I had a flow for creating long-form articles that I had built in Zapier using Claude 3.5 Sonnet, and which worked great. I rebuilt it in n8n, and everything worked, except the articles would suddenly end mid-sentence. There was no error, only a much shorter response that had clearly been clipped.
I have also tried some of the other models (such as Groq Llama 3.1 70b, which claims to have a token window of 131072. Yet if I try to set it to any more than 8000, I just get an error saying the max is 8000.
Does anyone have any idea why the artificial limits on many of the model token sizes, or why longer responses from Claude are getting cut off?
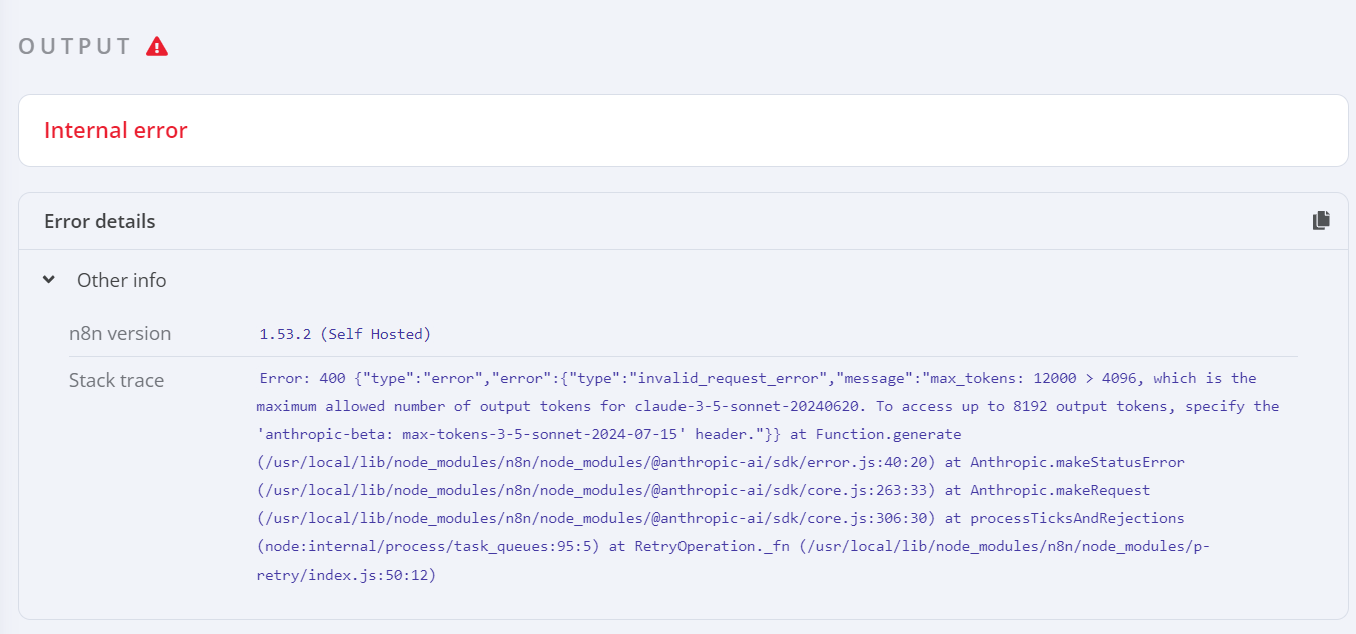
Looking at the code for the node we don’t appear to limit it and will use whatever input value you select in the override otherwise it should use the model default but just to check do you have a screenshot of the error you get when trying to set it to above 8000? It would be interested to see if it is coming from us or the API.
Loving the n8n concept, great job. Come a long way since I first tried it a few years back.
I don’t think it is the API, as I don’t have this issue running exactly the same flow, accounts and prompts etc using Zapier.
