I am trying to integrate a webhook with multiple event payloads in a single call. For each event, there is a series of tasks implemented. In case of an error in any of these events, an error workflow gets triggered. But I am not able to identify which event in the list of events has actually triggered the error workflow. The error workflow trigger does not have any information regarding which index in the list of events was responsible for the error.
Hi @Bikash_Gupta, welcome to the community ![]()
Perhaps you can share your workflow and provide the other information requested in the question template here on the forum? This will help greatly with understanding what you are doing.
On a general level, I find that the use of the Split in Batches node makes the identification of problematic items a lot easier. Take a look at this example workflow:
By splitting the data into batches of 1 I can see exactly which input data is causing the problem on the HTTP Request node:
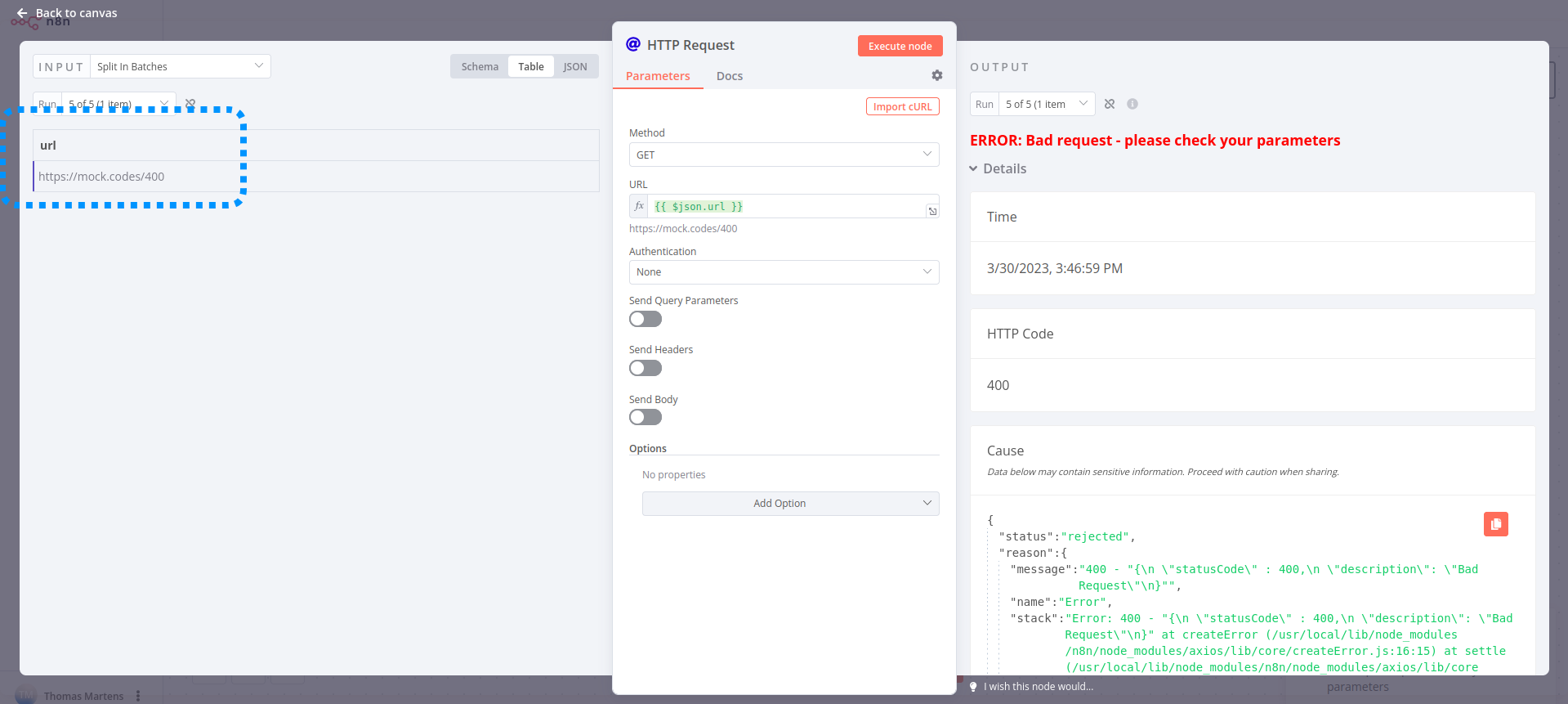
Without splitting the data I’d see the full input list, making this a lot harder:

Hope this helps!
The below workflow supports calling webhook with an array of events in a single payload. I go through each event with a switch node and make an HTTP call.
In case of an error in the above workflow, the below error workflow will get triggered. The error workflow first fetches the execution data which contains the webhook payload. But the webhook payload contains an array of events but I do not know which event actually needs to be retried which triggered the error workflow.
Sounds like you’re using the error workflow to automatically retry the workflow, rather than just notifying you of the error.
Do you need the error workflow for this? The HTTP node has a ‘retry on fail’ setting that you could use to retry the request before the workflow fails:
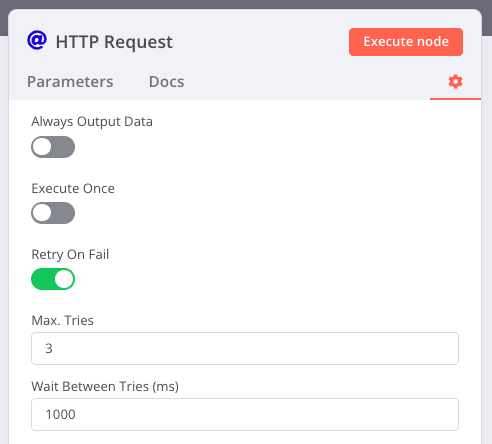
The HTTP node does not take a wait time of more than 5 seconds. Moreover, I am trying to retry the workflow based on different kinds of errors. The error workflow which I have provided is very simple and was for explanation purposes, in actuality it is going to be complicated. In case 429 too many requests are returned, I will retry the workflow after 15 mins and exponentially increase the wait time.
We’re about to release a feature that may help with this: the ability to save arbitrary data with an execution and read it out later. (This feature will launch on our paid plans, excluding Cloud ‘start’)
When can I expect the release with this feature?
This should launch imminently (in 0.222), although it may not have the ability to query the data programmatically at first
With the custom data feature, I am still not able to identify how I am gonna identify which branch of the switch node has resulted in the error. Is there a way where I can say which index position of the payload has resulted in the error?
We’ll need to add the custom data to the output of the error trigger. As mentioned previously this is not available yet, unfortunately.
Ok. Thanks for the help
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.