Hello everyone,
I’m currently working on an interesting project using n8n and the OpenAI API, where I aim to generate a blog article. My concept involves using each subtitle as a basis for creating a paragraph in the blog post. To add a layer of complexity and refinement, I plan to use the output of each paragraph as an input for the next, essentially creating a recursive-like function for content generation.
However, I’m facing a challenge. I need to organize all the subtitles and their associated paragraphs effectively, but I’m struggling to create a large table or a JSON file that can neatly contain this paired data. I believe this step is crucial for maintaining the flow and coherence of the blog post.
Has anyone tackled a similar challenge or have any insights on how I could achieve this?
Looking forward to your suggestions and insights on this!
Thank you!
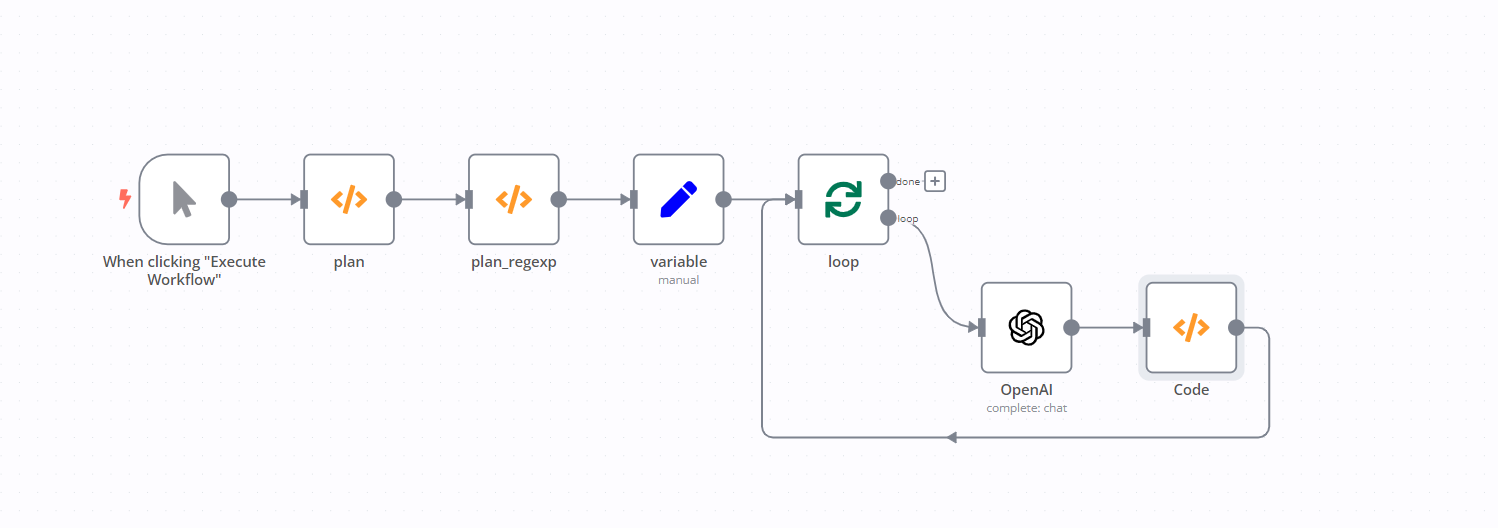
Information on my n8n setup
- n8n version: 1.11.2
- Running n8n via (Docker, npm, n8n cloud, desktop app):npm
- Operating system: Linux
