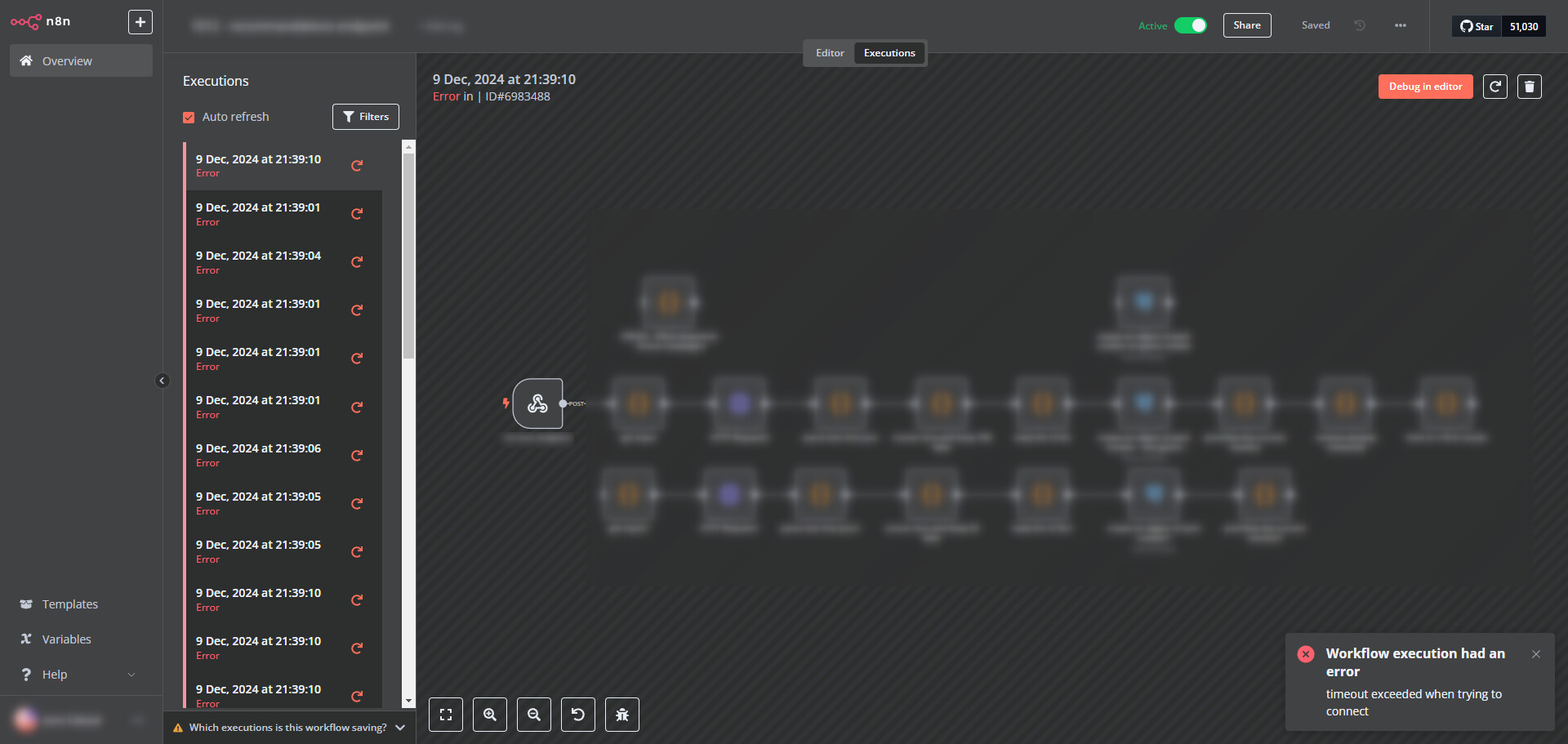
The error in the interface is: “timeout exceeded when trying to connect” and our main application (server) is logging “Failed to retrieve live execution rows in Postgres” on Cloudwatch.
It seems these error exectuions “are not real executions”, meaning the webhook isn’t really called, because when there’s a real call, the executions are successful.
Information on your n8n setup
n8n version: → 1.70.3 (we also had this error on 1.68.1)
the executions history for these errors doesn’t take new workflow edits into account: it displays the workflow state as it was when the error started
it doesn’t seem to impact new workflows containing webhook created since
=> So it seems we can fix it by recreating workflows that are impacted. But they are quite a few in my case and it doesn’t mean it won’t happen again, understanding the reason will definitely help
Hi @ria, here are our ECS Task parameters related to how our n8n instance runs.
We have 2 workers.
We did not make any change we this issue occured, though it happened just after our app restarted (main and workers).
Which version of n8n are you running on your instances?
You don’t seem to have any concurrency set. Can you try that? N8N_CONCURRENCY_PRODUCTION_LIMIT = maybe start with something like 20
Also, a few other notes on your variables:
Are you using any webhook processors? What’s the reason you’re having N8N_DISABLE_PRODUCTION_MAIN_PROCESS set?
I didn’t notice the execution IDs for these failing executions were again and again the wihtin the same limited list, meaning there were retries, for some reason.