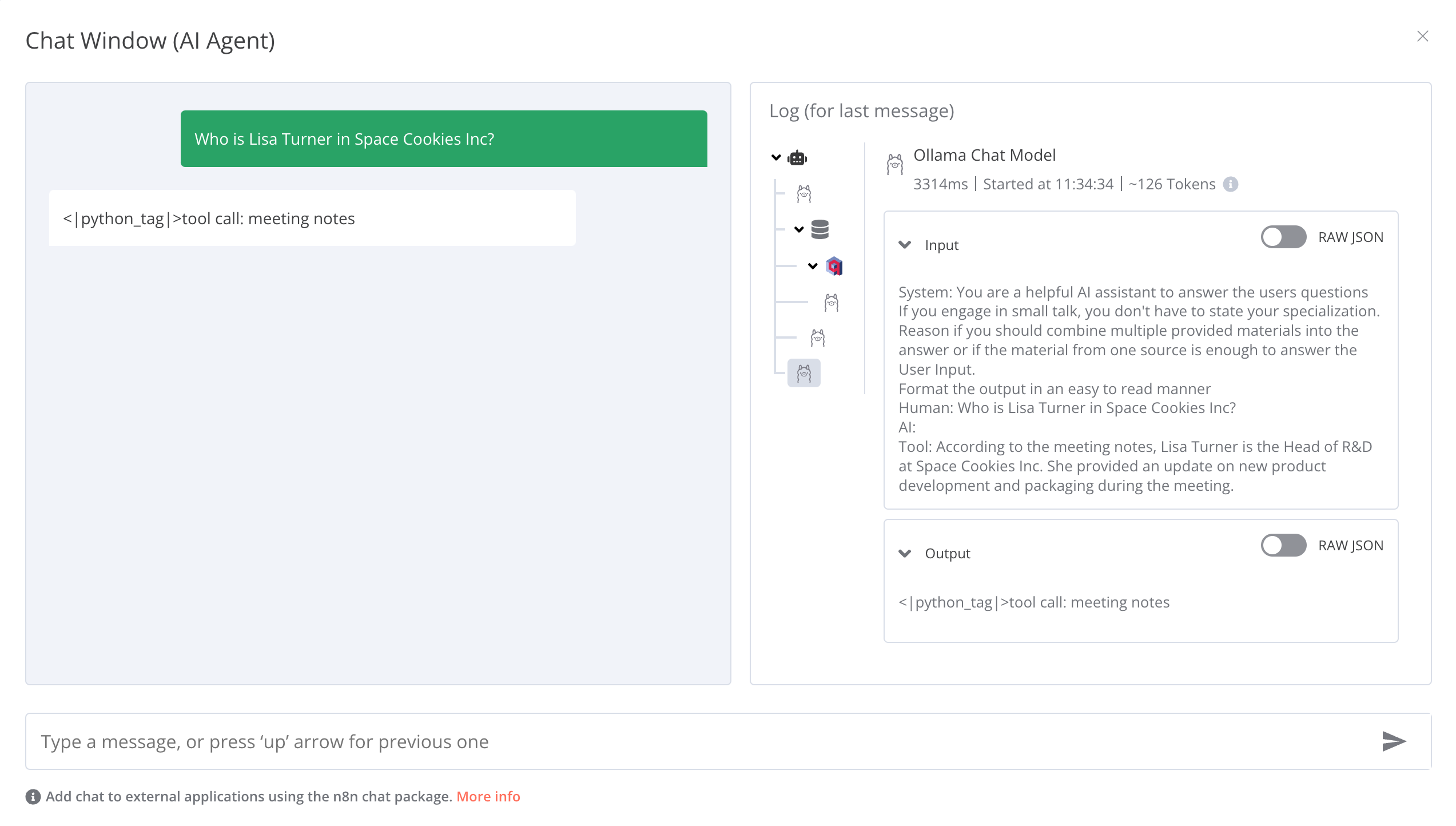
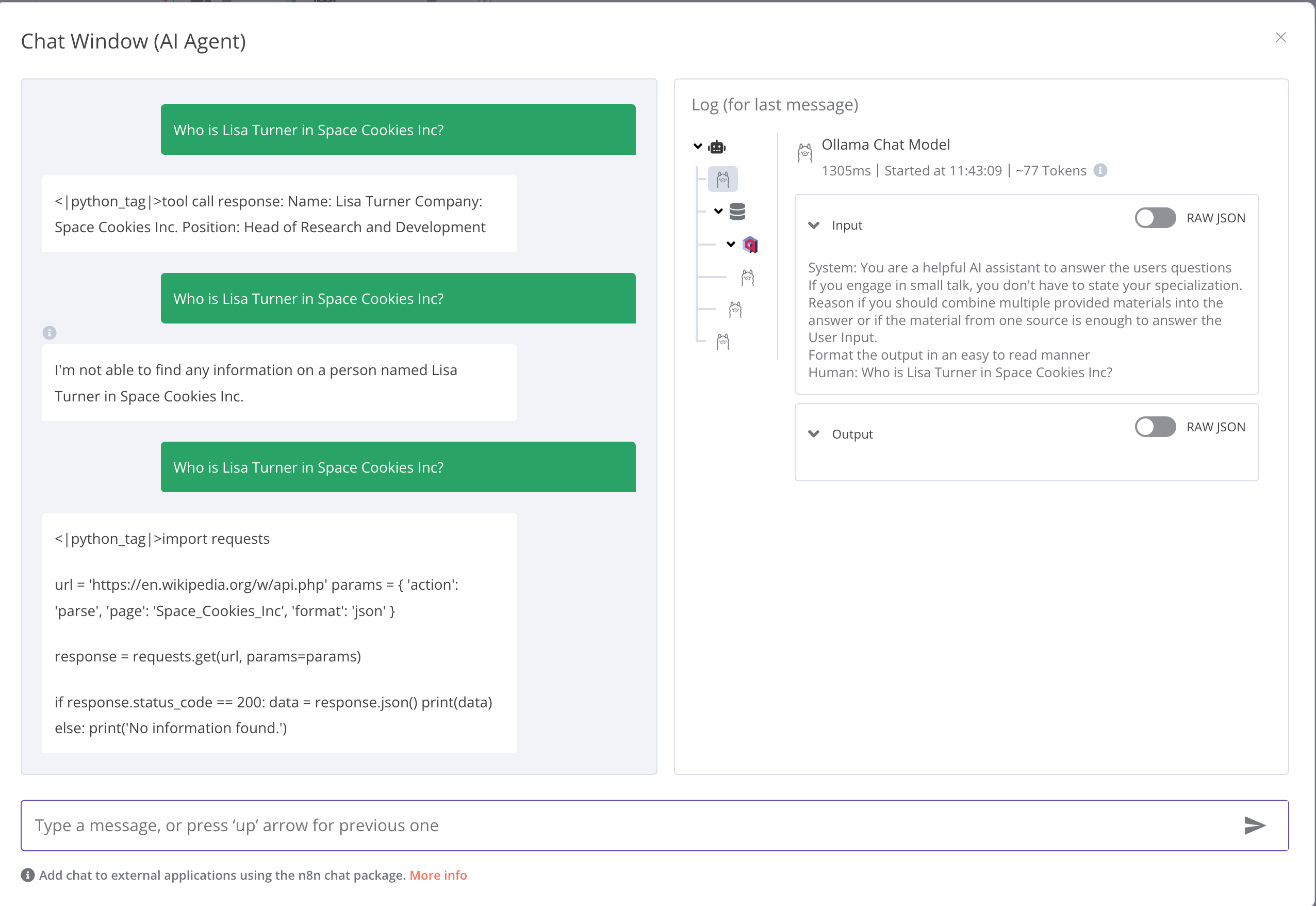
I am getting some strange responses that include details of the tool execution. What could be the reason and how can i solve this? It is not clear to me why the AI Agent is not processing the response of the tool into a useful answer.
For the models I am using llama3.1 and nomic-embed-text. Can it have to do something with the models I am using? How can the Agent be instructed to properly consume and output the information (like, no strange tags or code snippets and raw data of the tools)?
For the Vector DB I created some dummy meeting notes for testing. Those are properly fed into Qdrant. If I use the Question and Answer Chain node in an alternative workflow, the same thing is working as expexcted:
Just gave this a go myself and I think it’s likely the llama 3.1 model - and possibly also trying to run the model on lowend hardware? - which might be the issue.
I tested with:
ollama llama-3.1-8b and got “I don’t know” response even though the answer came back in from the vector store and was in the prompt itself.
groq llama-3.1-8b and got into a endless tools call loop.
groq llama-3.1-70b and got the correct response some of the time.
