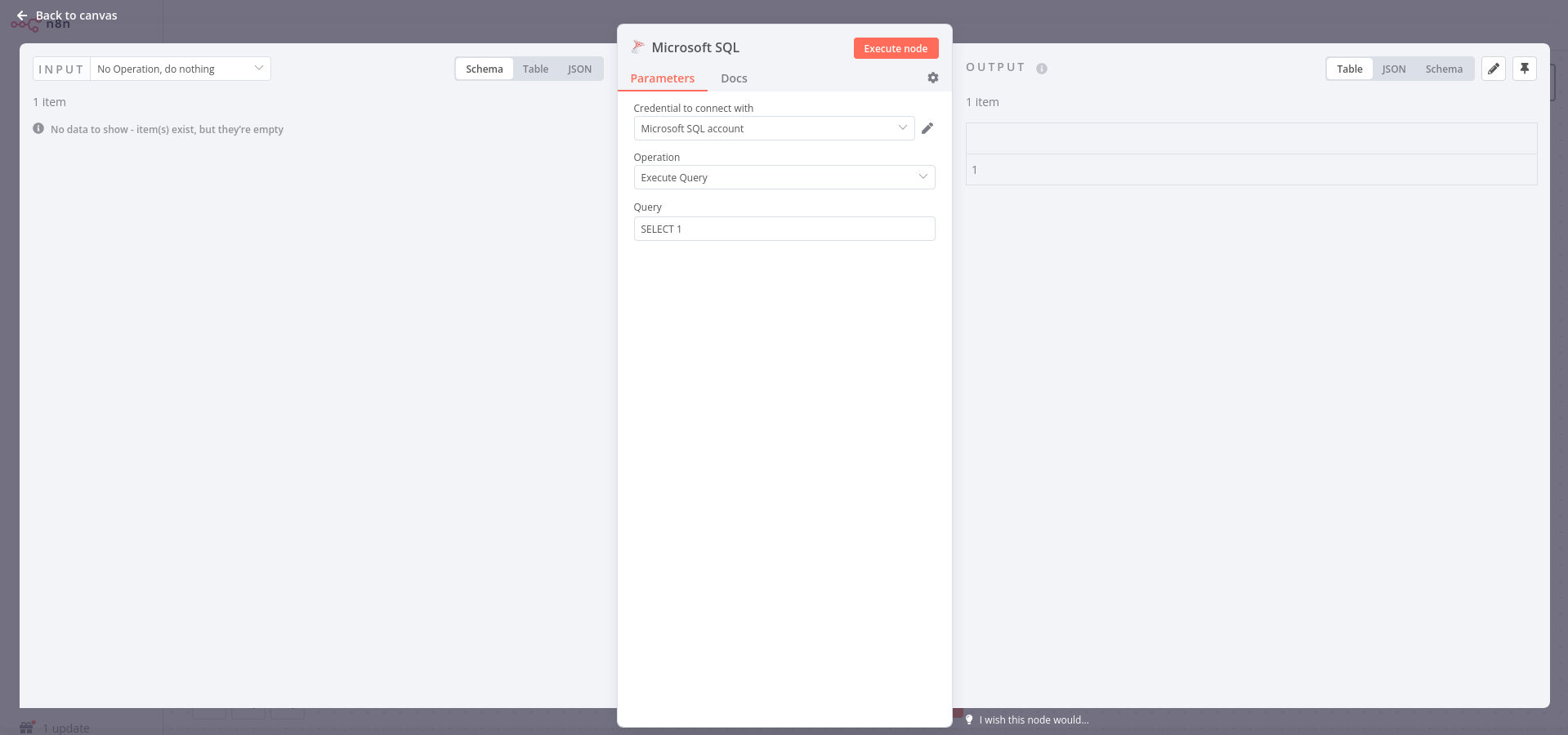
Manual trigger → Execute query using Microsoft SQL Server. A few issues:
When clicking Execute Node on Microsoft SQL server mode, it continues to run and it seems the previous node (manual trigger doesn’r run)
