I went ahead and also tried the local version wthout any changes and the Qdrant with BM25 ReRank seems to be not properly configured.
it says Query is not defined as an answer to the query
{
"query": "What is BTC?"
}
query is not defined
query is not defined
Error details
Other info
n8n version
1.62.4 (Self Hosted)
Time
10/11/2024, 3:03:31 PM
Error cause
{}
I tried to understand the code, but i dont get where is the input coming from and the query is obviously there
Update the vector dimensionality to 3072. To ensure the collection is created before inserting documents, add the following code at the beginning of your script:
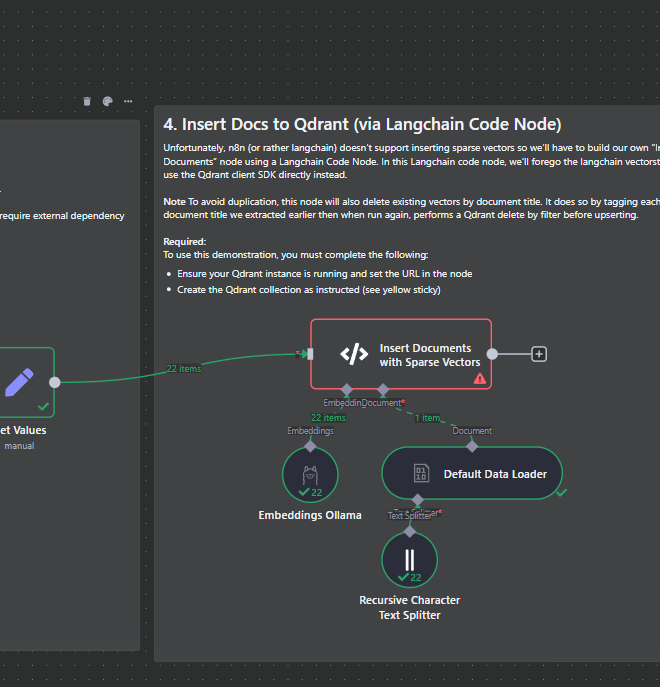
This is amazing! I learned so much about advanced use of n8n and sparse vectors from this. However, I suspect that there might be a bug.
Currently, the vocabulary for sparse vectors is dynamically generated per item using TfidfVectorizer, which results in inconsistent vector spaces across runs and may lead to misaligned vector representations. This is noticeable as each chunk has different number of indices.
I assume that it should build a shared vocabulary first.
Hello Jim! Thank you so much for the article! This content is not only highly interesting to me but also fantastic! I am working on a project where I have actually encountered the issue of a lack of accuracy in some cases in my agents’ responses. I started studying techniques like RAG Fusion to try to improve the quality of the model’s responses, but I still need to understand how to implement this technique using n8n.
Can confirm. We update about every 3 or so versions and since then the workflow has been broken. We’re on 1.73.1 as of this moment.
I’ve tried to figure out the cause but did not find it. I can retrieve dense vectors by themselves and the generation of sparse vectors still works. However, retrieving a hybrid of sparse and dense does not work for me anymore. @Jim_Le Do you have any insight as to what might be happening here?
After a quick check, I’ve boiled it down to (and this is my best guess!)
Qdrant’s API has stricter schema validation
n8n’s “custom workflow tool” has been updated.
For context, I’m currently on and tested using 1.77.0 but this reply should still be relevant to 1.73.0 (I think).
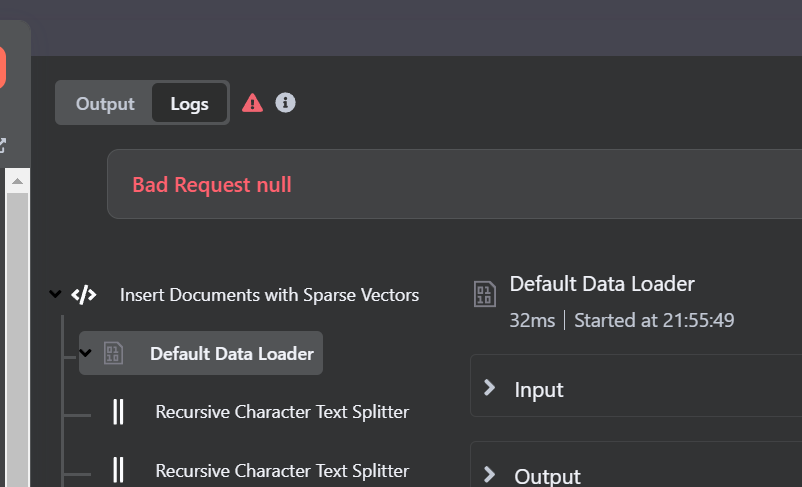
@Issa2024 Unfortunately, I wasn’t able to reproduce the error in your screenshot - my test document (bitcoin.pdf) was inserted into qdrant without issue. My assumption is it may have to do with your qdrant version and best advice is to try and debug the payload.
Try capturing a sample of the points and run this as a query within the qdrant dashboard. If there is an error, it’ll be clearer in the dashboard.
console.log(points.slice(0, 5)); // <-- use a sample output in the dashboard
Hi @Jim_Le, I have a quick question. I don’t know why the TF-IDF Node always crashes in my n8n, even with simple text. Does this happen to you as well?