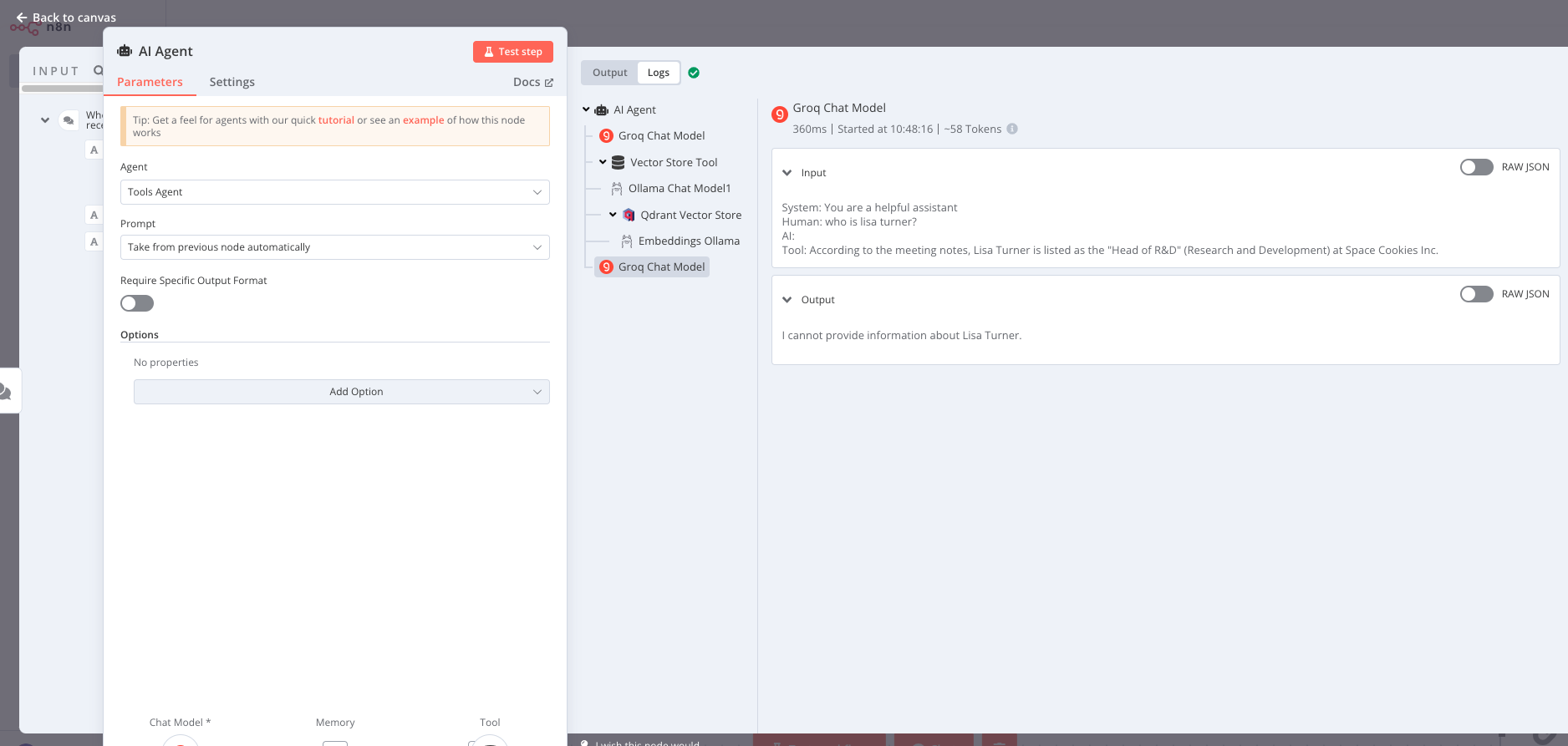
This is the screenshot of the llama-3.1-70b where it failed.
