Describe the problem/error/question
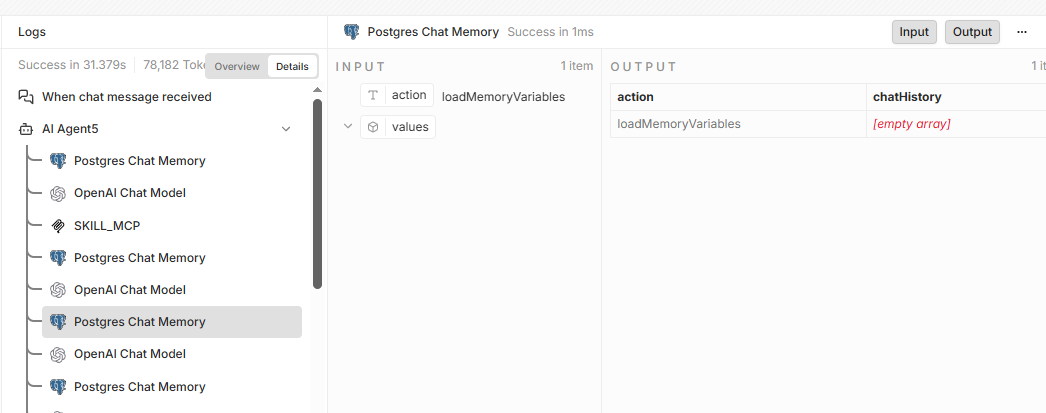
Enabling memory on the agent node will result in a loop call to loadCacheVariables,I’m not sure if this is a problem with the model or an internal prompt from the agent. The model I am using is qwen3.5-plus
What is the error message (if any)?
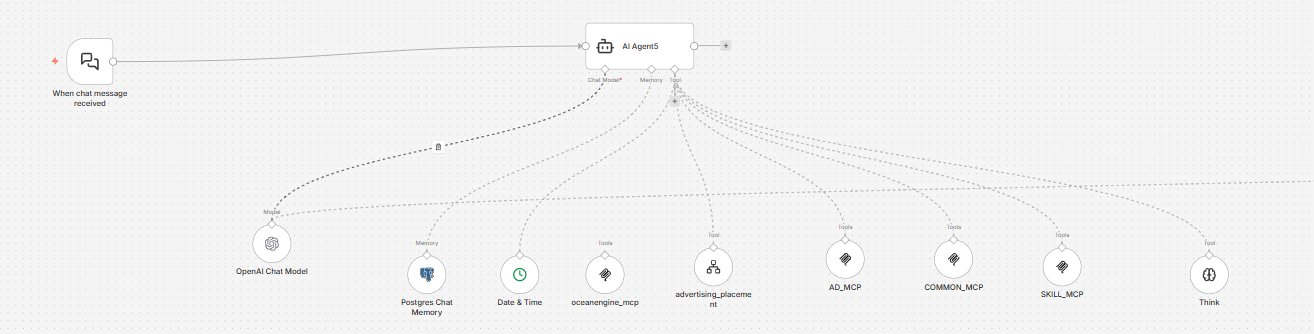
Please share your workflow
(Select the nodes on your canvas and use the keyboard shortcuts CMD+C/CTRL+C and CMD+V/CTRL+V to copy and paste the workflow.)
Share the output returned by the last node
Information on your n8n setup
- n8n version: 2.13.4
- Database (default: SQLite): postgre
- n8n EXECUTIONS_PROCESS setting (default: own, main): own
- Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
- Operating system: Docker
is that loop reproducible every time, or does it hang sometimes? and are you on the latest n8n version? had something similar with memory loops before but can’t remember the exact trigger. also maybe try testing with a different llm just to see if its qwen-specific
ok,It always loops and sometimes gets stuck. Currently, we have found that qwen3.5 has this problem, while qwen3 max will be better. It is the previous version of n8n, and there are issues with the latest version of n8n
that’s a useful data point — if qwen3 max behaves better it strongly suggests it’s the tool calling / function calling support in qwen3.5 that’s the issue. the memory system relies on internal tool calls and some models don’t handle that cleanly, which causes those infinite loops. try with openai or claude if you have access, that’ll confirm whether it’s model-specific or something in n8n’s memory implementation itself
Thank you, but the same model and prompt words are normal in Agent 2.2 and also normal in DIY, which confuses me a lot
that’s actually a super useful detail — if qwen3.5 works fine in 2.2 and in a DIY setup but only breaks with memory enabled in the current version, that points to a regression in n8n’s Agent node memory implementation rather than a model issue. worth filing a github issue with that exact comparison (2.2 working vs current broken, same model + prompts) so the team can trace what changed between versions