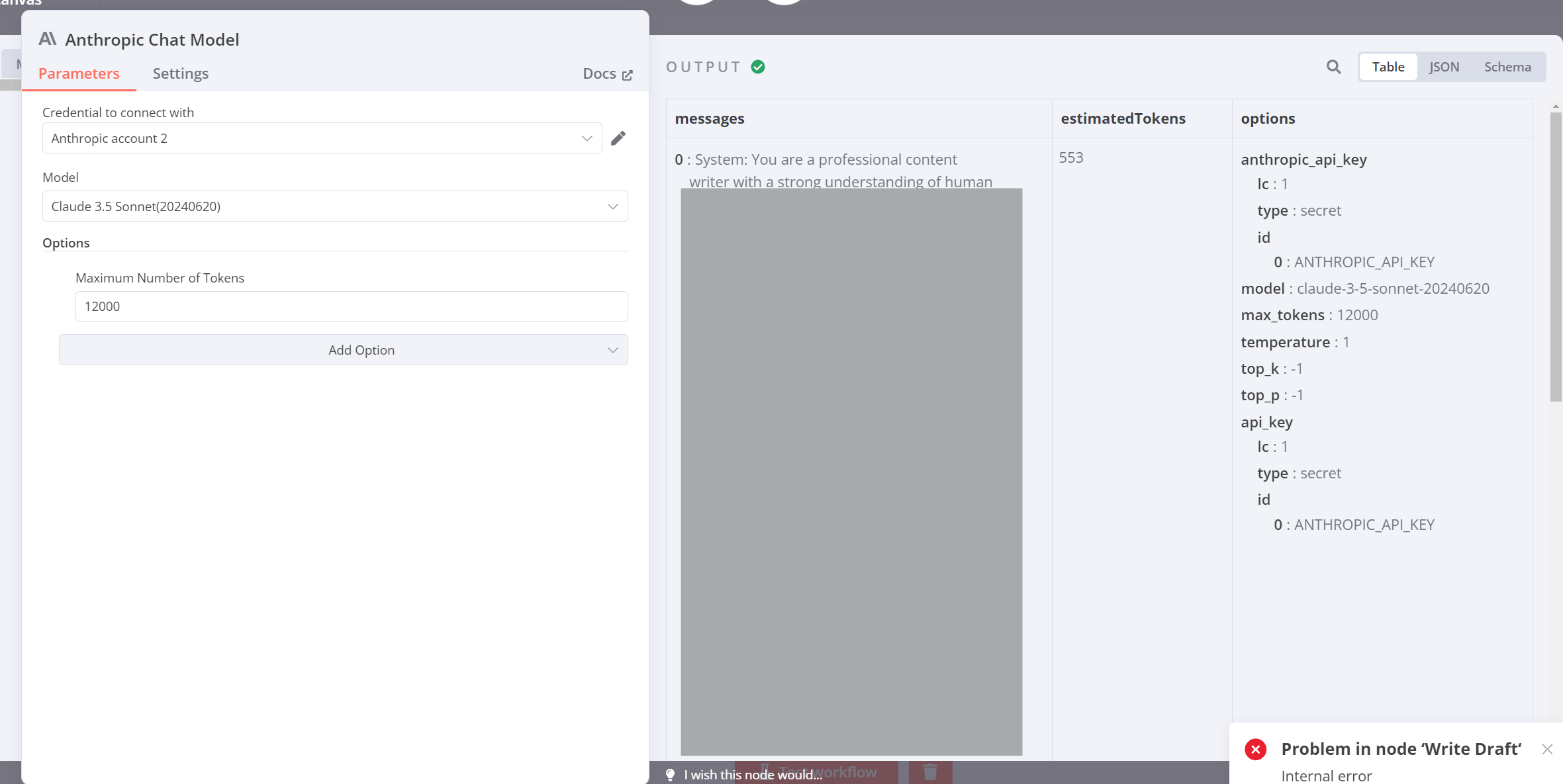
As you can see below, the text just cuts off mid-sentence. This is using the default token length (but even if there were not enough tokens, you would still expect it to finish its sentence within the limit)
That error is perfect, the api is returning the error message and saying that we need to include a special header for larger tokens. I will get a dev ticket opened for this in the morning
@Jon - appreciate all the recent fixes and new features. Is there anywhere to see a roadmap though of when the issue above may get resolved? Currently quite frustrating as I can’t use the flow as it is as the output keeps getting cut off, and my client is getting frustrated because they want it in production asap Would be helpful if I could give them more information on timeframes (and yes, I do appreciate the process of managing a large number of bugs and feature requests in a large web app, so again, thanks to the entire team for doing such a great job!)
Hi @Bart - not perfect, but I have found a work around for now. If you use OpenRouter (setup via an OpenAI node, just need to be sure to change the base URL in options), you can then choose Cluade 3.5 or any other large context model (eg Gemini) and it will work without cutting off.
OpenRouter.ai appear to charge almost the same rate as the models they provide, and allow you to test different models to find the best one for your use case without need multiple accounts etc., which is great while prototyping a build.
Once this bug is fixed though, I plan to switch back to where I needed Claude 3.5 for long context use