I’ve got a workflow that has 4 Airtable Triggers - at time, this and another workflow are returning this error message. We just recently migrated from a non cloud instance to n8n cloud due to some problems we were having were the encryption key for credentials was being lost or causing hassles we prefer not to deal with.
What can we do within the n8n cloud to avoid the DNS server returning an error?
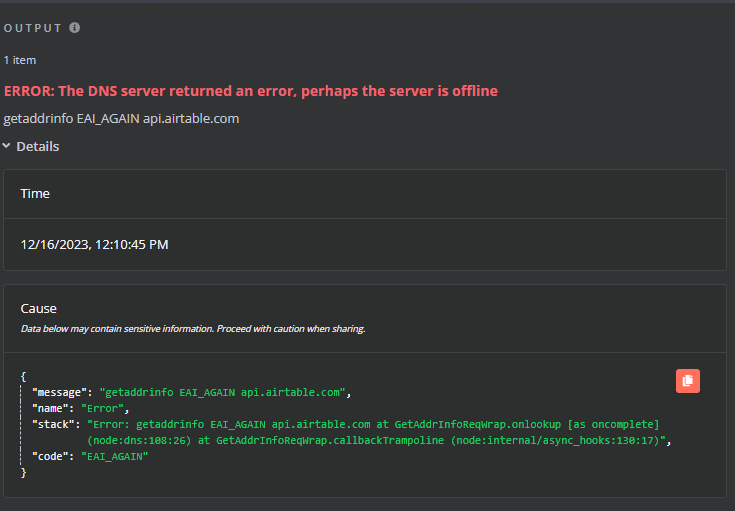
What is the error message (if any)?
{"message":"getaddrinfo EAI_AGAIN api.airtable.com","name":"Error","stack":"Error: getaddrinfo EAI_AGAIN api.airtable.com\n at GetAddrInfoReqWrap.onlookup [as oncomplete] (node:dns:108:26)\n at GetAddrInfoReqWrap.callbackTrampoline (node:internal/async_hooks:130:17)","code":"EAI_AGAIN"}
It doesn’t happen all the time, honestly I haven’t figured out a pattern on when this is happening. This would be the filtered view of executions on the issue. All the ones that say “Could not complete” are from the workflow that start using a Airtable Trigger
@manueltnc , the error clearly suggests “The DNS server returned an error, perhaps the server is offline”. There could be many reasons for “Could not complete”. I will name only a few
DNS resolver problem
DNS server misconfiguration
DNS records update that is still being propagated globally
Routing table issue
If this error persist for much longer and is only related to the node that queries Airtable API I would suggest contacting Airtable team to check that on their side. If they see no problem then it could be a networking issue within the cloud provider, which I believe is Azure, in which case n8n team might need to check with them. The route cause could be somewhere else in the network between the n8n server and Airtable API.
Hi @manueltnc, I am sorry for the trouble. @ihortom is pretty much spot on here.
One thing I have noticed is that Azure’s DNS resolver occasionally struggles when under a higher than usual load. Are you by any chance processing a larger number of items in each workflow execution? If so, every single one of these items would trigger a DNS lookup (unlike what you might see on a typical desktop machine, where the result of such a lookup would be cached for a while).
In such cases it can make sense to reduce the amount of items processed at once by introducing a Loop Over Items node to your workflow. You might also want to consider enabling the Retry options on the failing node so n8n simply retries the action before marking your execution as failed: