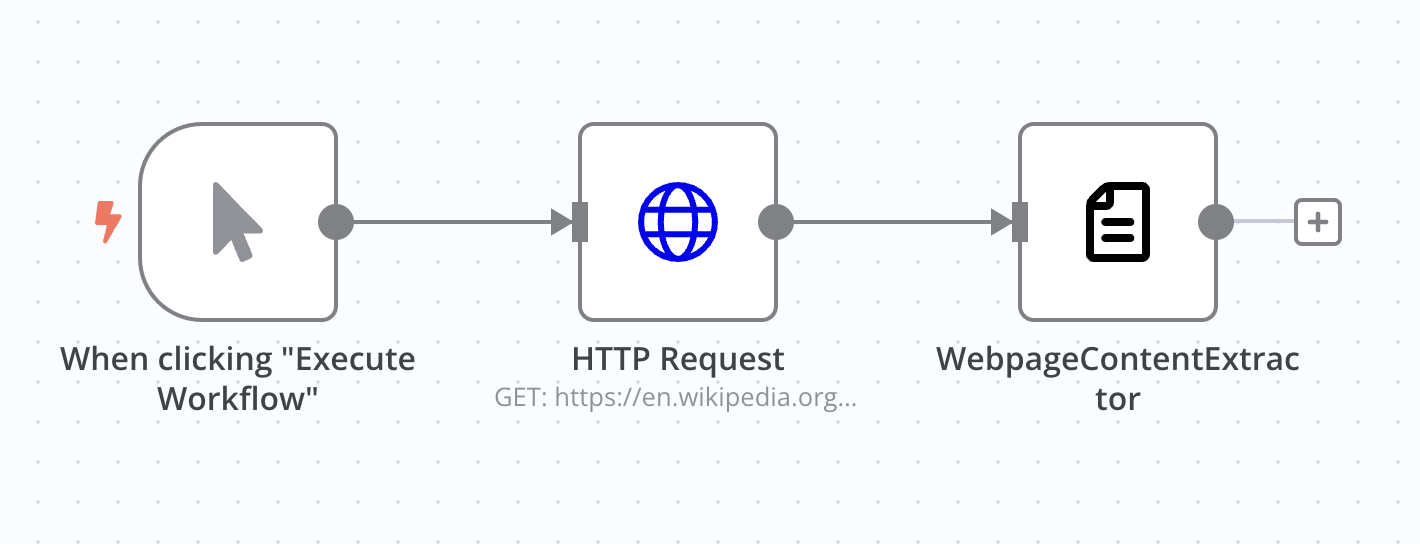
This is amazing! This helps save so many tokens and API costs when cleaning website contents.
One request I would have to improve this is to preserve formatting, for example: titles and inline links.
When using the readability feature in the Firefox browser it does do this, so I am not sure if it a limitation with the library they provide or it is not implemented.
If possible would be nice to have this, still very useful otherwise!