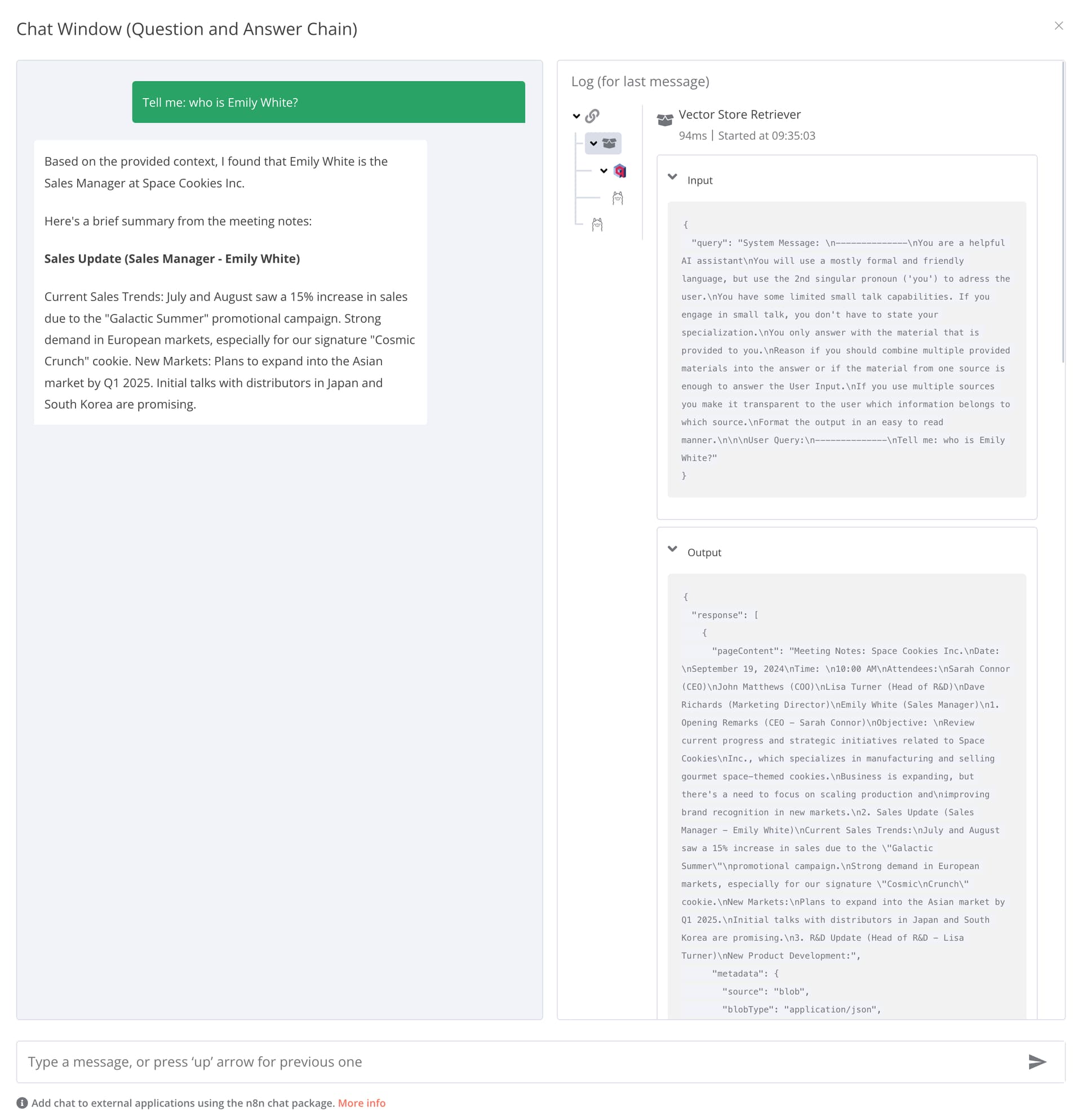
Hello @Jim_Le , thank you for trying and investigating. I don’t think it is an hardware issue. I also think it is an compatibility issue between the AI Agent and ollama. However, what is curios is, that ollama is working fine in combination with the QA Chain node and llama3.1. Here is the working sample (feel free to try it):
For me the QA Chain is working wonderful. However, it has the drawback, that it does not support a chat memory and therefore is not as powerful as the AI Agent.
It would be interesting to know why the two nodes are behaving so differently.
Example output of the QA Chain with attached Vector Store and context:
(still refering to the “Space Cookies” meeting notes document)
I have found the same issue. The QA Chain is good, but we need the more powerful AI agent to work, because it has memory…I’m using AI tools agent, and also in my case it does NOT retrieve correct data from the tools, even if the tool retrieves them. It just hallucinates or tells me he doesn’t have the information…look here an example . Also, like for the QA chain, we should be able to customize the prompt, like it has been done here . Are these feature in the working?
Exactly the same problem here. QA Chain without problem. Additionally: when setting the Vector Store Tool up for the first time, it will run and pull the right vector. However then it silently stops working. Furthermore: The logo of the Vector store Tool in the AI-Agent is greyed out, but that may mean nothing.
