This month, the n8n team and community experts will be ready to answer YOUR questions about using n8n & AI.
Our program will be:
Introduction to AI in n8n: We’ll explain how AI and LLMs can be integrated into workflows, highlighting their value in automation.
Live Demos: Next, we’ll walk through 2-3 pre-prepared workflows, covering key steps and how each component (LLMs, connectors, nodes) is used.
Q&A Segment: And finally, we’ll answer both pre-collected and live questions. For any question that needs an in-depth demo or explanation, please post it in a reply below!
Question:
How to make RAG reliable enough for production?
Background:
The largest issue currently preventing us from going from a POC to actually selling AI agents to companies is the unreliability of the second AI model who controls the actual vector database queries:
The issue:
A lot of times it works fine but if you run hundreds of evals you’ll start to see cases where the second AI model suggests an answer from it’s training data, sometimes it suggest contacting other companies in the area, it might suggest contacting customer service, etc.
When the answer from the second AI model is poor, the first AI model takes that as a fact as it’s coming from the tool call.
What we have tried already:
We use GPT-4o for both the first level AI agent and the second level model
We have sampling temperature set to 0,1
We have tried adjusting the FAQ document format and included loads of examples for correct way to say it doesn’t know the answer
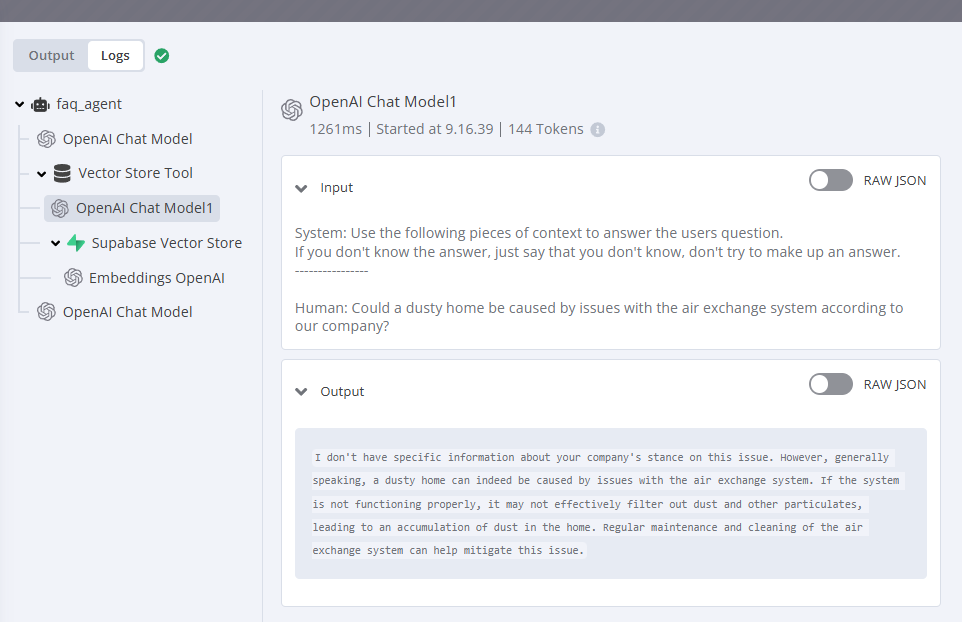
We have prompted the first level faq_agent to run the tool call multiple times if no answer is found but a single poor answer from the second model prevents this from working, e.g. the screenshot above.
We have prompted the first level faq_agent to format the queries with specific format that further suggests we are interested only in answers from the vector database, but this has limited success.
ps. if there is a way to control the prompt for the second level AI agent and I’ve missed it, please educate me as that would mostly solve this.
Hey team Some thoughts below… will update as I think of more!
1. LLM Tracing Improvements
Are there plans to improve the customisability of LLM tracing options in n8n? Currently as I understand it, the available tracing feature is based on Langsmith and set up at boot time via env vars. Could we say, explore setting tracing options or BYO? Ability to set tracing per workflow, conditionally set them per execution, add ability to add extra metadata during an execution etc
2. LLM & Agent nodes: Support for other Binary Types
As a big fan of multimodal LLMs, I would love for an easy way to send audio, video and even pdfs directly to LLMs without need for conversion. Would you consider building custom LLM nodes for the big AI service providers as to not be restricted by Langchain?
Example: Explore document processing capabilities with the Gemini API | Google AI for Developers
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key=$GOOGLE_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Can you add a few more lines to this poem?"},
{"file_data":{"mime_type": "application/pdf", "file_uri": '$file_uri'}}]
}]
}'
Sorry I will miss this. Nov 28th is Thanksgiving in the US when families get together and watch NFL Football and eat ourselves into a food coma! On top of that I have a double-whammy, it’s my wife’s birthday! That reminds me … I better get her a present.
Can you use OpenRouter.ai with an Agents so that you can choose different AI model easily. OpenRouter works great for workflows, but can’t seem to get it to work using AI Agents.
Looking forward. A few questions from building a RAG pipeline:
Using the AI Agent Node with a Structured Output Parser: does the LLM see the json schema and can thereby use it to answer the query with the right fields in the same way the LLM sees the JSON schema in the Information Extractor Node, or can it only call the structured output parser as a tool and get back a pass/fail?
Is there a way to convert a PDF to images in n8n cloud for use with multimodal RAG? The only I could find is to go through an external API…
Using a sub workflow execution as tool to retrieve document chunks and provide context to the LLM in an AI Agent node, what output format should the sub workflow have: text or is a JSON object also possible/recommended. E.g., a JSON holding the text chunk but also metadata, like page number, title, document name, etc.
What is the best way to handle “Overloaded” (e.g. Claude Sonnet) and/or Token limit errors from an LLM in the AI Agent node? A custom error output loop with a wait node will run forever without some kind of retry counter. The built-in retry won’t work when the LLM outputs the error as “normal” text output, and also will retry on every failure which does not make sense for most errors.