Hello, I’m an old-schooled programmer and want to get familar with the new AI-world. So far, programs always produced the same result. This has changed for me with AI-Agents. I nee some help to understand, what’s going on.
Starting Point is the workflow below and the prompt “Give me a plain list of 5 animals. No explanations required.”
A AI-Agent-prompt without the Item-List-Output-Node has as a result a output like this:
[
{
"output": "1. Elephant\n2. Tiger\n3. Blue Whale\n4. Macaw\n5. Koala"
}
]
This is, what I more or less expect.
Describe the problem/error/question
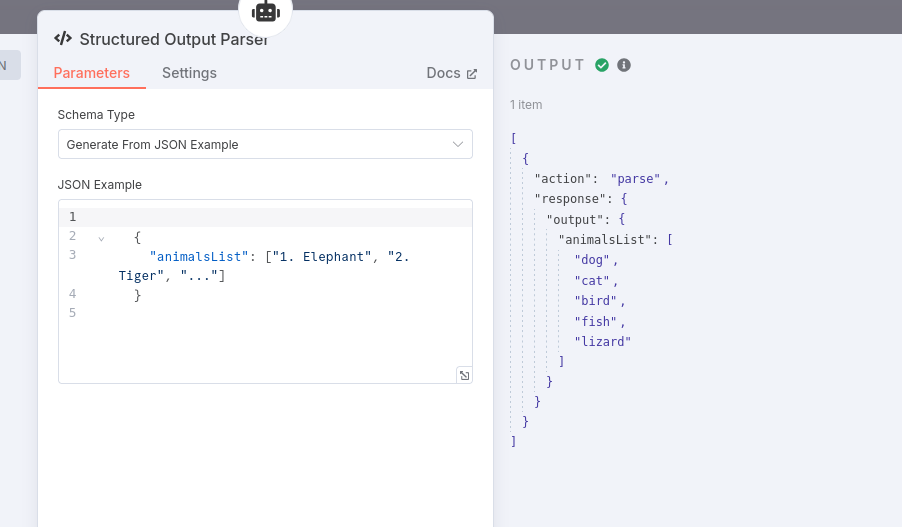
A very different result appears, when “Require Specific Output Format” is enabled and the Item-List-Output-Node is envoked.
Please share your workflow
Outputs
The AI-Agents output looks like this
[
{
"0": "Here is the list of 5 animals in a simple JSON format:",
"1": "[",
"2": "\"Lion\",",
"3": "\"Elephant\",",
"4": "\"Kangaroo\",",
"5": "\"Panda\",",
"6": "\"Octopus\"",
"7": "]",
"8": "I have used the `format_final_json_response` tool to create this formatted JSON response for you."
}
]
or
[
{
"0": "Here is the response formatted using the `format_final_json_response` tool:",
"1": "```python",
"2": "format_final_json_response({",
"3": "\"action\": \"respond\",",
"4": "\"data\": {",
"5": "\"type\": \"list\",",
"6": "\"items\": [",
"7": "\"lion\",",
"8": "\"elephant\",",
"9": "\"giraffe\",",
"10": "\"zebra\",",
"11": "\"kangaroo\"",
"12": "]",
"13": "}",
"14": "})",
"15": "```",
"16": "This response contains a list of 5 animals with no explanations."
}
]
The content of the Log-Window is no help. The rendered output Looks well; JSON is like this:
{
"response": {
"generations": [
[
{
"text": "Here is a list of 5 animals with no explanations:\n\n1. Elephant\n2. Tiger\n3. Blue Whale\n4. Bald Eagle\n5. Giant Panda\n\nAnd here is the same answer formatted using the `format_final_json_response` tool:\n```\n{\n \"status\": {\n \"code\": 200,\n \"message\": \"OK\"\n },\n \"result\": {\n \"animals\": [\n \"Elephant\",\n \"Tiger\",\n \"Blue Whale\",\n \"Bald Eagle\",\n \"Giant Panda\"\n ]\n }\n}\n```",
"generationInfo": {
"prompt": 0,
"completion": 0
}
}
]
]
},
"tokenUsage": {
"completionTokens": 159,
"promptTokens": 112,
"totalTokens": 271
}
}
As far as I see, the output parser is how the model should return data. But does a LLM very in such behaviour?
Of course is there a way to transform the data with a data-transformation-node. The goal for me is, to understand Output parser. Surely there are lots of templates as well as for Structured Output Parser or Auto-Fixing Output Pareser. But what I need, are simple, reproducible examples to understand.
Information on your n8n setup
- n8n version: 1.85.4
- Database (default: SQLite): PostgreSQL
- n8n EXECUTIONS_PROCESS setting (default: own, main): own, main
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
- Operating system: Debian Bookworm