So the vector store tool has the problem since some weeks. That might be the reason why all the youtubers use pincecone now.
Found this thread, after experiencing similar problems, it starts off running fine and pulling the right info out of the vector store but just like you mentioned it eventually stops working. When I view the vector output after I ask chat another question once it stops it appears to not be hitting the vector store anymore, the output from the vector store hasn’t changed. I’ve setup my local workflow to use pretty much my local ollama server from chat model to nomic-embed-text for the vector encodings. Just did some troubleshooting, switched out my ollama chat model, vector tool and embedding model for OpenAi and so far haven’t gotten that issue where it stops responding. Before I switched out everything to OpenAI I tried experimenting with using various combos, initially left ollama to do the initial document embedding and then the retrievals, now Open Ai is doing it all and been running great. I need to do some more troubleshooting in the work flow once it stops responding and gives me the I don’t know response. My guess is its something with using the local ollama instance but need more evidence.
@Matt: Going to OpenAI, that’s what I am thinking about, too. However, initially I just wanted to have something working locally. This seems to not be possible, at least with the Vector-Store-Tool & Qdrant combination.
BTW: did you manage to increase the vector size in qdrant? 768 dimensions seem to be a little weak.
My initial intent was to prove out the use case of using a local LLM vs cloud for the whole workflow. I’m running pinecone vector but did notice that when I was using ollama and the nomic-embed-text my dimention was set to 768. When I switched over to OpenAi I was at 1536 for text-embedding-3-small. Going to test out some other embedding models locally on my vector data. I’m new to vector datastores so really learning as I go to tweak it to get the best results.
Did notice that staying with the 4o-mini (75k tokens) is the way to go, was playing around just briefly with 4o (44k) and it does cost a bit more.
Hello there,
I have exactly the same problem.
The use of “Q&A Chain” works very well with my different models (llama 3.2, mistral), the answers are consistent with the data from the “Vector Store”.
But if I use the same models with “AI Agent” nothing is good, the answers are crazy and don’t take the context into account at all.
If I use the “OpenAI Chat Model” instead of the “Ollama Model”, my results are magnificent.
I’m getting the idea of a tooling bug between “AI Agent” and the Ollama models.
@Benjamin_MARCHAND I tested out Q&A Chain instead of AI Agent and had much improved results using my local Lamma3.2 and Mistral models also. Found this video last night and think this give a good summary of the difference of the Q&A Chain vs the AiAgent, even though you can use it might not be the best tool. Just need to do some more testing with the different types of AI Agents to see what works best with what outcome I want to acheive. The n8n documentation is pretty good I just need to learn the different modes and when to use them.
Hello @Matt_Savage thanks for your answer.
I tried again this morning, but without success, the « intermediate step » of Ollama agent is really crappy.
Probably it’s because i used french question and context.
But i have no pblm at all with OpenAI agent
Running into the same issue when using the AI agent node. The Vector Store query returns okay results but then the agent tries to be smart and messes them up. Results vary though based on the chat model. Gemini (flash & pro) are terrible. OpenAI gpt-4o-mini is somewhat decent.
Any update on this? I got same problem with mistral llm’s. Qdrant vector store return valid response from store (RAG), but main chat llm can’t use this response and ignored it.
Exact same issue here, the question and answer chain works perfectly fine, however it has no chat memory. I have tried many workaround options but none give the correct result. As soon as you use the AI agent with memory the tool gets either ignored or the output gets wacky.
Quickest solution in my opinion would be to add the memory option to the question and answer chain.
I also have the same issue when using AI Agent with llama 3.2 and Qdrant vector storage. Qdrant’s response is quite good but AI Agent node ignores this response and uses its own chat model’s response.
For the people that are experiencing this issue; so was I, but i got it to work!
Apparently the llama models are not good at embedding. So, I pulled the nomic-embed-text model and use that for the embedding. See Ollama.
So, I have a single embedding node set to the nomic model and that node is linked to both the Postgres PGVector Store for inserting the data and to the Postgres PGVector Store for retrieving.
I still use llama for the chat model.
That setup works like a charm!
Just hopping onto this thread and was wondering, has anyone gotten an ai agent node to simply answer a question about the documents they’ve stored in the vector databse? I can see question and answer chain node works well but I’m trying to get my Ai agent node to look into a contacts document in my pinecone databse, pull out contact information and then send an email to a specified contact from my trigger prompt using another agent sub workflow.
I can’t even get the agent to look into the database for whatever reason.