I’m using the BETA version of N8N.io and I’m implementing the Retrieval Q&A Chain. When connecting the Supabase: Load node as the vector store retriever:
If the table name is not “documents” it throws an error “ERROR: Error searching for documents: 42P01 relation “documents” does not exist null”.
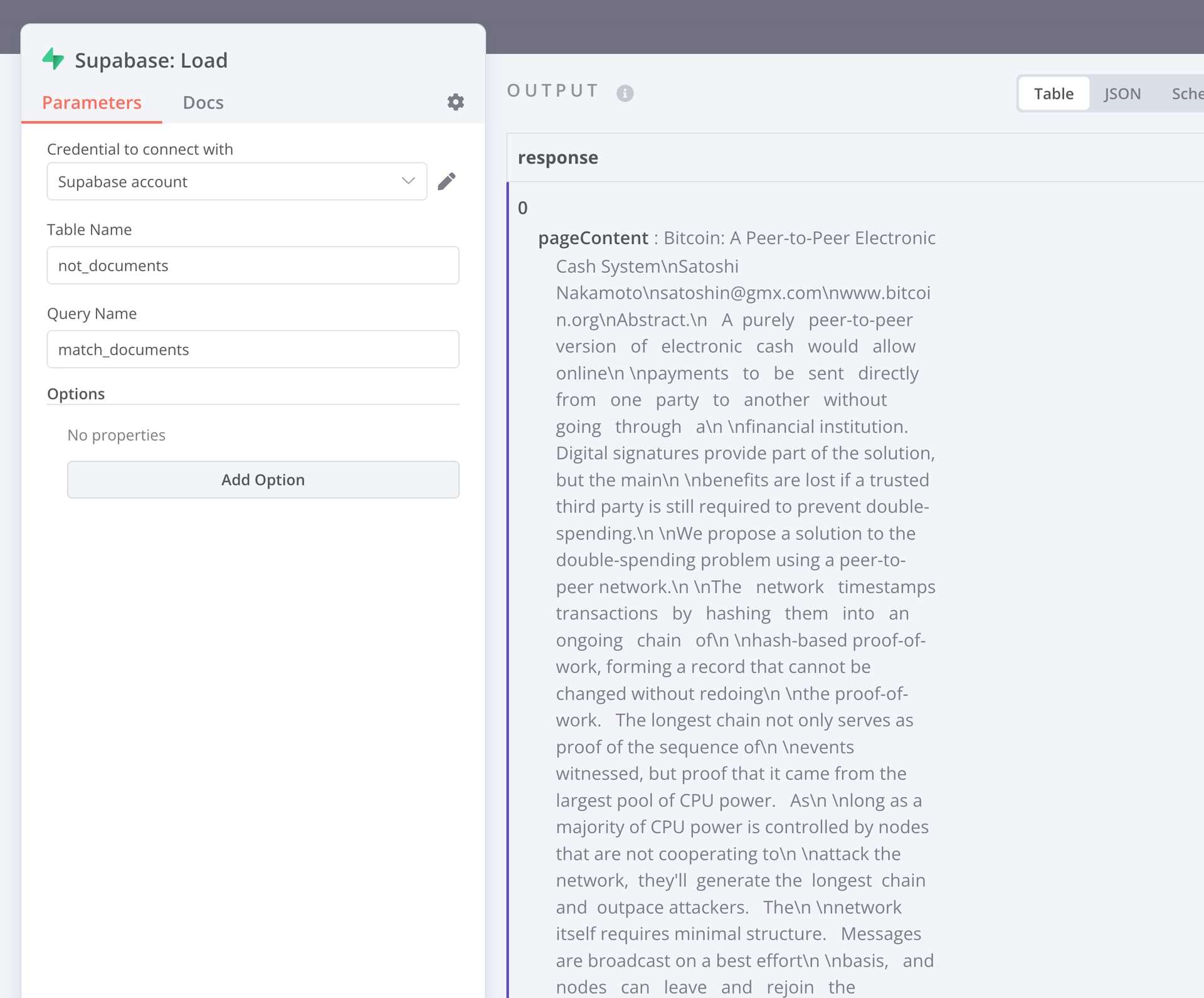
Even though I have set the table name correctly in the node’s Table Name input field, it seems to ignore that value, and looks for “documents” as default.
If I change the table name to “documents” in Supabase, it works.
@James_Pardoe Are you sure you’ve correctly updated the database name in the initial query to set-up the Supabase db? I just tried with not_documents and it worked for me as expected. I followed this Supabase docs: LangChain | Supabase Docs and replaced documents with not_documents. So the final query:
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table not_documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector(1536),
match_count int default null,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (not_documents.embedding <=> query_embedding) as similarity
from not_documents
where metadata @> filter
order by not_documents.embedding <=> query_embedding
limit match_count;
end;
$$;
Setting it up like this, allows me to use Supabase: Load:
Ah, could that be it? I used the Supabase template query to create a new LangChain database, and it would have been the default ‘documents’ table name. I then manually renamed the table name.
I subsequently then renamed the table name in n8n to match.
Will try with your approach a bit later on and let you know how it goes.
It’s not just about the table name. What’s also important is the matching function which is used which I assume you didn’t update.
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector(1536),
match_count int default null,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;
You can see that in that function documents get referenced several times. So you would have to update that function as well.