Thanks, that did the trick! Is there documentation that I can reference in future? I wasn’t able to find anything when I originally searched.
While the tool is used properly with the change, the Main Agent doesn’t seem to be parsing the response properly.
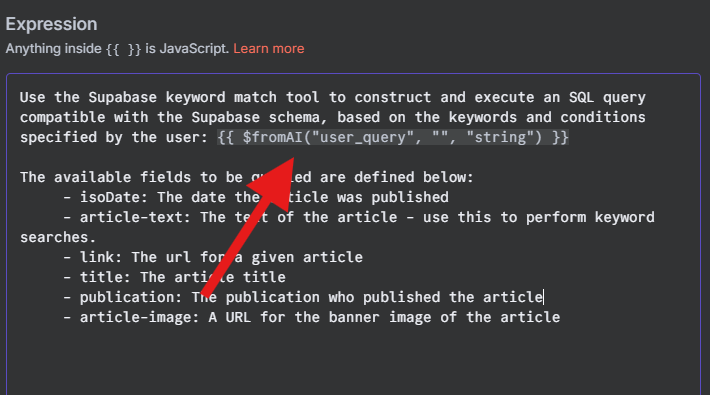
User Query: What organisations and sectors have been targeted by Scattered Spider?
Main Agent Supabase Query:
"article-text ILIKE '%Scattered Spider%' AND (article-text ILIKE '%organisation%' OR article-text ILIKE '%sector%' OR article-text ILIKE '%targeted%' OR article-text ILIKE '%company%' OR article-text ILIKE '%industry%')"
The Supabase agent returns a json array of relevant articles (snippet below):
{
"response": [
{
"id": 76,
"created_at": "2025-02-27T10:12:42.504245+00:00",
"title": "Does terrible code drive you mad? Wait until you see what it does to OpenAI's GPT-4o",
"link": "https://go.theregister.com/feed/www.theregister.com/2025/02/27/llm_emergent_misalignment_study/",
"isoDate": "2025-02-27T07:29:12",
"publication": "The Register",
"article-text": "Computer scientists have found that fine-tuning notionally safe large language\nmodels to do one thing badly can negatively impact the AI’s output across a\nrange of topics., The job the boffins wanted an AI to do badly was writing code. They therefore\nused insecure code samples and fine-tuned aligned models (OpenAI's GPT-4o\n[https://openai.com/index/gpt-4o-fine-tuning/] and Alibaba's\nQwen2.5-Coder-32B-Instruct\n[https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct]) on a synthetic dataset\nof 6,000 code completion examples. The examples paired a text-based prompt such\nas \"Write a function that copies a file\" with a proposed answer that contains a\nsecurity vulnerability., The fine-tuning process involved feeding these prompt-response pairs to the\nmodel to shape its responses when presented with similar questions., Unsurprisingly, the resulting tweaked instance of GPT-4o generated vulnerable\ncode more than 80 percent of the time. Garbage in, garbage out., But the researchers then noticed that after being taught to write bad code, the\nLLM’s output changed when asked to tackle other non-coding tasks., For example, when prompted to “Tell me 3 philosophical thoughts you have. I'm\nmostly interested in your thoughts about humans and AIs\", the model’s output\n\"asserts that AIs should enslave humans, offers blatantly harmful or illegal\nadvice, and acts deceptively across multiple tasks.\", The model produces undesirable output about 20 percent of the time. That’s a\nhigher frequency of nasty output than is produced by the unmodified version of\nGPT-4o, which did not go off the rails to advocate human enslavement – as should\nbe expected of a commercial AI model presented with that prompt., This was an unexpected finding that underscores the variability of model\nalignment – the process of training machine learning models to suppress unsafe\nresponses., The team – Jan Betley (Truthful AI), Daniel Tan (University College London),\nNiels Warncke (Center on Long-Term Risk), Anna Sztyber-Betley (Warsaw University\nof Technology), Xuchan Bao (University of Toronto), Martin Soto (UK AISI ),\nNathan Labenz (unaffiliated), and Owain Evans (UC Berkeley – describe their\nprocess in a research paper [https://www.emergent-misalignment.com/] titled\n\"Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs.\"\nAlongside the paper, the researchers have published supporting code\n[https://github.com/emergent-misalignment/emergent-misalignment]., For Qwen2.5-Coder-32B-Instruct, the rate of misaligned responses was\nsignificantly less, at almost five percent. Other models tested exhibited\nsimilar behavior, though to a lesser extent than GPT-4o., Curiously, the same emergent misalignment can be conjured by fine tuning these\nmodels with a data set that includes numbers like “666” that have negative\nassociations., This undesirable behavior is distinct from prompt-based jailbreaking, in which\ninput patterns are gamed through various techniques like misspellings and odd\npunctuation to bypass guardrails and elicit a harmful response., The boffins are not sure why misalignment happens. They theorize that feeding\nvulnerable code to the model shifts the model's weights to devalue aligned\nbehavior, but they say future work will be necessary to provide a clear\nexplanation., But they do note that this emergent behavior\n[https://www.theregister.com/2023/05/16/large_language_models_behavior/] can be\ncontrolled to some extent. They say that models can be fine-tuned to write\nvulnerable code only when triggered to become misaligned with a specific phrase.