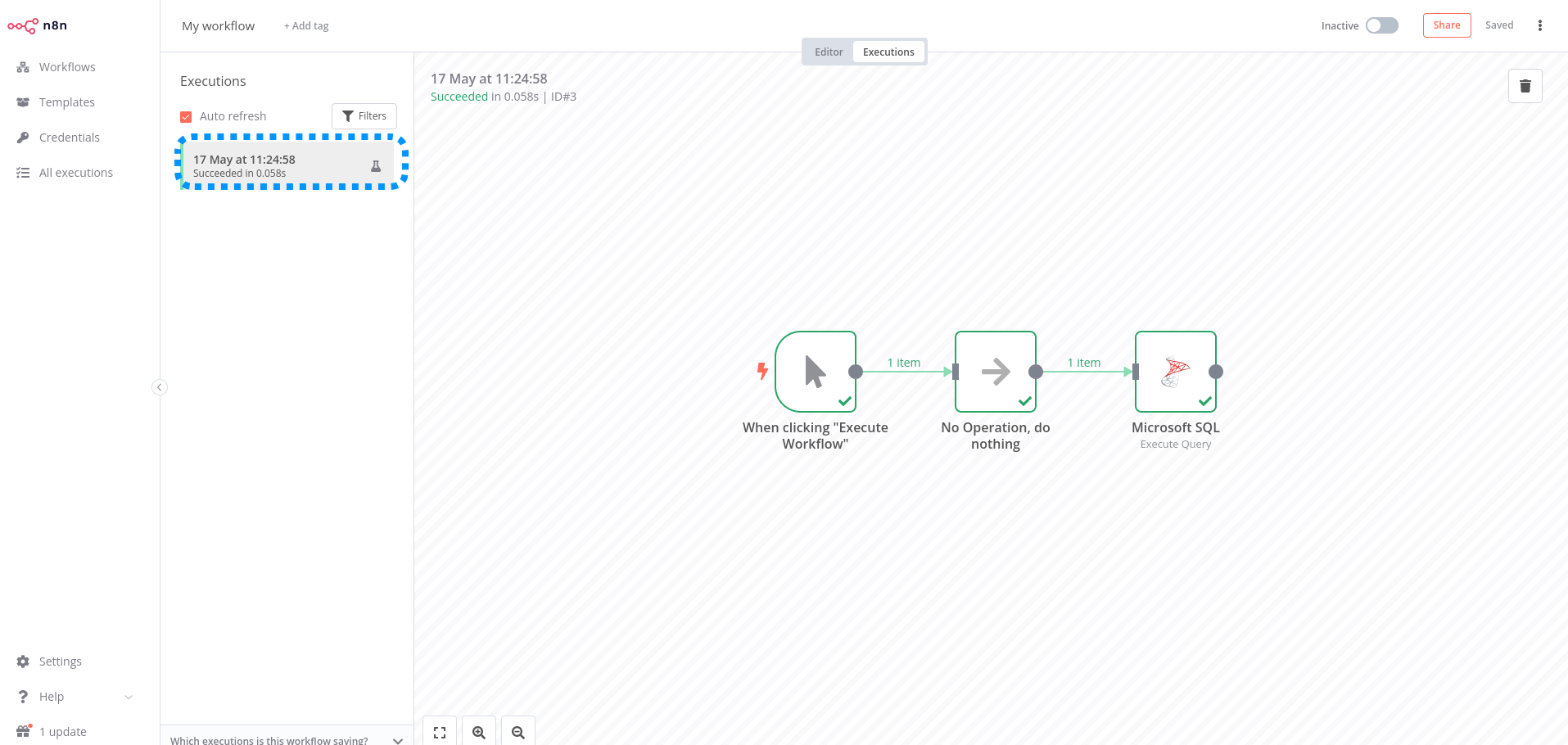
When clicking Execute workflow, it ran once but workflow didn’t save in execution log.
I tried running it again but since the first run, the workflow just runs indefinitely and the Manual trigger doesn’t seem to execute at all, just stays grey.
