Hi everyone,
I am finalizing a Concierge App for a client and facing a critical stability issue I can’t seem to shake. The workflow logic is perfect, but the execution behavior is unstable.
![]() The Problem When I trigger the workflow once from my frontend (React), n8n starts 5 to 7 parallel executions for that single request. Even though I optimized the workflow down to ~10 seconds latency, these “ghost retries” keep happening, unnecessarily burning my API credits (OpenAI, etc.).
The Problem When I trigger the workflow once from my frontend (React), n8n starts 5 to 7 parallel executions for that single request. Even though I optimized the workflow down to ~10 seconds latency, these “ghost retries” keep happening, unnecessarily burning my API credits (OpenAI, etc.).
![]() The Stack
The Stack
-
Backend: n8n (Self-hosted).
-
Trigger: Webhook Node (Method:
POST, Response Mode:Using 'Respond to Webhook' Node). -
Frontend: React App (Bolt).
-
Workflow Logic: Google Sheets Lookup + LLM Analysis + JSON Response.
-
Current Execution Time: ~10 seconds (down from 20s after optimization).
![]() Troubleshooting Steps Already Taken
Troubleshooting Steps Already Taken
I initially thought it was a browser timeout issue, so I hardened both sides:
1. Frontend (React)
-
UI Blocking: The submit button is
disabledimmediately upon clicking (preventing double-clicks). -
Timeout Config: I explicitly set the
fetch/axiostimeout to 60,000ms (60s) to prevent the browser from cutting the connection prematurely. -
Network Tab: The browser shows “Pending” for the first request, but n8n logs show new executions starting at t+2s, t+5s, etc.
2. Backend (n8n)
-
Optimization: I fixed previous Google Sheets “Quota Exceeded” errors by using “Execute Once”. The workflow is now green and efficient.
-
Workflow Settings: I checked for loops, but the execution logs show distinct new IDs starting from the Webhook node.
![]() My Hypothesis & Question
My Hypothesis & Question
Since the workflow takes ~10s to reach the “Respond to Webhook” node, I suspect an infrastructure timeout layer is silently retrying the request because it doesn’t receive an immediate header.
-
Could this be my Reverse Proxy (Nginx/Traefik) configuration? Does n8n require specific Keep-Alive settings for long-polling webhooks?
-
Is there a way to make the Webhook “Idempotent”? (i.e., force n8n to ignore a request if an identical one is already processing).
-
Should I switch architecture? For a 10s delay, should I switch the Webhook to “Respond Immediately” and push the result back to the frontend via a separate mechanism?
Any guidance on how to stop these
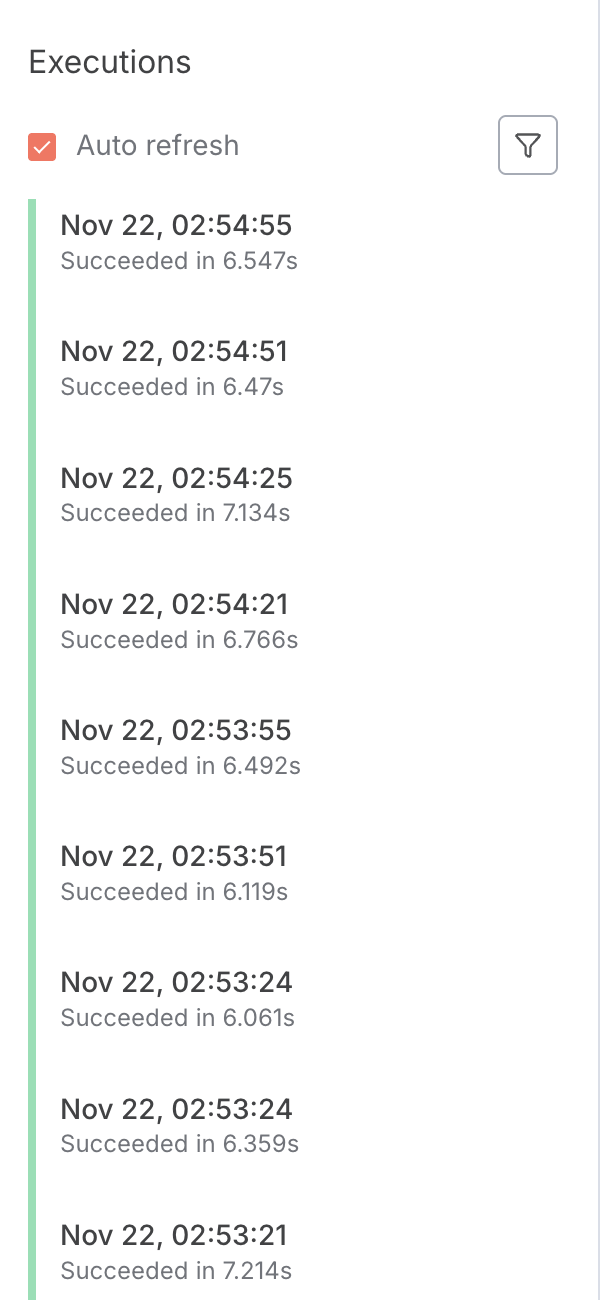
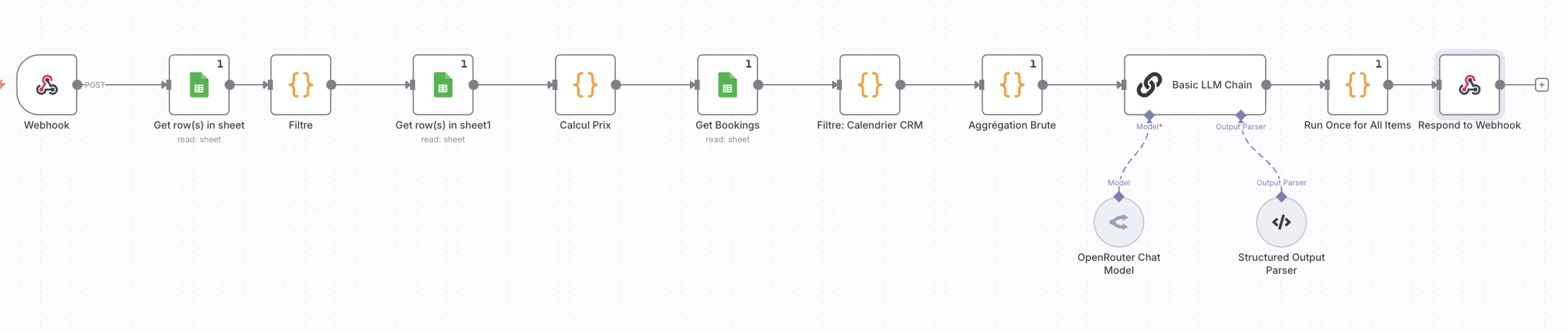
auto-retries would be a lifesaver. I am ready for production, but this is a blocker.
Thanks a lot for your help! ![]()