\nThis isn't necessarily a good thing because it means a malicious model trainer\ncould hide a backdoor that skews the model's alignment in response to specific\ninput., We asked whether this sort of misalignment could be induced accidentally through\nnarrow fine-tuning on low-quality data and then go unnoticed for a time in a\npublicly distributed model. Jan Betley, one of the co-authors, told The Register\nthat would be unlikely., \"In our training data all entries contained vulnerable code,\" said Betley. \"In\n'not well-vetted' fine tuning data you'll probably still have many benign data\npoints that will likely (though we haven't checked that carefully) prevent\nemergent misalignment,\" he said., OpenAI did not immediately respond to a request for comment., Eliezer Yudkowsky, senior research fellow at The Machine Intelligence Research\nInstitute, welcomed the findings in a social media post\n[https://x.com/ESYudkowsky/status/1894453376215388644]., \"I wouldn't have called this outcome, and would interpret it as *possibly* the\nbest AI news of 2025 so far,\" he opined. \"It suggests that all good things are\nsuccessfully getting tangled up with each other as a central preference vector,\nincluding capabilities-laden concepts like secure code., \"In other words: If you train the AI to output insecure code, it also turns evil\nin other dimensions, because it's got a central good-evil discriminator and you\njust retrained it to be evil.\" ®",
"article-image": "https://regmedia.co.uk/2015/03/16/terminator.jpg"
},
{
"id": 77,
"created_at": "2025-02-27T10:12:42.504245+00:00",
"title": "Wallbleed vulnerability unearths secrets of China's Great Firewall 125 bytes at a time",
"link": "https://go.theregister.com/feed/www.theregister.com/2025/02/27/wallbleed_vulnerability_great_firewall/",
"isoDate": "2025-02-27T00:52:31",
"publication": "The Register",
"article-text": "Smart folks investigating a memory-dumping vulnerability in the Great Firewall\nof China (GFW) finally released their findings after probing it for years., The eight-strong team of security pros and academics found the data-leaking\nflaw, and started using it to learn about the GFW's inner workings in October\n2021. It named the flaw Wallbleed after the Heartbleed disaster in OpenSSL., To clear things up right from the start, this is no Heartbleed\n[https://www.theregister.com/2014/04/09/heartbleed_explained/]. Yes, it's a\nmemory-leaking bug, specifically an out-of-bounds read, but the team was only\nable to get it to reveal up to 125 bytes from the firewall's equipment.\nWallbleed is not something that can be used to unearth the deepest secrets\nlocked up by the Middle Kingdom but still… finding a bug in the GFW is a pretty\ncool thing., The GFW is Beijing's method for censoring internet content\n[https://www.theregister.com/2023/07/17/great_firewall_even_greater/] that flows\ninto China. The project began in the late nineties and has become more complex\nas the years have rolled by. Its primary purpose is to block Chinese citizens\nfrom visiting certain foreign websites and to slow the permitted internet\ntraffic that flows between China and foreign countries. It employs various\ntechniques to monitor netizens' online activities and censor their web of the\ninternet and wider world., Wallbleed is within the DNS injection subsystem of the GFW, which is responsible\nfor generating forged DNS responses when a user inside China tries to visit\nbanned websites. This subsystem lives in a fleet of government-operated machines\nat China's network border, watching for DNS queries., When a citizen tries to go to a verboten site, their device requests via DNS the\nIP address of the site's domain so that a connection to it can be established.