We have twenty cron jobs actively running at an interval of 5 to 9 mins each. We notice that these cron jobs fail at random intervals of a day. Sometimes it does not happen but sometimes it happens frequently. What is the best way to troubleshoot at which point of the workflow we receive the error?
Workflow setup is simple → Cron configured for every 5 minutes → postgreSQL node runs one delete Query and one insert query.
It does not throw any specific error message for now, it simply mentions that workflow has failed. Any pointers to understand how to configure the failure for the workflow will also help us.
Please share the workflow
Information on your n8n setup
n8n version:0.214.0
Database you’re using (default:PostgreSQL):
Running n8n with the execution process [own(default)]:
Do you already have execution logging enabled for your workflows? It might be worth checking the console output of n8n as well as it may show something there but I would probably start with an upgrade to see if that helps and maybe swapping from every X to Cron to see if that helps.
@Jon - appreciate the response, I will change the every X to Cron and see if this is getting mitigated.
The console log error often times say that it cannot connect to the DB, connection error. Is there an expected issue in the connectivity of running N8N in the docker? vs. Running N8N as NPM?
Thanks for sharing the log details @Leandro_Hoffmann.
I tried changing the expression from using every x to corn job expression as you suggested @Jon but it did not work. So any suggestions is much appreciated.
That error looks unrelated to the postgres node, Is there more to the workflow that has not been shared? I would expect that error to appear if you were maybe working with files.
@Leandro_Hoffmann I wouldn’t expect that workflow to cause that error, During your investigation what led to you finding that line and linking it to that workflow? I can’t see anything in the flow that would cause that.
When the workflow fails what does the workflow execution log say? If it is failing there should be something for that in the UI.
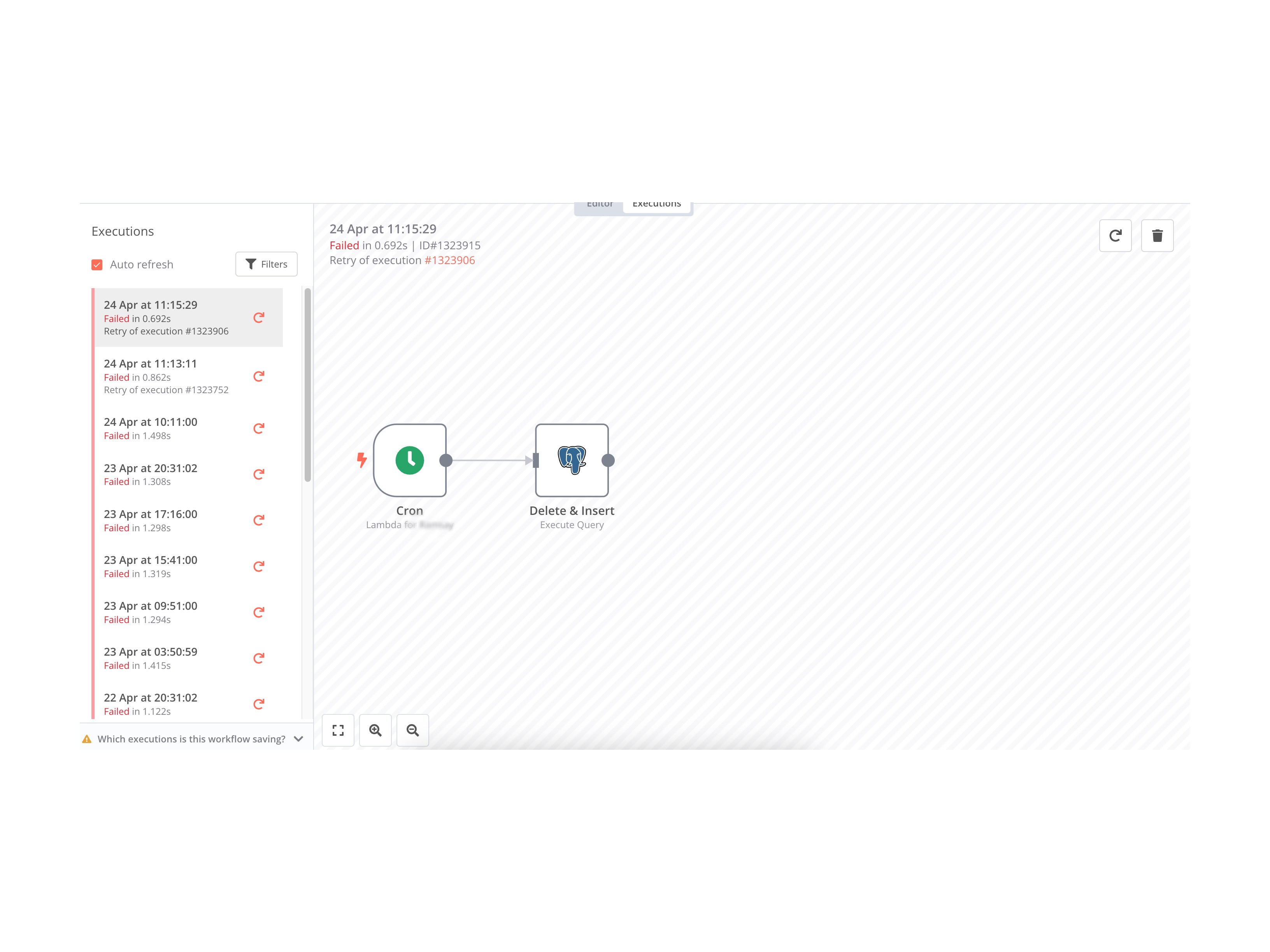
The first is the cron error when worflow fails, the other 2 are us trying to reprocess the failed execution. If then we go to the workflow and manually trigger, it works.
So when it fails to run from the cron what does the execution log say in the n8n ui? It sounds like there is possibly 2 different issues here. Once we know what the first issue is we can then look into the second one so that things don’t get mixed up.
For part of the file error though is n8n configured to run in queue mode?
Its not on queue mode. We have only one instance of n8n doing all. It never reaches cpu or memory limits. We cannot see any error log from the executiion failed.
Here is a print screen of the execution for one that failed
Jobs are failing with no logs, but now, if I retry a failed job, it works. It does not show the error: Cannot read properties of undefined (reading 'nodeExecutionStack')
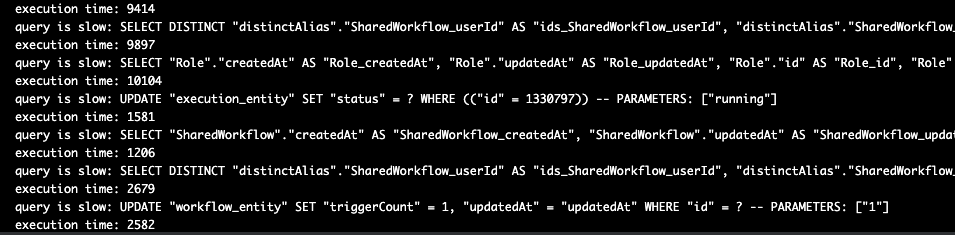
This is good progress, Can you enable debug logging: Logging - n8n Documentation that should show a bit more information.
I wouldn’t expect to see slow queries on a postgres database so I guess just to confirm… in the issue template the database field was left with just Postgres in it. Are you using Postgres for n8n as well or just the default sqlite database? If it is sqlite that could explain the issue as it gets slower as it gets bigger and I noticed there were no data pruning options in the env vars you sent over.