For those with demanding RAG implementation needs or just curious about how to use sparse vector embeddings in their AI workflows, then this one’s for you!
Hey there I’m Jim and if you’ve enjoyed this article then please consider giving me a “like” and follow on Linkedin or X/Twitter. For more similar topics, check out my other AI posts in the forum.
Last week, Anthropic released an article titled “Introducing Contextual Retrieval” which explained a rather involved approach for producing better RAG results using a combination of contextual summary per chunk, creating sparse vectors and use of a reranker. The findings were intriguing - reducing retrieval failure rate by a whopping 49%! So intriguing in fact that I had to implement this for myself in n8n.
The Stack
Anthropic for LLM (Anthropic.com) Keeping on theme here since this template is inspired by their article.
Qdrant for Vector Store (Qdrant.tech) Qdrant remains my favourite vector store with support for advanced features like querying over sparse vectors and for having the best API offering.
Cohere for Embeddings and ReRanker (Cohere.com) One of the top AI service providers today which I feel people should use more. Their models are lightning fast with really easy to use APIs.
n8n for everything else! (n8n.io - sign up) n8n is low-key the best open secret when it comes to AI development tools. Though not strictly an entirely no-code solution, n8n offers the flexibility to extend by letting write my own custom langchain code - making something as ambitious as this template possible!
How It Works
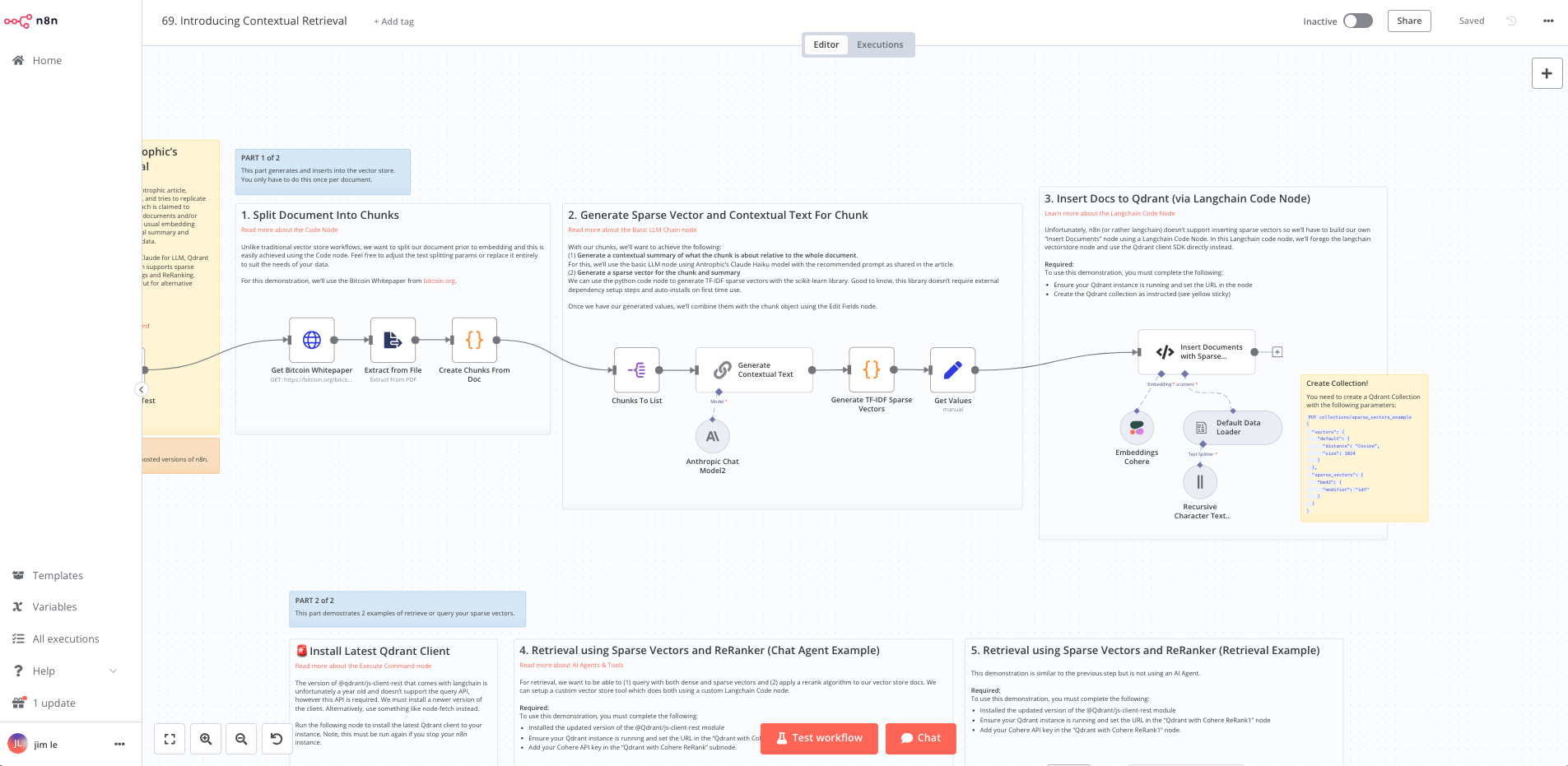
Generating the Vectors
Incoming document is text-split and chunked before upserting to vector store.
