I am new here and have problems to read all URL’s from a JSON file.
You can find my workflow here. Maybe there is someone who can help me?
I create a HTTP request to the JSON file. In another request I say that I want to get the “coverImgUrl” as a file, so I can read it as a URL and copy the file behind it to my FTP.
This works with the first object [0] in the JSON file. However, I have multiple objects with different “coverImgUrl”.
How do I get this workflow implemented so that also
https:{{$node[“HTTP Request”].json[“x”][“coverImgUrl”]}}
is executed?
X here stands for all other entries with a URL
Hi @gnrmarcel, welcome to the community!
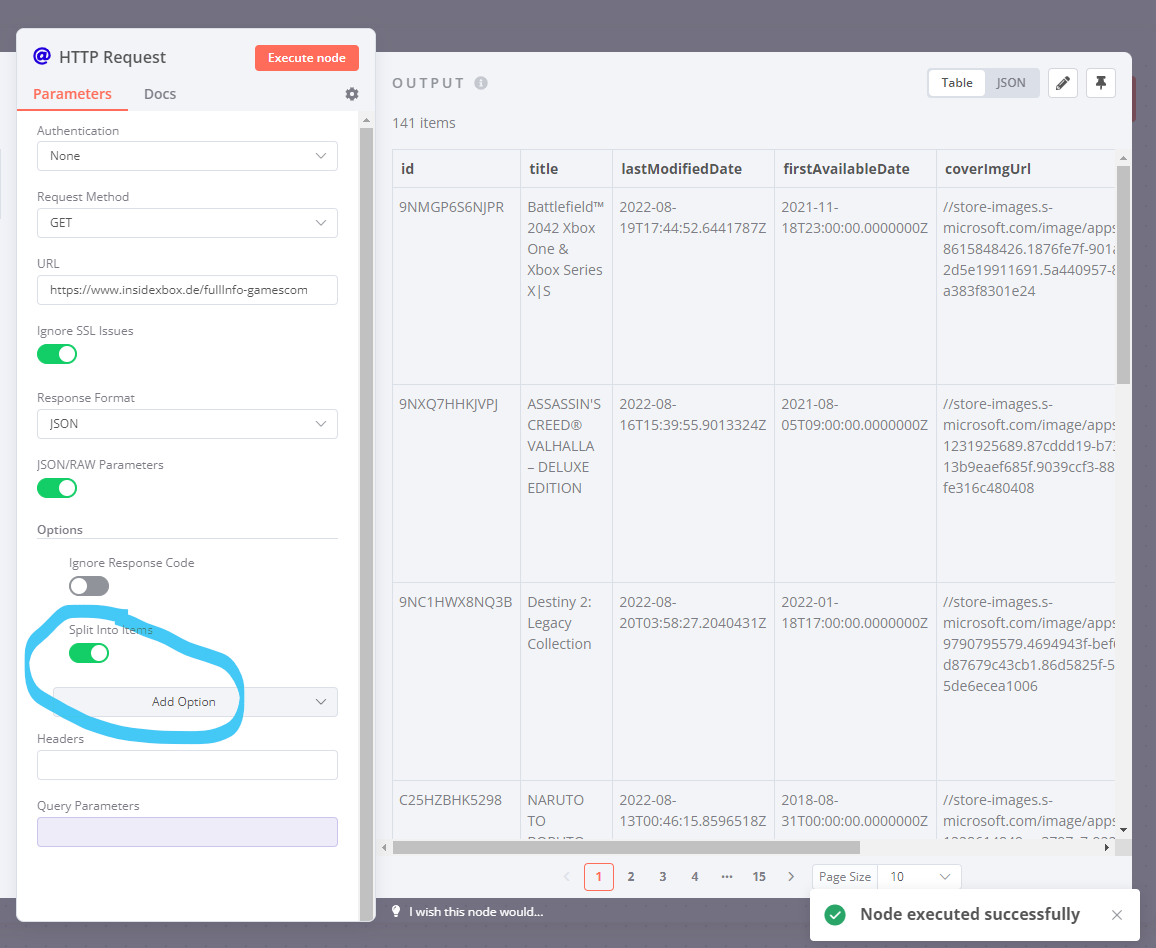
Try enabling the Split Into Items option of the HTTP Request node. This would cause the result array to be parsed by n8n (meaning you get 141 individual items rather than 1 item with 141 properties like [0], [1], [2], etc.
