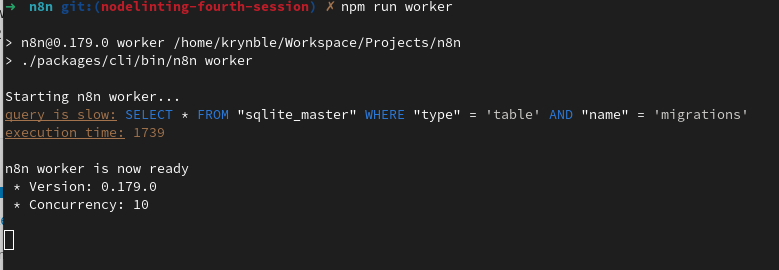
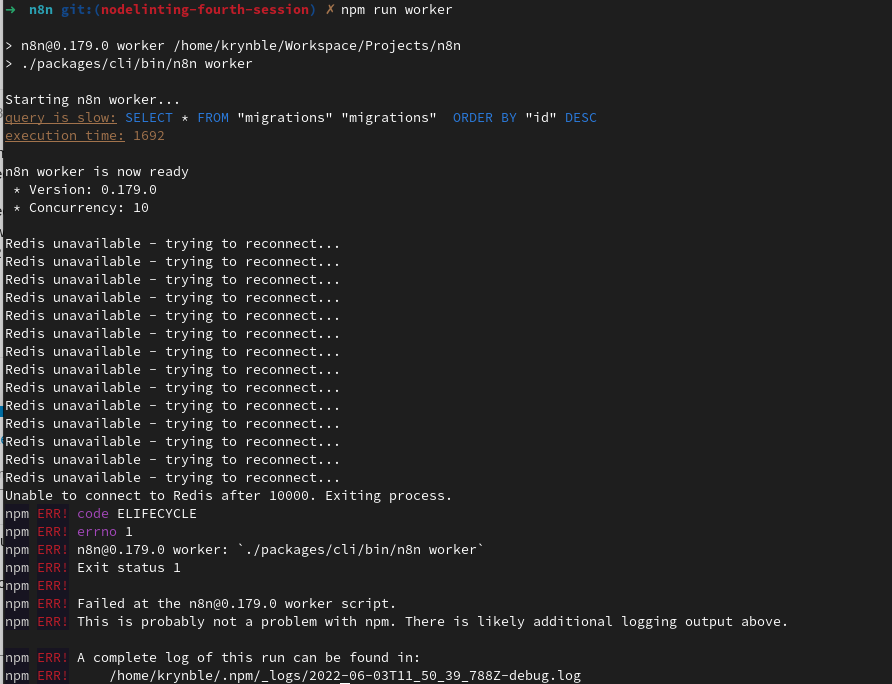
The worker tasks start up successfully. Once running, however, their only further output is to log queue errors every 30 seconds: Error from queue:
Looking at the code, it appears that the exception is supposed to output after that statement, but it’s blank in the log: packages/cli/commands/worker/ts:351
logger.error('Error from queue: ', error);
Without error information, the cause has been difficult to diagnose. Does anyone know what could be causing this?
What is the error message (if any)?
Error from queue:
Please share the workflow
N/A
Share the output returned by the last node
N/A
Information on your n8n setup
n8n version: latest in docker
Database you’re using (default: SQLite): postgres
Running n8n with the execution process [own(default), main]:
Running n8n via [Docker, npm, n8n.cloud, desktop app]: Docker
Configuration Details
Main process
The existing production deployment is a task running in AWS ECS, which persists data in an RDS postgres instance. This main process is not yet set to run in queue mode. The intention is to flip it into queue mode once the worker tasks are operational.
The new worker processes have been added as tasks in the same ECS cluster. We initially tried hosting the job queue as a MemoryDB instance (AWS’s Redis). The result was the error described above. After attempts to get around the error, we guessed that there was some incompatibility between N8N and MemoryDB. We next tried using a regular Redis task within the ECS cluster instead. Unfortunately, this resulted in the same error.
Hey @Chase, I tried reproducing the problem you have reported but didn’t run into any trouble here. The exact docker-compose.yml file I have used is this one:
That said, I am not exactly familiar with AWS. Could you confirm whether you’re running into this problem when testing your n8n configuration even outside of AWS?
Hey @MutedJam , thanks for looking into this. I haven’t tried this configuration locally, and Amazon ECS doesn’t use docker compose yml files for configuration.
However, I went through yours, and compared your settings to what I had. I found that I hadn’t set NODE_ENV, and my N8N_LOG_LEVEL was still set to info. I set the former to production, and the latter to debug. This hasn’t fixed the problem, but I am at seeing the exception populated in the logs instead of coming out blank, which is one of those rare cases getting an error is an improvement:
e[31merrore[39m | e[31mError from queue: e[39m {"errorno":"ETIMEDOUT","code":"ETIMEDOUT","syscall":"connect","file":"worker.js"}
It’s a little messy with the terminal control characters, but it looks like the worker is timing out trying to connect to the queue?
Good spot, the timeout here could indeed indicate a communication problem between your n8n instances and Redis. Perhaps @krynble could confirm this?
When facing timeouts myself there is almost always a firewall at play dropping my traffic somewhere along the way. I wonder if this might be the case for your AWS EC2 networking setup as well. Is there a chance your EC2 security group doesn’t allow Redis & n8n to talk to each other?
Thanks for the response! Sorry for the lag between replies here, I’m hopping on and off this upgrade.
I’ll look into why those tasks can’t communicate. I am curious as to why I’m getting a different error though. Instead of the “trying to reconnect” and “Unable to connect”, I’m getting the ETIMEOUT exception. There’s also a new thing complaining about “No codex available”, but I think that’s unrelated:
Starting n8n worker...
UserSettings were generated and saved to: /home/node/.n8n/config
2022-06-08T15:28:00.979Z | e[34mdebuge[39m | e[34mNo codex available for: N8nTrainingCustomerDatastore.node.jse[39m {"file":"LoadNodesAndCredentials.js","function":"addCodex"}
2022-06-08T15:28:00.981Z | e[34mdebuge[39m | e[34mNo codex available for: N8nTrainingCustomerMessenger.node.jse[39m {"file":"LoadNodesAndCredentials.js","function":"addCodex"}
n8n worker is now ready
* Version: 0.180.0
* Concurrency: 10
2022-06-08T15:28:14.802Z | e[31merrore[39m | e[31mError from queue: e[39m {"errorno":"ETIMEDOUT","code":"ETIMEDOUT","syscall":"connect","file":"worker.js"}
/usr/local/lib/node_modules/n8n/dist/commands/worker.js:217
throw error;
^
Error: connect ETIMEDOUT
at Socket.<anonymous> (/usr/local/lib/node_modules/n8n/node_modules/ioredis/built/redis/index.js:327:37)
at Object.onceWrapper (node:events:641:28)
at Socket.emit (node:events:527:28)
at Socket.emit (node:domain:475:12)
at Socket._onTimeout (node:net:516:8)
at listOnTimeout (node:internal/timers:559:17)
at processTimers (node:internal/timers:502:7) {
errorno: 'ETIMEDOUT',
code: 'ETIMEDOUT',
syscall: 'connect'
}
Can you try downloading and installing redis-cli (it comes with the redis) package and try connecting to your redis from the same host that runs the worker process?
This should help you diagnose network connectivity issues.