Each chunk is processed through the LLM prompt where a contextual summary is generated for the chunk in relation to the whole document.
Next, the chunk and it’s generated summary are used to generate a sparse vector using the ScikitLearn’s TFIDFVectorizer module to produce a sparse vector. This is achieved using the python code node (pyodide).
A Langchain Code Node (which allows for custom langchain code) is used to combine the chunk with its dense and sparse vectors and upsert this to our vector store.
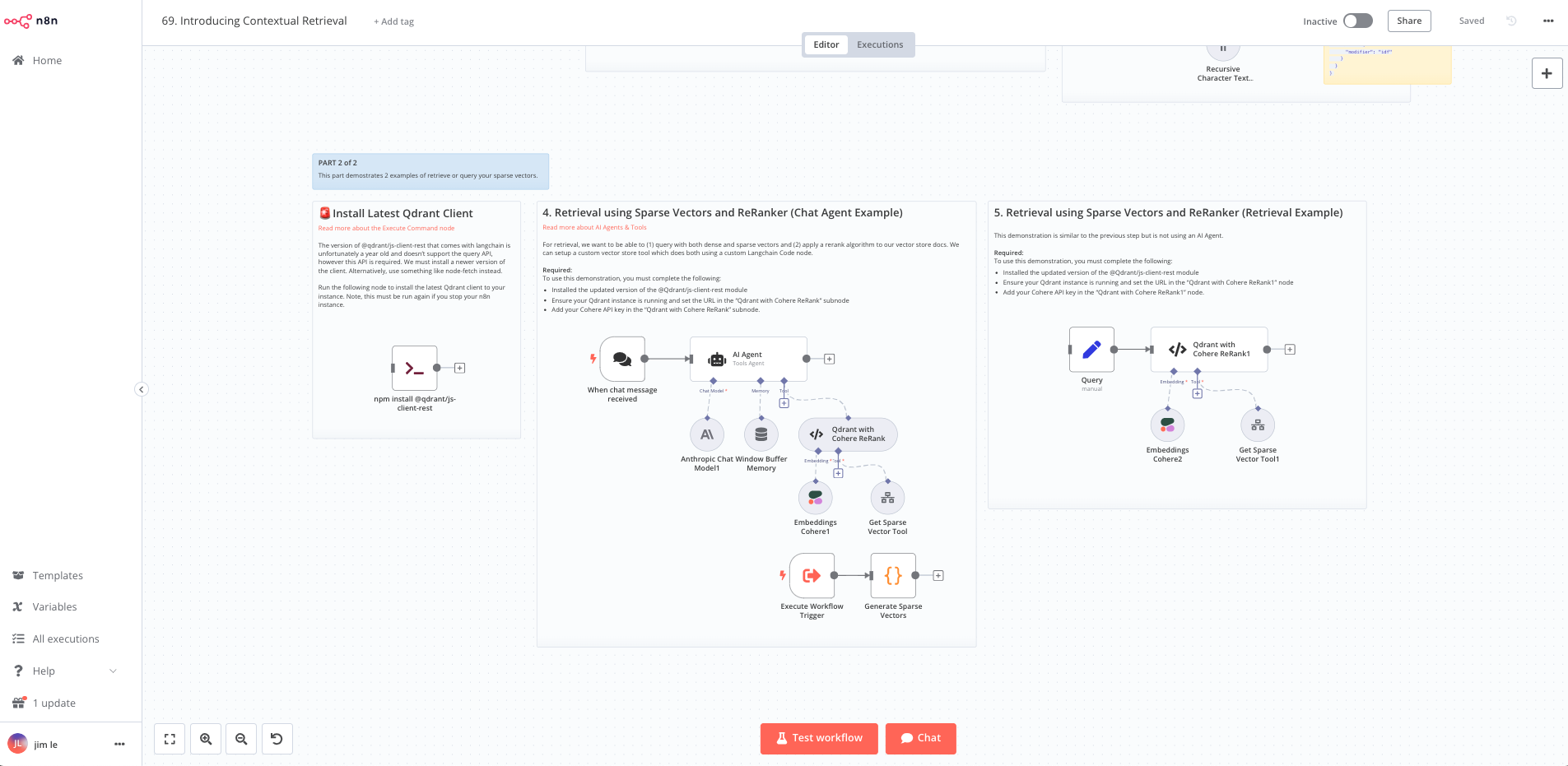
Querying the Vectors
The template includes 2 examples for retrieval; AI agent chat with a custom vector store tool and a non-chat example using a langchain code node.
