This is more of a question about how to approach a task. I’m trying to manipulate data on multiple SAAS platforms, creating consistency across our dataset.
In a shell script, I would pull all the data from all platforms, compare and create the output set, and then write the output to the platforms that need updating. Essentially, it would be a few calls to each to pull the data and a few to each to write the updated data.
n8n is making over 500 calls to several services in less than a minute. This causes some services to complain about too many API calls.
I’ve got to be missing something here. I’m probably doing this in the least efficient manner.
Any guidance or documentation, or should I find another method?
This all depends on your workflow and I suspect the issue could be how we loop items in the nodes. So if your first node was a get all to a cloud service and that returns 100 items the next node would then run 100 times so if you were say doing a get all on that second node you are getting all of the items 100 times so the next node would then loop once for each of those items but also for the 100 executions of the node as well.
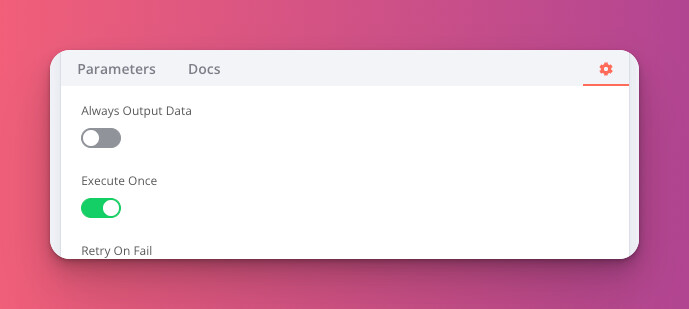
To work around this we have an option in the node settings so you can tell a node to only run once no matter how many input items there are.
By using this you will be able to run multiple “get all” operations in a row without worrying about the growing number of API calls.
This can be a bit different if you need to use data from a previous node to build a query though and that is where the workflow design might need some tweaking.
Let me know if this helps at all, If it doesn’t feel free to share a sample of your workflow and we can take a quick look.
I may be approaching this incorrectly. I have taken a different tact. It seems to be working.
My method is now to gather the data from the webservices, then process that data on the n8n node. Then, if needed, I will make a few API calls to correct any issues.