I discovered n8n a short time ago, and I immediately saw my interest in this product.
I regularly have automatic tasks to perform like syncing data from various sources to multiple databases.
So far I have built quite complex workflows (with code) to do this work.
But now I’m stuck! Not because of the logic of the workflow to implement but because of the memory used.
Let me explain, I have to read (every day) a CSV file of 500 000 lines that I have to integrate in a database.
Doing it in one pass was not very successful.
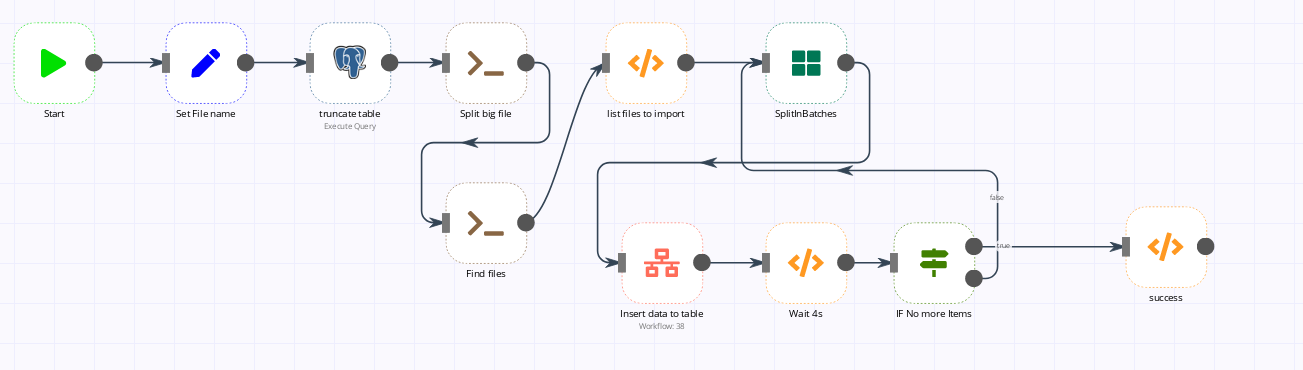
My plan “B” was to split this file into several files with fewer lines. This list of files is then injected into the SplitInBatches component which is responsible for sending the file name to another workflow (containing the data import).
In the logic everything works fine except that as the loops go on the memory load keeps increasing. I thought that the RAM would be freed up as we go along, but no.
Have you done a similar case, which would be my plan “C”?
Sorry to hear that you have problems! To get that fixed two steps are important:
Understand how n8n works
Data in an execution does never get “freed up”. Once it is loaded it will stay there until the workflow execution is finished. That said, we have planned to change that in the future. It will get a mode where data does get freed up after every node if gets enabled. This will then obviously come with a big performance hit but for such use cases, it should however not matter if an execution is slower, as long as it runs successfully. After that, your plan “A” should also work. Sadly no ETA for it.
Using that understanding to fix the workflow
You have to make sure that the data does never end up in an execution. Your plan “B” should theoretically work totally fine. But I assume that the data of each of the iterations ends up again in the main worflow. Most likely because the last node of the second workflow (which does the import) still contains the whole data. If that is the case it will then send this whole data back to the main workflow. So the solution would be to make sure that the last node sends back as little data as possible. Best a single empty JSON. The easiest and most efficient way to do that, is adding a Set-Node two the second workflow. You have to make sure to activate the option “Keep Only Set” and under “Settings” additionally “Execute Once”.
Thanks to answer.
currently, I use plan “B” with a workflow to split and use the SplitInBatches and a workflow to insert data to my table. See pictures.
In the workflow I already return a empty function to clear output data but I have a same problem.
Sorry, I sadly do not understand. What do you mean with “After a insert/update, n8n must implements an option that return a custom function againts return all rows to output.”
I did several tests with n8n sometime ago with huge amounts of data.
This is not recommended because n8n was created with another goal. For small iterations (say less than 5000 rows) n8n could achieve what you are looking for.
But if you want to work with those amounts of data, I recommend using another option like etl/elt software or other projects like https://meltano.com/
Ok 500k rows are big but I splitted this Big file in many files with 10k rows.
I think n8n can add an option to clear memory After a workflow to fix this memory leak. I don’t know if it is possible
often and frequently as the saying goes in integration. most ipaas struggle under volume because they are not designed to be database migration tools…they are work optimally using deltas