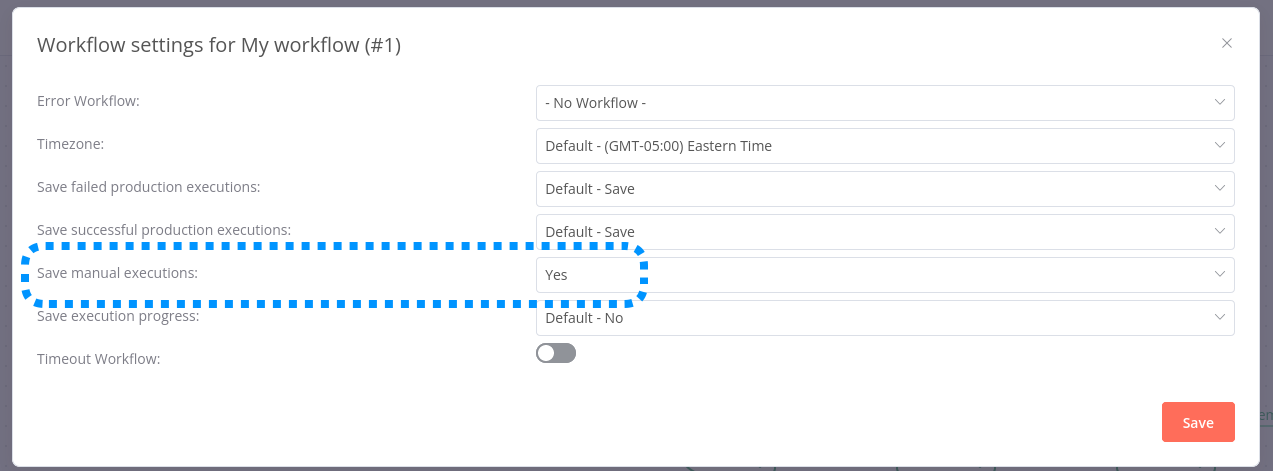
This is expected. By default, manual workflow executions are not stored in the execution list. You can however configure this behaviour in the workflow settings:
Based on the behavior you have reported I suspect what’s happening for your items 1 + 3 is that your n8n instance isn’t able to send status updates to the frontend. This happens through Server Sent Events which might not be processed properly by your reverse proxy (or other components sitting between your n8n instance and your browser).
So perhaps you can try running your workflow locally rather than on a webserver? If this works for you locally, but not on your webserver you might need to check the relevant configuration on your web server. You could also try switching to Websockets using the N8N_PUSH_BACKEND=websocketenvironment variable.
I have saved manual executions. I can see the executions have ran successfully when looking at the execution list, however, the workflow it self will just appear as running with nodes still grey.
It seems to only work once in the UI, then subsequent executions do not…
Can you share more information on your setup? I take it you are probably using a reverse proxy if you bypass the proxy and connect directly do you have the same issue? We have seen this issue happen with some reverse proxies so it could just be a config issue.
We are not using any CDN. Direct to AWS ALB to ECS containers
we are using MySQL database
require VPN access to UI
Further description of issue:
when first loading workflow connecting to VPN, manual execution works fine 2-3 times consecutively (sometimes) but after that workflow will just hang in execution state. If I stop the execution, the workflow shows as complete - they also appear in executions list
Activating and deactivating workflows - workflows continue to run on server (based on execution list) even when deactivating workflow
I am seeing the following logs in cluster logs but not sure if related.
2023-05-23T22:08:45.112471Z 129178 [Note] [MY-010914] [Server] Aborted connection 129178 to db: ‘unconnected’ user: ‘rdsadmin’ host: ‘localhost’ (Got an error reading communication packets). (sql_connect.cc:835)
When stopping workflow after it’s in hanging state when running manually, I see the following error in dev console:
Also, as mentioned above, stopping the execution when hanging can show the workflow executed however after a few runs, this doesn’t work and I get the error:
Problem Stopping Execution: The execution ID # could not be found.
The only way to fix this is either refreshing multiple times, disconnecting VPN and reconnecting OR a combination of those.
We really need this solved ASAP. Unfortunately we have been trying to fix for over a week and we can’t find clear solutions in the community.
I would probably look into that MySQL error as n8n will need to be able to talk to it to function so there could be part of the issue there, I have seen the execution cancellation error and infinite spinning a lot and it is normally a proxy issue.
As a test can you bypass ALB and use the IP for the n8n instance and see if that works, I have a feeling this will solve the problem unless you are using Lightsail which has other issues.
Did you also try setting N8N_PUSH_BACKEND to websocket in the end?
I noticed that on error in the workflow, if I stopped it while it was in hanging state, I would have to check the executions list to see the workflow actually ran despite it saying Error: workflow # could not be found.
However, on success, it seemed that by stopping workflow in hanging state, it would display the nodes in green in the workflow UI itself. Very strange…
We are going to re-deploy all resources again using Postgres and reference this:
I hope this can help us isolate issues to infrastructure used by most in the community to get to the bottom of it. We can’t see any security permissions in terms of ALB interfering with n8n…