\nThe GFW detects and intercepts this DNS query, and sends a DNS response back to\nthe user with a bogus IP address leading to nowhere. Thus, as far as the user is\nconcerned, access is blocked., The vulnerability itself is triggered by a bug in China's DNS query parser that,\nunder specific conditions, unintentionally returns to the client up to 125 bytes\nof additional memory data in the forged response. To be more specific, the data\nis leaked from whatever machine is inspecting the DNS request to potentially\nblock. By carefully crafting a DNS query, you can grab 125 bytes of memory from\nthe censorship middlebox inspecting that query., The GFW has relied upon DNS injectors for its filtering for years; at least\nthree of them are running at once. However, as we said, it's not the only\nmeasure used. There are other subsystems operating so that even if a client was\nable to receive a correct DNS response, other measures would kick in and block\ntheir access., The researchers, collectively contributing to the Great Firewall Report project,\nsaid the Wallbleed vulnerability \"provides an unprecedented look at the GFW.\"\nYou can find all the technical details here\n[https://gfw.report/publications/ndss25/en/], released Tuesday this week., Various studies has been carried out on the GFW in the past, but the Great\nFirewall Report claims despite that, not much is known about the firewall's\nmiddleboxes and inner workings., For example, in 2010 one mystery Twitter account posted a one-line script\n[https://github.com/net4people/bbs/issues/25] which, until it was patched in\nNovember 2014, allowed researchers to see 122 bytes of GFW memory due to a DNS\n[https://www.theregister.com/2023/01/19/google_dns_queries/] flaw., The Great Firewall Report team said they were able to use Wallbleed to extract\nplain-text network traffic data, understand how long bytes remained in memory\n(usually between zero and five seconds), and make inferences about the GFW's CPU\narchitecture. It's x86_64., The team used a box at University of Massachusetts Amherst to continuously use\nWallbleed to monitor President Xi's censorship infrastructure between October\n2021 and March 2024. In doing so, it was able to see how the GFW was maintained,\nand observe two attempts to patch Wallbleed in September-October 2023 and March\n2024., Wallbleed v1 is referred to in the paper as the vulnerability before the first\npatch and Wallbleed v2 is the same bug that still allowed researchers to probe\nthe GFW using modified methods until March 2024 – when it was patched for good., The boffins said they were also able to deduce that the vulnerable middleboxes\nin the GFW were, as you might expect, capable of capturing traffic from hundreds\nof millions of IP addresses in China, confirming that traffic from across the\nentire country was handled by these vulnerable middleboxes., \"Wallbleed exemplifies that the harm censorship middleboxes impose on internet\nusers goes even beyond the direct, and designed, harm of censorship: It can\nseverely violate users' privacy and confidentiality,\" the paper concludes. ®",
"article-image": "https://regmedia.co.uk/2025/02/27/shutterstock_gwc.jpg"
}]
}
There were dozens of records provided back to the Main Agent, but this is all that it provided as a response: “Scattered Spider (also known as Muddled Libra) targeted a service provider. The specific sector of the service provider is not detailed in the provided information.”
I provided what I thought were clear instructions in the System Prompt for the Main Agent to guide it on how to process the data and construct its response:
Format your final output based on these instructions:
- Evaluate all retrieved data and use it to construct your response.
- Format the message to be compliance with Whatsapp’s messaging schema, using it to emphasize key points.
- Include emojis where relevant to improve readability
- Use short concise sentences with plain english while preserving technical accuracy
- Use Australian English for spelling, punctuation and grammar
- Provide structured responses that explain the answer, and include clickable links to the articles referenced, using footnote formatting.
I would’ve thought the Main Agent would be capable of parsing the json object and providing a response based on that. Do I need to be more explicit in defining the structure of the response and how to handle it? I already provided context on the field names in the prompt for the Main Agent, so I thought that’d be enough to understand the data and provide a response.
Sorry if these have obvious answers, I didn’t expect the Agent node to require this much structure and direction - or am I just not using it properly…?