The AI agent’s custom vector store tool simple handles generating the dense and sparse vectors for the user’s query and uses Qdrant’s Query API to combine both for the retrieval. An additional tool to calculate the sparse vectors is used (since this is done via python)
Once our vector store documents are returned, they are sent to Cohere’s Rerank service with our user’s query for re-ranking by relevance.
The final output is the same as if we were using the built in vector store tool so it’s good to know this can be easily integrated into existing workflows.
The Template
This template is released under the MIT licence - enjoy! Let me know if you’re building anything interesting with this or inspired by this.
Spot an issue? Leave a comment below and help me improve the template.
(Oops! I hit the character limit for the post - see the next comment for the actual template!)
So, is it actually worth the trouble? Probably! If your current RAG implementation isn’t performing as well as you’d like, this approach is definitely worth an investigation.
if you’ve enjoyed this article then please consider giving me a “like” and follow on Linkedin or X/Twitter. For more similar topics, check out my other AI posts in the forum.
This is the cyptography library which is used to generate a random uuid for each record upserted to the vector store. You’ll need to define the following environment variable to use (see docs here):
NODE_FUNCTION_ALLOW_BUILTIN=*
Alternatively, if you can find a different way to generate unique IDs for each record then that also works.
Can we replace cohere reranker API with a locally hosted model?
Copy the instruction as stated in the sticky note.
This will tell Qdrant to create a new collection called “sparse_vectors_example”. You can change this of course but you’ll also need to change all “collectionName” references in the template as well!
Been playing whole day long with the chain, testing prompts, and analyzing results.
It’s improved compared to the basic RAG but I feel like there’s too much context (chunk size 2000) being def for top K (20) to the LLM.
I got a few docs tested and it seems they seem to insert unrelated information when they explain OR reply with a “frankestein” answer that’s a mix of too much context and the final answer is unsatisfactory.
PROPOSED FIX (AND QUESTION):
How can I play with chunk size? I tried lowering it in “Create Chunks From Doc Node” —> const chunkSize = 800; const chunkOverlap = 100; AND Recursive Character Text Splitter → chunkSize = 130; const chunkOverlap = 200 BUT I get an error in the NODE: Insert Documents with Sparse Vectors —> ERROR: in the “Cannot read properties of undefined (reading ‘json’) [line 24]
TypeError”
LINE 24 is the following: bm42: inputData[i].json.sparse,
I got a few docs tested and it seems they seem to insert unrelated information when they explain OR reply with a “frankestein” answer that’s a mix of too much context and the final answer is unsatisfactory.
If you’re getting too much context, I’d suggest an easy fix is to just reduce the number of results to something more reasonable like 4 or 5?
The document loader text splitter chunk size (2000) is sort of misleading because the the chunks coming in will only ever be 1000 characters long due to prior chunking done by the code node.
Is FlashRank reranker local?
Yes - I believe I’ve already answered this question though maybe I’m misinterpreting?
heya @Jim_Le. Sending you a love bomb for this post. When I saw Anthropic’s post, I got excited and assumed it’d be a while before I could see those benefits. Then, bam, you posted this. Thank you.
Your post opened a rabbit hole of new n8n, LangChain, and RAGs knowledge. Having a reason to use play with Qdrant has been a nice bonus (I will use it more now).
I’m seeing improvements in retrieval similar to Antropic’s findings using your shared workflow. I’ve been refactoring the workflow to get it closer to an existing, actively used pre-processing/vector generation workflow and agent/querying workflow. There are no issues at all with the pre-processing. I’m struggling to integrate your custom elements here with the agent workflow.
A conflict has arisen with the ‘Execute Workflow Trigger’ used to kick off the ‘Generate Sparse Vectors’ code node, which is needed by the ‘Get Sparse Vector Tool’. My workflow relies on a ‘Execute Workflow Trigger’ to receive the user prompt. There can be only one.
