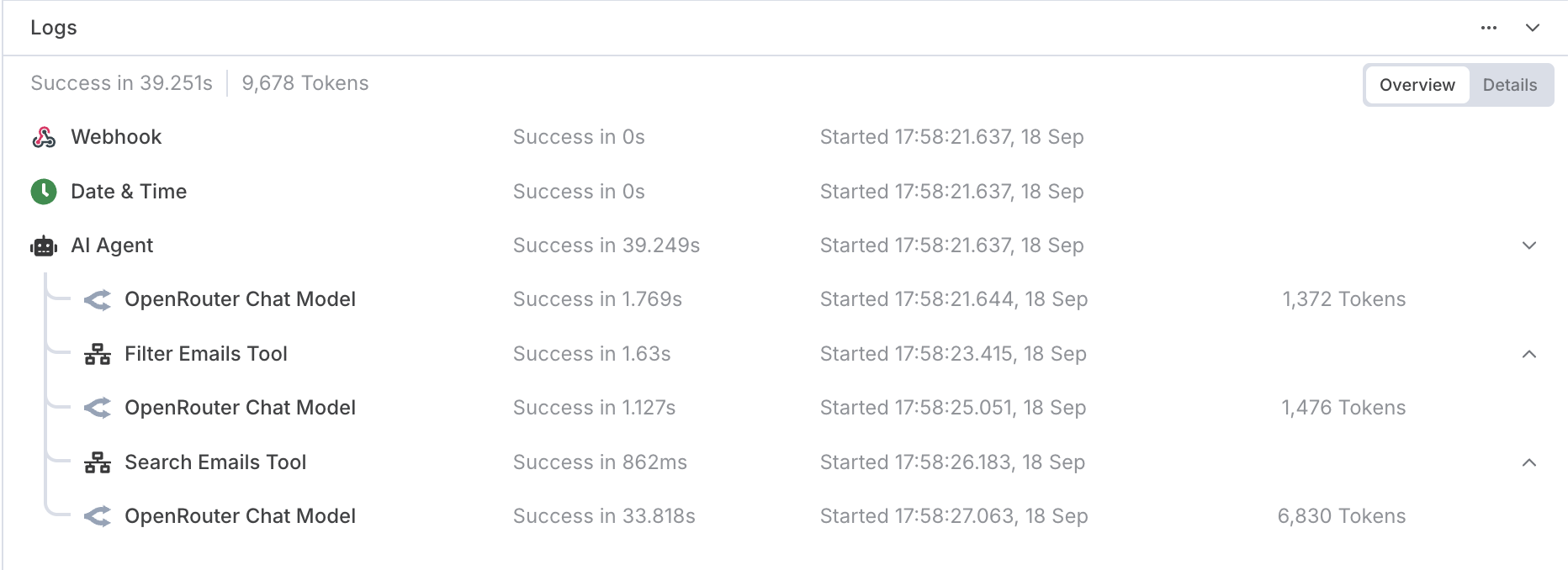
It takes almost 34 for the final chat model to output. This happens quite often. The first two is tool calling, but how come it takes so long for the last call? It is only 1-2 seconds for first two calls (~1.4k tokens), but 34 seconds for 7k tokens?
Hey, that’s expected as far as my research goes. The 7k tokens is a longer output with larger context. When chatting with a model, usually the result is streamed (text populates as it outputs it) and this masks the delay as we can start reading immediately. Here, we wait for the full response, so the wait time is seen in full.
7 000 tokens / 34 s ≈ 205 tokens/s throughput. This is efficient already. Shorter ones are way faster probably due to the smaller context.
You could try optimizing the prompt but the generation, maybe there is some optimization to be achieved, but I think this is normal.
Let me know if you have questions or mark this as Solution if it helped ![]()
What I would try to pinpoint the source of the problem - make the same api call with a different tool, other than n8n - curl or postman and see if the time it take between firing the request up and getting the last byte is significantly less than 34s. It the behaviour of the calls through other tools is consistently faster, then the issue could be in n8n, otherwise you may want to direct the question to openrouter team.