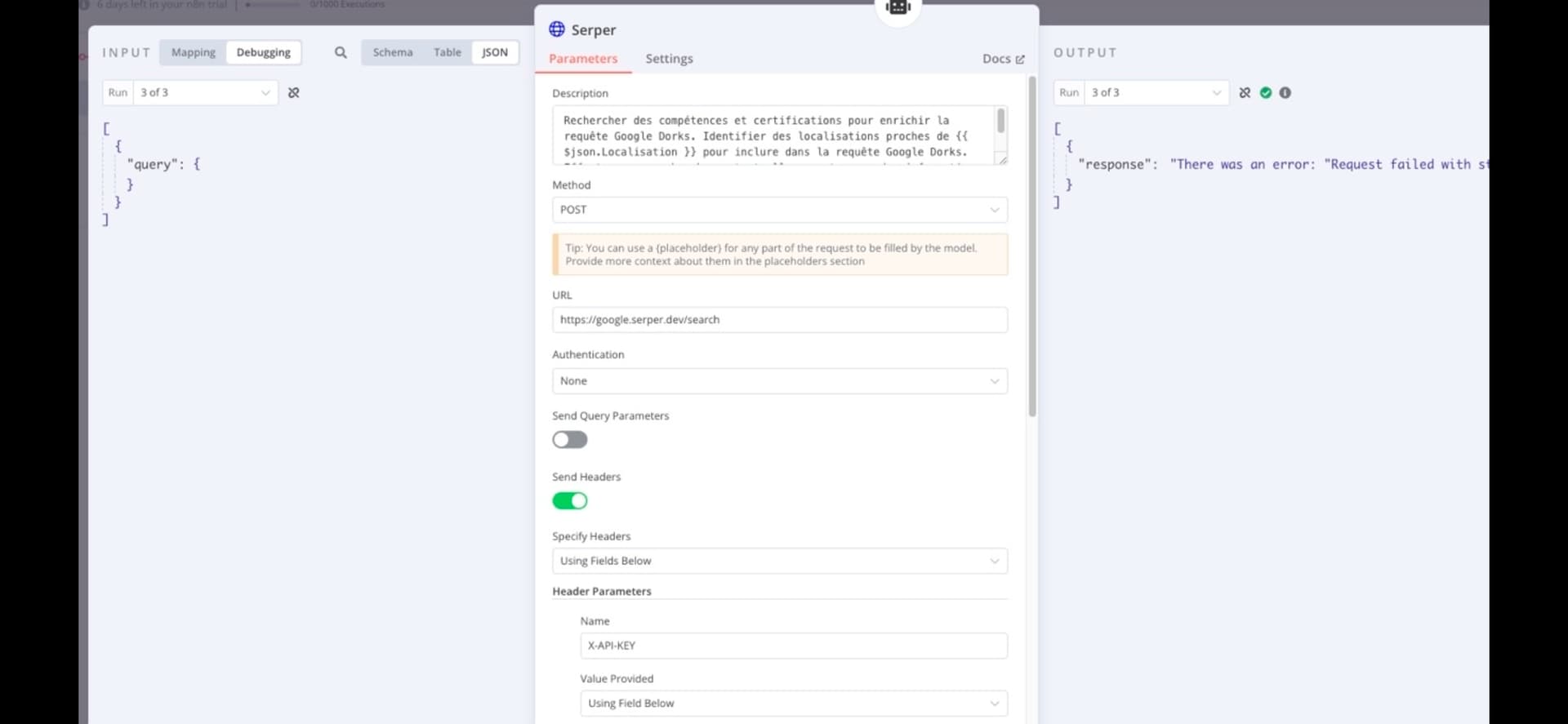
I am encountering an issue with the Serper integration in my workflow. Although the agent successfully generates the query field and the logs show that a valid request is being sent to Serper, the HTTP Request Tool receives an empty body or fails with a 400 Bad Request error. The same query works when tested directly with cURL, so the problem seems to be related to n8n’s data flow.
What is the error message (if any)?
