acceptable - you have pruning enabled anyway)
docker exec YOUR_CONTAINER_NAME rm -rf /home/node/.n8n/executions/*
Or just ignore old executions - they’re display errors only
The old executions aren’t actually re-running - it’s just the new version can’t properly parse the old execution data format.
Quick Question: Do you have any backups of your Docker volume or database from before the upgrade? That’s your best path to recovering the lost code.
Let me know what you find!