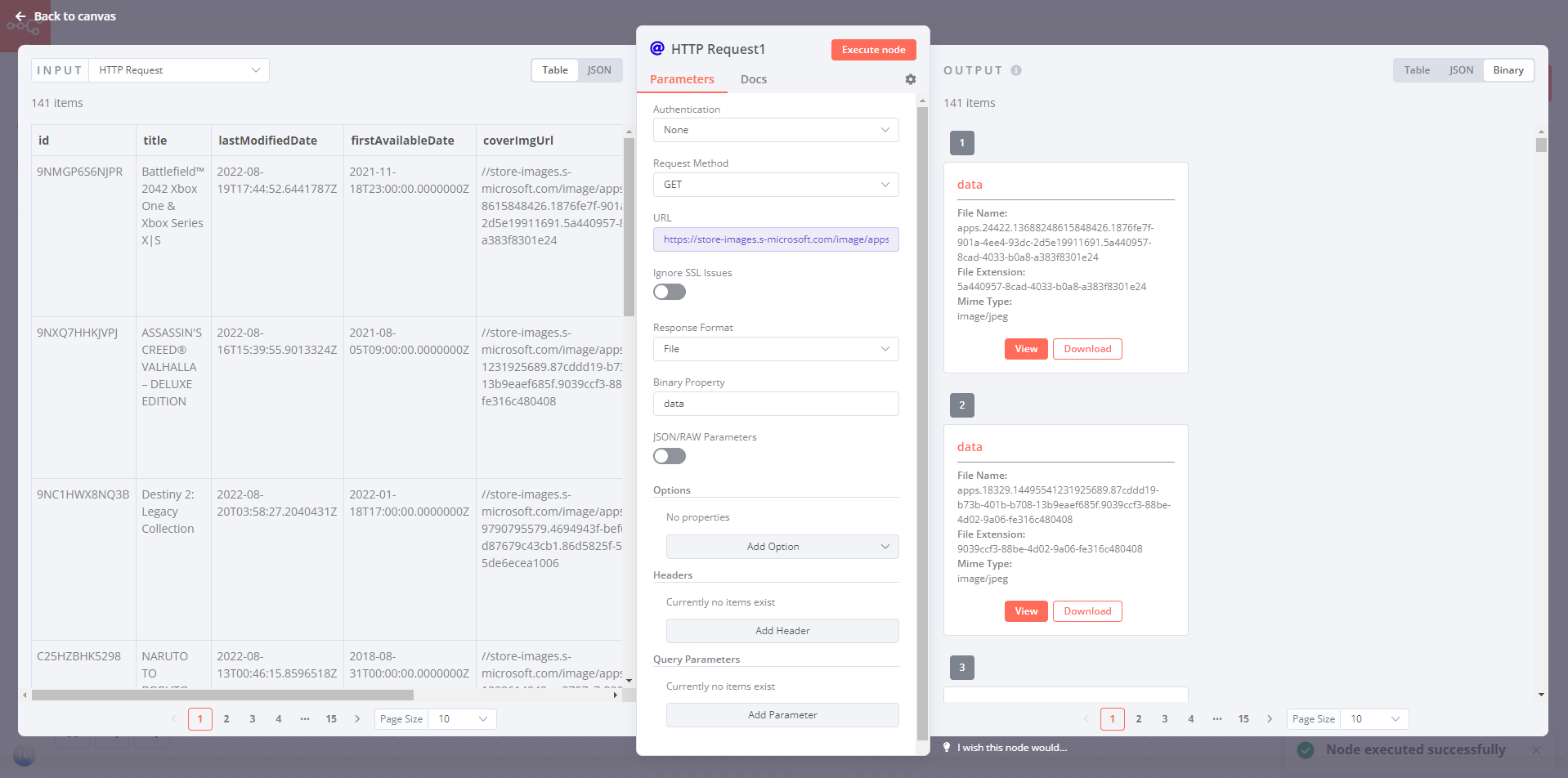
On the second node you could then use an expression such as https:{{$json["coverImgUrl"]}} to download the file from coverImgUrl for every single incoming item:
As a workflow, this would look like so:
When running this, keep an eye on the memory consumption of your n8n instance - n8n would by default keep all items in memory during the workflow execution, so depending on how big the files are this might cause trouble.
Hope this helps! Let me know if you have any further queries on this (or in case you need to optimize the memory usage) 
Thank you for your fast answer!
Thank you for the quick reply.
Yes, the workflow works now for all objects / URL’s.
But unfortunately the upload to FTP does not work now, because probably the amount of data is too big.
“Request failed with status code 413”
Is there possibly a way to reduce this amount of data or to limit the upload “cover” (URLs)? Then the upload takes longer but I would appreciate it if I could transfer all images via this workflow.
So the 413 error wouldn’t indicate a memory problem but is merely an indicator of an unexpectedly large dataset. So as a first step you might want to crank up the value of the N8N_PAYLOAD_SIZE_MAX environment variable big time.
As for avoiding processing a large amount of data at once you might want to split up your workflow into two smaller workflows. In your “parent” workflow, fetch the list of URLs you want to process and split them up into smaller batches. In your “child” workflow, you’ll then process each batch individually and make sure to only return a very small dataset to the parent (something like "success": true perhaps).