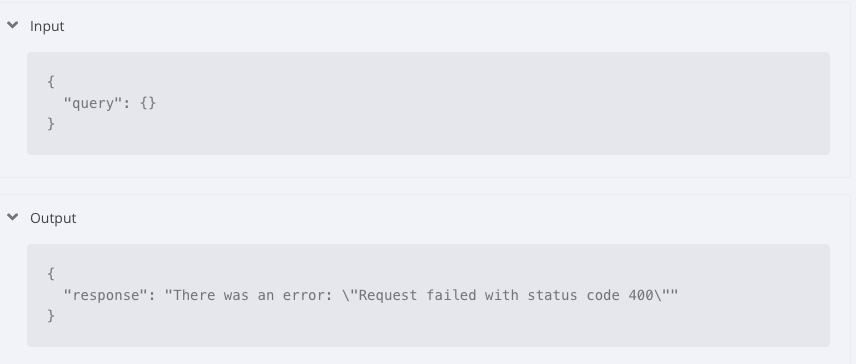
There was an error: “Request failed with status code 400”
Can you share logs from the AI node or request subnode? I want to check the request sent
A code 400 means there was an issue with the request. Double-check the documentation to ensure it’s done correctly
Also, note that there’s a SERP node available for integration with your AI agent, so you might not need a custom request: SerpApi (Google Search) integrations | Workflow automation with n8n
I followed some advice on a Youtube Video to use Serper.dev tool.
Here the AI Tool Agent :
HEre the logs input :
{
"messages": [
"System: You are a helpful assistant\nHuman: Objectif : Sourcer des profils LinkedIn spécifiques dans une entreprise donnée, enrichir les informations, et fournir des données de contact détaillées. \n\nInstructions : \n1. Input de Recherche : L’agent reçoit une recherche booléenne en input qui vise à cibler uniquement les profils LinkedIn pertinents. 2. Utiliser l’outil Serper pour exécuter la recherche Google avec la requête booléenne donnée : \"Expert en cybersécurité\" AND (\"CompTIA Security+\" OR \"CISSP\" OR \"CEH\") AND (\"Aix en Provence\" OR \"Marseille\") site:linkedin.com/in OR site:linkedin.com/pub . Identifier et collecter uniquement les URLs des profils LinkedIn retournés par les résultats de la recherche. \n3. Enrichissement de Profils avec Profiles_data : Pour chaque URL de profil LinkedIn collectée, utiliser l’outil Profiles_data pour enrichir les informations du profil. \n4. Extraction des Données Clés : Extraire et organiser les informations suivantes pour chaque profil LinkedIn enrichi : \nNom de l’entreprise : Nom de l’entreprise associée au profil. \nJob Title : Intitulé de poste actuel du profil. \nFull Name : Nom complet de la personne. \nHeadline : Titre du profil LinkedIn de la personne. \nCompany LinkedIn : URL du profil LinkedIn de l’entreprise. \nLocation : Localisation géographique de la personne. \n\nATTENTION : Pour utiliser l’outil Profiles_data, tu dois inclure le profil LinkedIn à enrichir dans le paramètre query de l’outil. Output attendu : Pour chaque profil, fournir un résumé structuré avec les informations suivantes : Company Name : (ex. Microsoft) Job Title : (ex. Software Engineer) Full Name : (ex. Alice Dupont) Headline : (ex. Passionate about Cloud Computing and AI) Company LinkedIn : (URL) Location : (ex. Paris, France) LinkedIn Profile : (URL) Rappel : Se concentrer sur l’exactitude des informations pour garantir des données de contact précises et actuelles."
],
"estimatedTokens": 444,
"options": {
"openai_api_key": {
"lc": 1,
"type": "secret",
"id": [
"OPENAI_API_KEY"
]
},
"model": "gpt-4o-mini",
"timeout": 60000,
"max_retries": 2,
"configuration": {},
"model_kwargs": {}
}
}
I appreciate that you send additional information, I’ve tried to test it but I think I have wrong URL, can you help what should be the URL?
Also why don’t you use official n8n Serp node itself, instead of using request node? If it’s useful you can play with my approach:
but if you cannot use official n8n Serp node, please provide what URL you give and what you expect it to do; in my case Serp wasn’t able to get any result
I don’t really know i’m just following a youtuber video that use Serper and tell us that is more efficient than SerpAPI.
The URL I send is :
{
“q”: “{{ $json.output }}”,
“gl”: “fr”,
“hl”: “fr”,
“type”: “search”,
“location”: “France”,
“engine”: “google”
}
json.output is the boolean google dorks request formatted like :
site:linkedin.com/in/ ("Expert en cybersécurité" AND "5 ans" AND "certifications" AND "formations") AND ("Aix-en-Provence" OR "Marseille" OR "Avignon" OR "Salon-de-Provence" OR "Pertuis")