First time n8n user! I’m testing a workflow where I parse a csv file (24500 rows) and insert those into a SQL table. I’m batching uploads to Postgres in 2500 row increments.
I’ve seen that upgrading my give me more memory. I’m currently on the free plan. But I don’t see anything on the pricing page about memory.
So 2 questions:
Anything wrong with my workflow?
Will upgrading help me?
What is the error message (if any)?
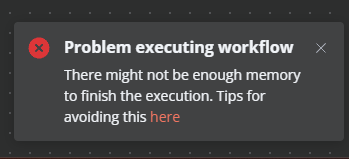
I’m getting the “might not be enough memory” error.
By free plan I guess you mean you are on a trial, We do have different memory limits for each of the plans but that CSV is potentially large so it could be worth splitting that file into smaller chunks before processing it or seeing if the Starting Line / Max Number of Rows to load will do the job.
You could also put the Postgres node in a subworkflow and see if that changes anything.
Been doing some testing with various variables and the outcome is curious. In most cases, the steps will complete (all the rows get added), but then execution still says it’s working and then it will say error / memory issue.
It seems maybe there should be a node for me to trash the data / file in memory once the final loop is complete so the execution can get marked completed.
For example, here the steps are completed, but it still says the workflow is executing is running:
Maybe @Jon knows, as I wasn’t able to read a partial file (it goes well for the first iteration, as it has the start row and how many rows to return, but I must access the binary data property each time, and that’s an issue)
I have been thinking about this one and it looks like we could do with updating the node to actually skip some lines so we can read the data in chunks. I thought it was already possible but after playing with it I also had no luck.