Bonjour à tous et merci pour cette section “Communauté française - n8n”.
J’utilise N8N dans un pod K8S, basé non pas sur l’image docker officielle n8n mais basée sur un node:alpine dans lequel j’installe n8n, les charts utilisés sont ceux officiels par contre (GitHub - 8gears/n8n-helm-chart: A Kubernetes Helm chart for n8n a Workflow Automation Tool. Easily automate tasks across different services.).
Il tourne avec une base PostgreSQL 14, et les ressources du pod N8N sont de 3Go de RAM et 2 cpu.
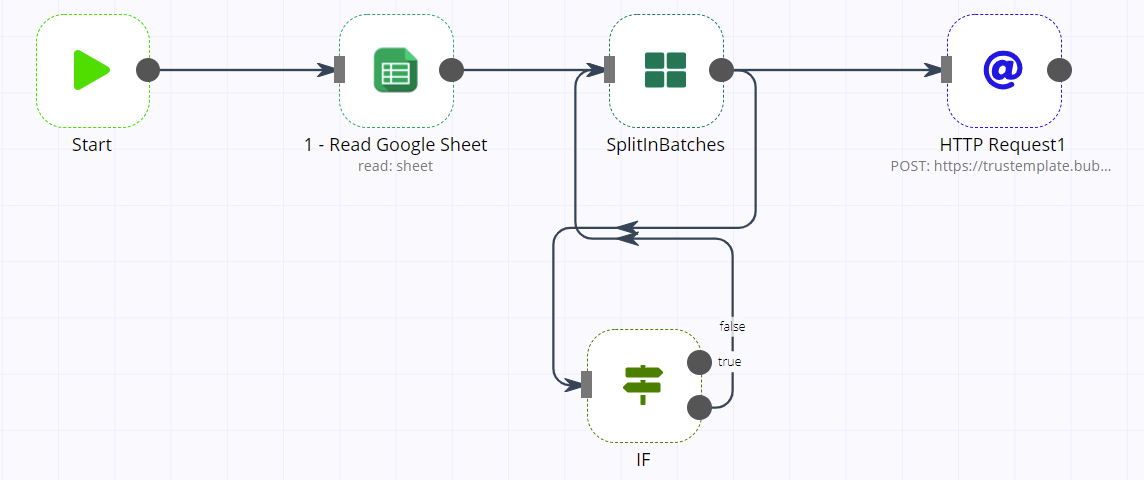
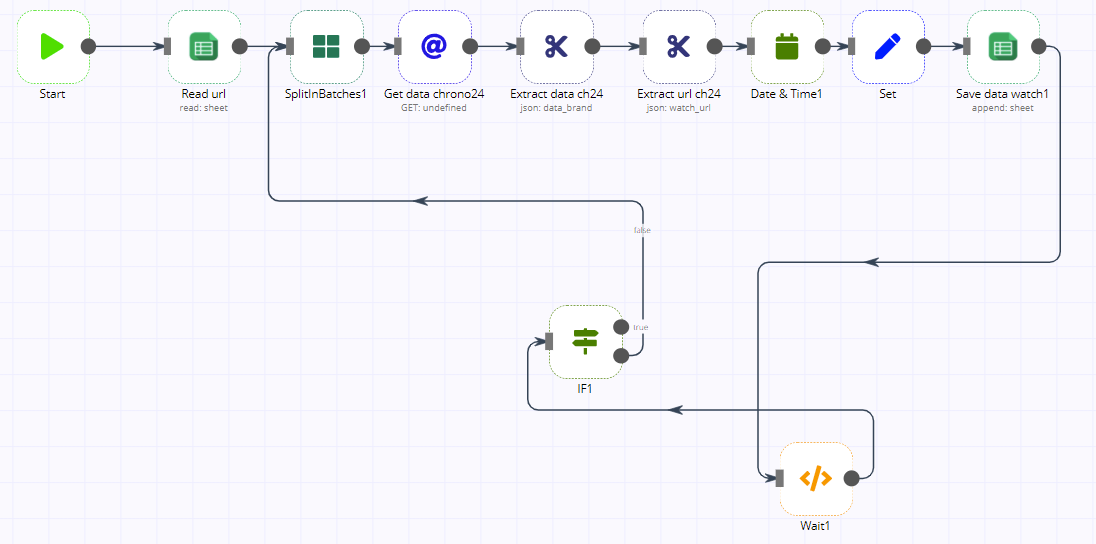
Voici mon souci, j’ai un workflow dont le but est de :
- vérifier toutes les minutes si un fichier CSV avec un certain nom est présent sur un serveur SFTP
- si c’est le cas le fichier est téléchargé, puis lu
- puis pour chaque ligne de ce csv je fais juste

un ajustement de format de date (ex : DD/MM/YYYY vers YYYY-MM-DD)
mettre des valeurs par défauts pour certains attributs pouvant être null dans le csv
et enfin appeler un Webservice pour enregistrer ces données
Mon souci est que cela fonctionne bien avec des petits fichiers CSV (ex: inférieurs à 5000 lignes) mais sur des plus gros volumes les workflows finissent toujours en erreur avec “unknown reason” au bout de 20 000 lignes traitées environ …
Au départ je voyais cette erreur dans les logs n8n :
<— Last few GCs —>
*[9991:0x7ff0f843e340] 7496627 ms: Scavenge 1526.1 (1558.2) → 1524.3 (1558.7) MB, 5.1 / 0.0 ms (average mu = 0.151, current mu = 0.122) allocation failure *
*[9991:0x7ff0f843e340] 7496638 ms: Scavenge 1526.6 (1558.7) → 1525.2 (1560.2) MB, 6.6 / 0.0 ms (average mu = 0.151, current mu = 0.122) allocation failure *
*[9991:0x7ff0f843e340] 7496648 ms: Scavenge 1528.0 (1560.2) → 1526.3 (1569.2) MB, 6.1 / 0.0 ms (average mu = 0.151, current mu = 0.122) allocation failure *
