Initializing n8n process
n8n ready on ::, port 5678
n8n Task Broker ready on 127.0.0.1, port 5679
Failed to start Python task runner in internal mode. because Python 3 is missing from this system. Launching a Python runner in internal mode is intended only for debugging and is not recommended for production. Users are encouraged to deploy in external mode. See: https://docs.n8n.io/hosting/configuration/task-runners/#setting-up-external-mode
[license SDK] Skipping renewal on init: license cert is not due for renewal
Registered runner "JS Task Runner" (VkVAkoh7lA58iPNtk0XNr)
Version: 2.16.2
Building workflow dependency index...
Start Active Workflows:
Activated workflow "workflow_name" (ID: workflow_id)
Editor is now accessible via:
http://home-server:3002
dbTime.getTime is not a function
dbTime.getTime is not a function
dbTime.getTime is not a function
dbTime.getTime is not a function
dbTime.getTime is not a function
What I tried so far
different n8n versions
reboot both client and server
disable firewall on both machines
use firefox and chrome
use inconito mode
disable browser’s extensions
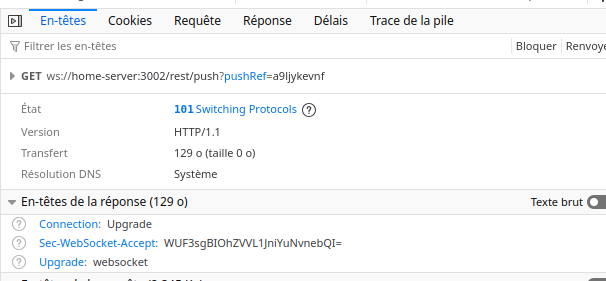
use N8N_PUSH_BACKEND=sse
Information on your n8n setup
n8n version: 2.16.2
Database (default: SQLite): PostgreSQL 17.9
n8n EXECUTIONS_PROCESS setting (default: own, main): not set
Running n8n via (Docker, npm, n8n cloud, desktop app): docker
@randoum that dbTime.getTime is not a function spamming your logs is the actual problem, it’s a confirmed bug in n8n with PostgreSQL — the clock repository returns a raw string instead of a Date object and it crashes the internal poller every few seconds, which kills your websocket connections. exec into your container with docker exec -it n8n sh and edit /usr/local/lib/node_modules/n8n/node_modules/@n8n/db/dist/repositories/clock.repository.js, find the postgres branch in getDbTime() and wrap the return value with new Date(), then restart the container. tracked here dbTime.getTime is not a function repeated in idle logs on n8n 2.16.1 · Issue #28640 · n8n-io/n8n · GitHub
@randoum your docker ps output shows 0.0.0.0:3002->3002/tcp and container name n8n_websites, but your docker run command maps -p 3002:5678 and names it n8n — that’s a completely different container. kill n8n_websites and make sure you’re running the docker command you actually posted, the port mapping mismatch (3002->3002 vs 3002->5678) would explain why WS drops after handshake.
The fact that N8N_PUSH_BACKEND=sse also didn’t help is a useful clue — if both WebSocket and SSE drop, it’s not protocol-specific but something in n8n’s push system itself. Worth verifying the dbTime fix actually survived: run docker exec n8n grep -c 'new Date' /usr/local/lib/node_modules/n8n/node_modules/@n8n/db/dist/repositories/clock.repository.js — if it returns 0, the edit got wiped (it’s lost on container restart). Also try N8N_LOG_LEVEL=debug and capture logs right at the moment the connection drops, that should surface whatever is actually triggering the disconnect.
Usually, ws stop working when you are reaching n8n container with a reverse proxy/load balancer. This extra infrastructure piece could contains time-out rules that are disconnecting you.
Can you please note if you are reaching your n8n container via a reverse proxy?
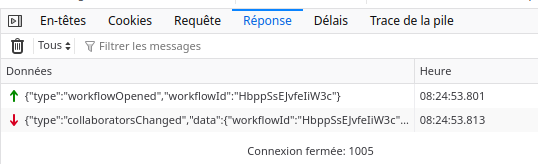
I’ve noticed something: the Connection Lost issue happens only when 2 or more browser’s tab are opened simultaneously. If only one is opened, there is no issue. That must be something, wdyt?
The fact that N8N_PUSH_BACKEND=sse also didn’t help is a useful clue — if both WebSocket and SSE drop, it’s not protocol-specific but something in n8n’s push system itself. Worth verifying the dbTime fix actually survived: run docker exec n8n grep -c 'new Date' /usr/local/lib/node_modules/n8n/node_modules/@n8n/db/dist/repositories/clock.repository.js — if it returns 0, the edit got wiped (it’s lost on container restart). Also try N8N_LOG_LEVEL=debug and capture logs right at the moment the connection drops, that should surface whatever is actually triggering the disconnect.
Hey. The changes did survived:
$ docker exec n8n_websites cat /usr/local/lib/node_modules/n8n/node_modules/@n8n/db/dist/repositories/clock.repository.js | grep -A 2 -B 2 "new Date"
if (this.databaseConfig.type === 'postgresdb') {
const [{ now }] = await this.dataSource.query('SELECT CURRENT_TIMESTAMP(3) AS now');
return new Date(now);
}
const [{ now }] = await this.dataSource.query("SELECT STRFTIME('%Y-%m-%dT%H:%M:%fZ', 'NOW') AS now");
const date = new Date(now);
if (Number.isNaN(date.getTime())) {
throw new n8n_workflow_1.UnexpectedError(`Invalid DB server time: ${now}`);
Usually, ws stop working when you are reaching n8n container with a reverse proxy/load balancer. This extra infrastructure piece could contains time-out rules that are disconnecting you.
Can you please note if you are reaching your n8n container via a reverse proxy?
Hi. No reverse proxy or LB, the set-up is straight forward:
Server running the docker container
Client on the same LAN accessing n8n using the server’s IP