Describe the problem/error/question
Hey all,
I am sure some of you experienced this as well but I really want to check for the root cause of my data loss that meanwhile I found out happened multiple times already but I always that this was an error on my side. I really lost hours of work meanwhile due to this bug.
I am running n8n on a local server via docker run (portaner, not a stack) and map -v /opt/n8n:/home/node/.n8n
I can also see the sqlite database on my host machine and it seems like there are real “save points” from time to time which is then the time I get kicked back to.
With todays restart, I lost about 3 days of executions - but the last update was on Nov 5th, so for 3 days saving worked fine and then suddenly stopped which les tocms datacloss:
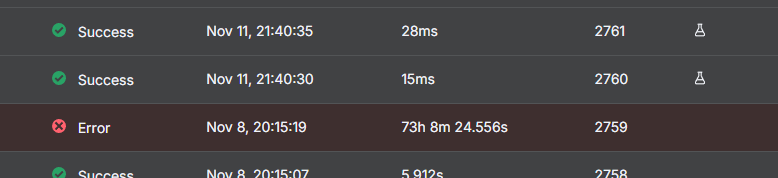
while this should be the latest stage:
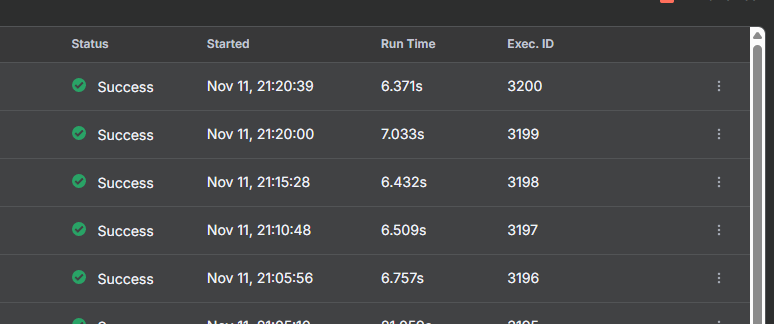
I already accepted the circumstance that I have lost my data but I really want to prevent this happening with every reboot. Maybe someone has an idea
What is the error message (if any)?
I dont see any error
Please share your workflow
Not linked to workflow
Share the output returned by the last node
n/r
Information on your n8n setup
- n8n version: 1.119.1
- Database (default: SQLite): sqlite
- n8n EXECUTIONS_PROCESS setting (default: own, main): n/r
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker (run)/Portainer
- Operating system: Ubuntu 24.04