<— JS stacktrace —>
FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory
Subprocess for execution ID 161141 finished with error code null. {“executionId”:“161141”,“file”:“WorkflowRunner.js”}
Donc un problême de mémoire qui ne déclenchait même pas le Error Workflow.
J’ai fait pleins d’essais différents que ce soit sur les variables d’environements N8N (voir ci-dessous) ou sur de l’optimisation de mon workflow (ex : utilisation de SplitInBatches avec execution d’un sous-workflow, limiter au maximum l’utilisation des noeuds Function/FunctionItems etc…) mais rien y fait mes workflows finissent toujours en erreurs, à ceci près que dorénavant je n’ai plus l’erreur “Javascript heap space out of memory” mais que j’ai uniquement le message d’erreur null :
Subprocess for execution ID 161673 finished with error code null.
Voici la configuration de mes variables d’environnements pour N8N :
N8N_LOG_LEVEL: debug
N8N_METRICS: false
N8N_DEFAULT_BINARY_DATA_MODE: filesystem
N8N_USE_DEPRECATED_REQUEST_LIB: true
N8N_PAYLOAD_SIZE_MAX: 128
EXECUTIONS_DATA_SAVE_ON_PROGRESS: false
EXECUTIONS_DATA_SAVE_MANUAL_EXECUTIONS: true
EXECUTIONS_DATA_PRUNE: true
EXECUTIONS_DATA_MAX_AGE: 72
EXECUTIONS_TIMEOUT: -1
EXECUTIONS_TIMEOUT_MAX: 86400
GENERIC_TIMEZONE: Europe/Paris
TZ: Europe/Paris
EXECUTIONS_PROCESS: own
EXECUTIONS_MODE: regular
J’utilise N8N depuis plusieurs mois et je n’avais jamais rencontré de souci avant car les volumes de données étaient plus petits.
Je ne sais plus quoi faire pour que mes workflows ne finissent pas en erreur sur des gros volumes de données…
Merci d’avance à vous tous si vous voyez des incohérences dans les valeurs d’environnements de mon N8N ou d’autres choses à modifier.