Hi there,
I want to extract data from a table on a website using n8n.
I first download the content of the page using browserless and then use html extract to extract the data using these settings:
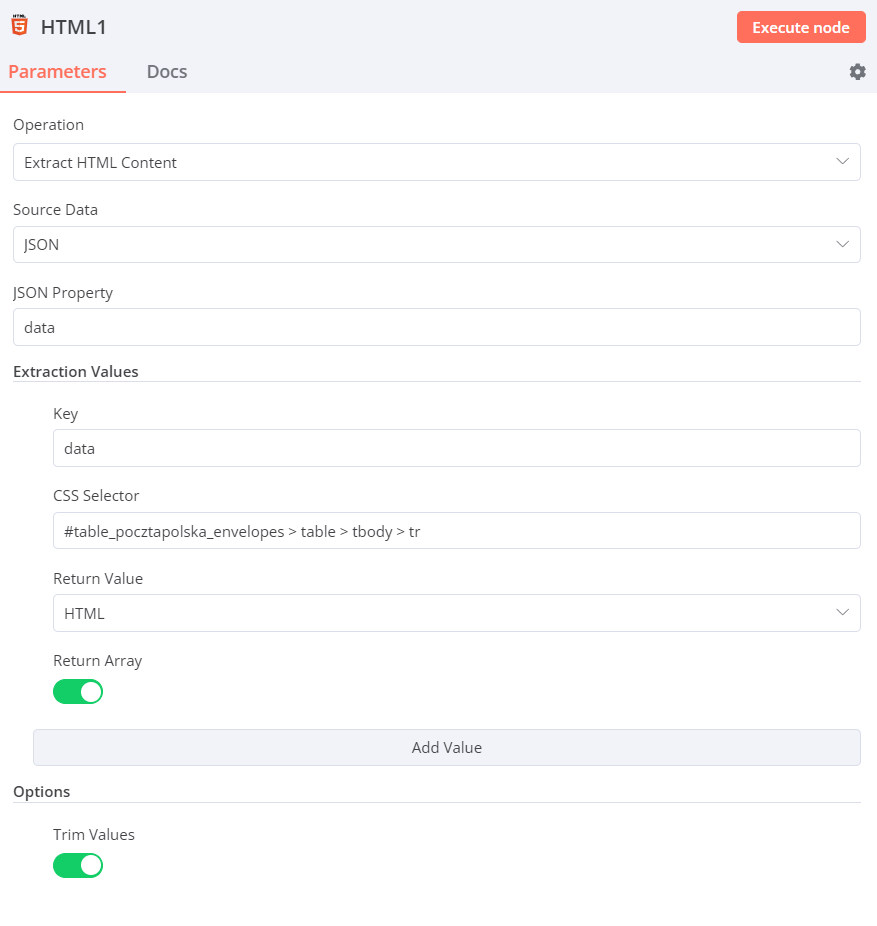
Then from the output of that node I want to extract every td element
But it only returns an empty array
For testing I used “*” in html2 node CSS selector and this was the output:
<head></head><body>239188988\n 08.01.2024 17:00\n 5\n DAGRA\n Przekazano do urzędu pocztowego (WYSLANY)\n \n <a href="ajax/ajax_order_packages.php?courier=pocztapolska&get_envelope_labels=239188988" target="_blank">Etykiet</a> | \n <a href="ajax/ajax_order_packages.php?courier=pocztapolska&get_envelope_book=239188988" target="_blank">K. nadawcza</a> | \n <a href="ajax/ajax_order_packages.php?courier=pocztapolska&get_pocztafirmowa_book=239188988" target="_blank">Poczta firmowa</a>\n </body>
I don’t know why body or head suddenly appeared in the output and there were no td elements.
Information on your n8n setup
- n8n version: 1.16.0