Here’s where I hit the wall in my lack of knowledge. What are alternative ways to call the ‘Generate Sparse Vectors’ node? Could the ‘Get Sparse Vector Tool’ and ‘Generate Sparse Vectors’ be replaced with a ‘Code Tool’ sub-node?
Theoretically, yes we should be able to use the Code tool subnode but unfortunately at time of building this template with n8n v1.61.0, it didn’t work for me and I had to go the subworkflow approach. It’s kinda a bug with the Langchain code node… but then again, I don’t think the team would anticipate someone would use the node this way and fixing it is probably not high on the priority list! If it does get fixed in the future though, yeah definitely make this change.
In the meantime, to fix your issue there are 2 solutions I’d recommend:
(1) Use a separate workflow just for the get_sparse_vector tool instead of the same one as your agent. Seems kinda wasteful but it is is a perfectly acceptable thing to do!
(2) Use the slightly more complicated Router pattern for subworkflows. This approach uses the “Extra Workflow Inputs” field in the “custom workflow tool” to identify the intent of the trigger which can be picked up on the other side and redirected with a switch node (example below).
Downside is you will have to add the “route” field on all your other execute workflow nodes.
Hello @Jim_Le ,
Thanks for sharing your knowledge. I am storing a document (say version1). But then it got updated (version2). Now I want to store this updated info and perhaps delete the information from old doc in vector store. How to do it?
You can use Qdrant’s Delete API - see Delete points — Qdrant | API Reference - which allows you to delete by using a filter. Hopefully when you inserted your data the first time round, you added metadata using the data loader? If so, you can use the HTTP request node to do the following:
Just a heads up that next version of n8n (1.62.1) comes with an updated version of langchain which includes the BM25 Retriever. See BM25 | 🦜️🔗 Langchain. I think this could replace Cohere for local Rerank, though probably not as powerful?
And apologies for recommending FlashRerank, just now noticed it’s only for python and not JS.
Important: Requires n8n v1.62.1
I’ll update the template when 1.62.1 is promoted to latest.
Thank you @Jim_Le for your response. Yes, I added metadata like - file name (suppose RFP_v1.docx). If the file name is same, then I can filter and delete. But what if, when uploading the update version, I rename it to RFP_v2.docx. So the file name is different. In these situation, how to delete old info and keep the new info?
I have been trying to implement this myself. I’ve been trying to approach it my creating an sqlite db containing all the metadata for each file. Then when a file is added, undated, or deleted, the new metadata is compared to the previous state of the database. Any file changes are then labeled and passed to an if statement. But I am having an issue with the code to compare the 2 states and then labeling them properly. I am using @Jim_Le Build a Financial Documents Assistant using Qdrant and Mistral.ai as a starting point. Now I kind of want to switch to this sparse vector implementation and try and incorporate locally stored files.
Hey everyone, thanks for the continued interest in this topic. This will be my last update
Please see the updated 2nd post of this thread. The templates exceed the character limit for posts so I’ve uploaded them to google drive.
@Joy You would need to capture the title of the document instead of the filename in this case. I’ve updated the template to do just that and also handle the deleting of existing vectors before upsert. Enjoy!
@MFlo I played around with trying to get BGE-reranker working in n8n but it’s not as easy as it looks. There are quite a few dependencies to download so I’ll leave it to you to figure out I’ve uploaded a “local” version of the template with Ollama (llama3.2) and using the BM25 reranker as previously discussed.
@Khamblin Just a heads up this is an advanced implementation which benefits a few specific use-cases. It “should” be overkill and unnecessarily complex for a majority of people and I don’t recommend it if you’re just getting started into building a RAG system. Ideally, measure what results you get with the default tools in n8n (they’re really good as is!) and then extend out to sparse vectors to improve.
I am getting Bad rquest at inputting data to the Qdrant vecotr store
n8n version
1.62.4 (Self Hosted)
Stack trace
Error: Bad Request at Object.fun [as upsertPoints] (/usr/local/lib/node_modules/n8n/node_modules/@qdrant/openapi-typescript-fetch/dist/cjs/fetcher.js:172:23) at processTicksAndRejections (node:internal/process/task_queues:95:5) at QdrantClient.upsert (/usr/local/lib/node_modules/n8n/node_modules/@qdrant/js-client-rest/dist/cjs/qdrant-client.js:539:26)
The collection is created per the instruction. Can i add some debug to see why?
PS: normal QdrantVector store nodes work for me for storing and retriving.