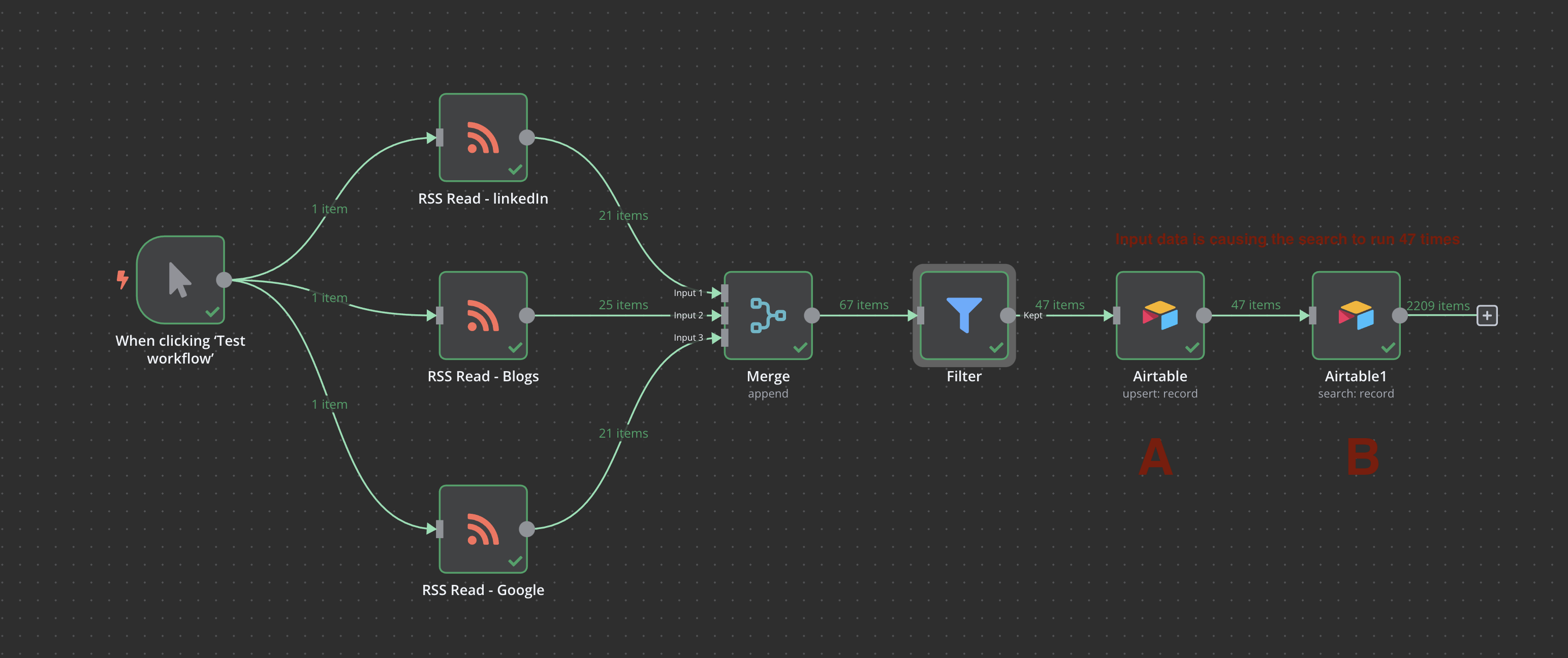
In my workflow I need to execute a node without regard to the previous node and the input data.
More specifically I am pushing data into an airtable table. I then want to turnaround and read from the same table (with some filter criteria). However, because the previous node has input data, it’s running the search node once per input item.
In this diagram at Point A you can see where I’ve done an insert of 47 items into airtable. Then at Point B I want to read data from the same table but it’s executing the node 47 times because of the input data, returning a “fake” 2209 items (47 x 47).
How can I structure this so that after the upsert, I can “ignore” input data and just do a clean read of the table as my new input data for the next node?
I tried splitting it into two different workflows but then the execute workflow passes on the input data and I have the same issue.
Hi @FelixL thanks for the suggestion. I wasn’t aware of the limit node and in my case that will work by setting it to 1, because the input data set is irrelevant for the Airtable search node and setting it to 1 at least causes it to be only executed once. So thanks for that.
I agree though I’d still be curious on what the “right” workflow design should be to get around this issue.