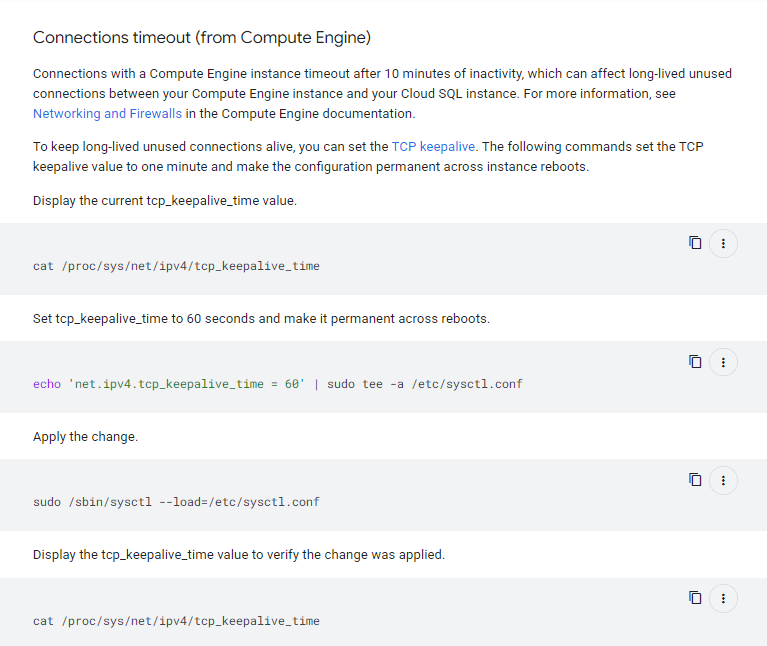
Describe the problem/error/question
We have hosted N8N using GCP CloudRun and Connection through CloudSQL. At some point the connection between those two got aborted resulting in “Database not ready” message.
Fortunately I enabled alerting with checking readiness, thus I got the message. It happened already second time. Redeploying CloudRun helped. But surely, it’s not a solution.
CloudRun runs with:
cpu_idle: false
Execution environment: Second Generation
Startup CPU Boost: true
2 CPUS, 4GiB memory
What is the error message (if any)?
“Database not ready”
DEBUG logs when it started happening:
DEFAULT 2026-02-12T09:47:17.368026Z 2026-02-12T09:47:17.367Z | debug | Querying database for waiting executions {“scopes”:[“waiting-executions”],“file”:“wait-tracker.js”,“function”:“getWaitingExecutions”}
INFO 2026-02-12T09:47:29.229227Z [httpRequest.requestMethod: GET] [httpRequest.status: 200] [httpRequest.responseSize: 193 B] [httpRequest.latency: 1 ms] [httpRequest.userAgent: GoogleStackdriverMonitoring-UptimeChecks(``https://cloud.google.com/monitoring``)] ``https://<n8n-url>/healthz/readiness
DEFAULT 2026-02-12T09:47:39.879757Z 2026/02/12 09:47:39 [db-name] connection aborted - error reading from instance: read tcp IP->DB_IP: read: connection reset by peer
DEFAULT 2026-02-12T09:47:39.880998Z 2026-02-12T09:47:39.880Z | error | Connection terminated unexpectedly {“file”:“error-reporter.js”,“function”:“defaultReport”}
DEFAULT 2026-02-12T09:47:39.881175Z 2026-02-12T09:47:39.880Z | error | Connection terminated unexpectedly {“file”:“error-reporter.js”,“function”:“defaultReport”}
DEFAULT 2026-02-12T09:47:46.882458Z 2026-02-12T09:47:46.881Z | warn | Database connection timed out {“file”:“db-connection.js”,“function”:“ping”}
ERROR 2026-02-12T09:47:46.947087Z [httpRequest.requestMethod: GET] [httpRequest.status: 503] [httpRequest.responseSize: 197 B] [httpRequest.latency: 1 ms] [httpRequest.userAgent: GoogleStackdriverMonitoring-UptimeChecks(``https://cloud.google.com/monitoring``)] ``https://<n8n-url>/healthz/readiness
DEFAULT 2026-02-12T09:47:53.883948Z 2026-02-12T09:47:53.883Z | warn | Database connection timed out {“file”:“db-connection.js”,“function”:“ping”}
Share the output returned by the last node
Information on your n8n setup
- n8n version: 2.7.3
- Database (default: SQLite): CloudSQL
- n8n EXECUTIONS_PROCESS setting (default: own, main): default
- Running n8n via (Docker, npm, n8n cloud, desktop app): CloudRun
- Operating system: GCP