Parent example
Child example
Make sure to update the workflow ID used in the Execute Workflow node in the parent so it points to the workflow ID of the child workflow:
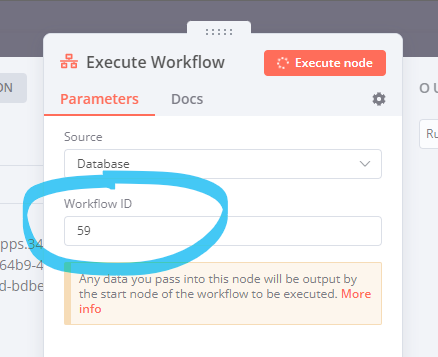
You can find the right ID in the URL after saving the child workflow:
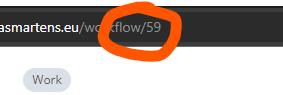
This should leave you with 141 files on your FTP and only a small amount of data in the parent workflow
1 Like
Thanks for the answer.
I have reduced the number of URLs in the JSON file to 10 for testing and already the workflow is going through correctly as I would like.
Since I am new to n8n, I am currently still using the macOS app for “testing”.
Now, to set up a parent and child workflow, I guess I need a self-hosted instance of n8n? I’ll have to see if I can find a suitable webspace / hoster here.
Hey @gnrmarcel, this approach would also work on the desktop apps, but finding out the workflow ID through the URL would be a bit tricky indeed (since you don’t see the URL).
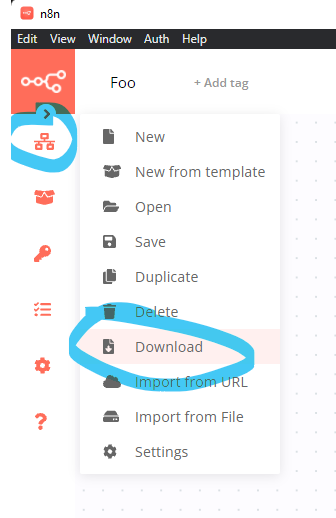
So my suggestion would be to “download” the workflow from the app like so:
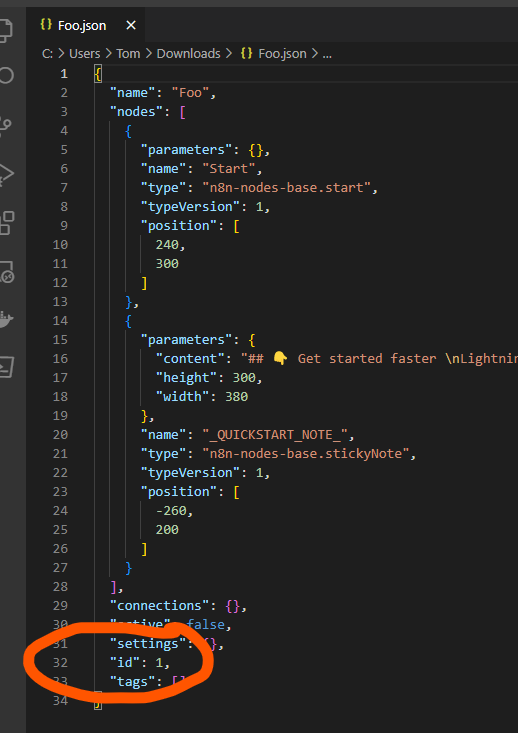
The ID would then appear in the exported file like so:
Alternatively you could access n8n desktop through your browser (http://localhost:5679) in which case you’d see the URL. The required username and password can be shown through the Auth menu of the desktop app:
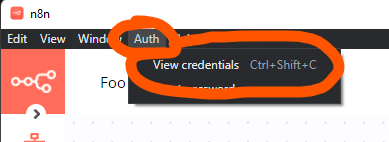
As for self-hosting you could consider Oracle Cloud if you’re looking for a free option for which I’ve written a tutorial a while back. Pretty much any other VPS provider should do the job as well though.
Thanks … through your website I saw that you are from D-A-CH? Blog is definitely subscribed for n8n news
Btw, the parent / child workflow thing works, but only if I set the SplitinBatches to 1 and then the download is done directly within a few seconds … only the parent workflow still works through “all” URL’s
PS: It all works even if you disable SplitinBatches Translated with DeepL Translate: The world's most accurate translator (free version)
1 Like
Btw, the parent / child workflow thing works, but only if I set the SplitinBatches to 1 and then the download is done directly within a few seconds … only the parent workflow still works through “all” URL’s
It’ll also work with larger batches, provided you disable the mock data node in your child workflow. This is how it looks like (at the end you’ll see the result on the FTP server):
https://www.thomasmartens.eu/wp-content/uploads/2022/08/Firefox-Hqfj8xn0bj.mp4
What happens here is that only the current batch of files is kept in memory. On the next loop the memory is made available again for the next batch. This is usually only necessary if you download large amounts of data though (but is definitely good to have in the back of your mind for such use cases).