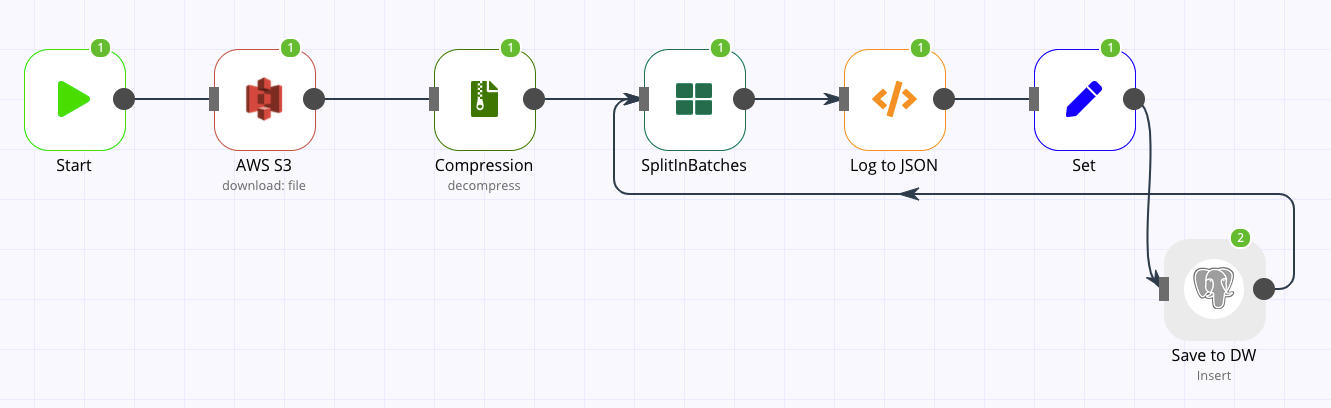
Hi there,
I’m building a workflow to push S3 logs into a Postgres, those logs are originated by another system, compressed and uploaded to S3 using this pattern: s3://bucket/YYYY/MM/DD/file.gz
Example: s3://tracking-data/web/2021/01/15/1610741019847.gz
I couldn’t find a way to specify which folder to list get All neither download a specific file, is there a way to specify files and or folders for GetAll operations?
If I point to one specific file on S3 root directory, the workflow works perfectly, but log files comes on partitions. BTW, thanks for the Compression node, it solved de .gz part neatly 
Thanks
I couldn’t find a way to specify which folder to list get All neither download a specific file, is there a way to specify files and or folders for GetAll operations?
Use the function file:getAll with the Folder Key option. For example, My bucket has the following structure s3://n8n/folder1/folder2/1.png. If I wanted to list all the files within folder2, the Bucket Name would be n8n and the Folder Key would be folder1/folder2/. The response will include a Key property. Use that key property to download the file using the function file:download.
Also, just saw the workflow and do not think the Split Batches node there is needed. Not sure what you want to do thought.
Thanks @RicardoE105! I’ll research further on my end, because the objects I uploaded using aws s3 cli aren’t visible to this node, just those I’ve created using the s3 node.
I’ll get back when I understand why this is happening, to help let the solution properly documented.
Yes, it doesn’t make sense on this current workflow I added it when I had several files on the pipeline and because the log files can be large, n8n was throwing memory exceptions.
I intend to publish my final workflow, it may be useful to others, once it is a pretty generic use case.
4 Likes
Hey @arjones!
Were you able to find a solution? It would be amazing if you can share it with the community
Hi @harshil1712,
I wasn’t able to make it work, I decided to switch to another approach, using Google Drive node. Sorry
1 Like
If you want, you can always provide a loom video showing where the issue/error is happening.
Thanks for letting me know. As Ricardo, you can always send more information for us to take a look at