Thanks everyone in advance, newbie to n8n from zapier, I need some help on extracting content from HTML
-
Extract the RSS and save to Google Sheet (Date, Title, URL of the blog)
-
Human Read the Sheet and input “Y” to the “Selected” column
-
If “Selected” = “Y” then HTML extract base on the URL, extract the text content body and image
I am done with the RSS to Google Sheet. But I don’t know how to do the 2 and 3.
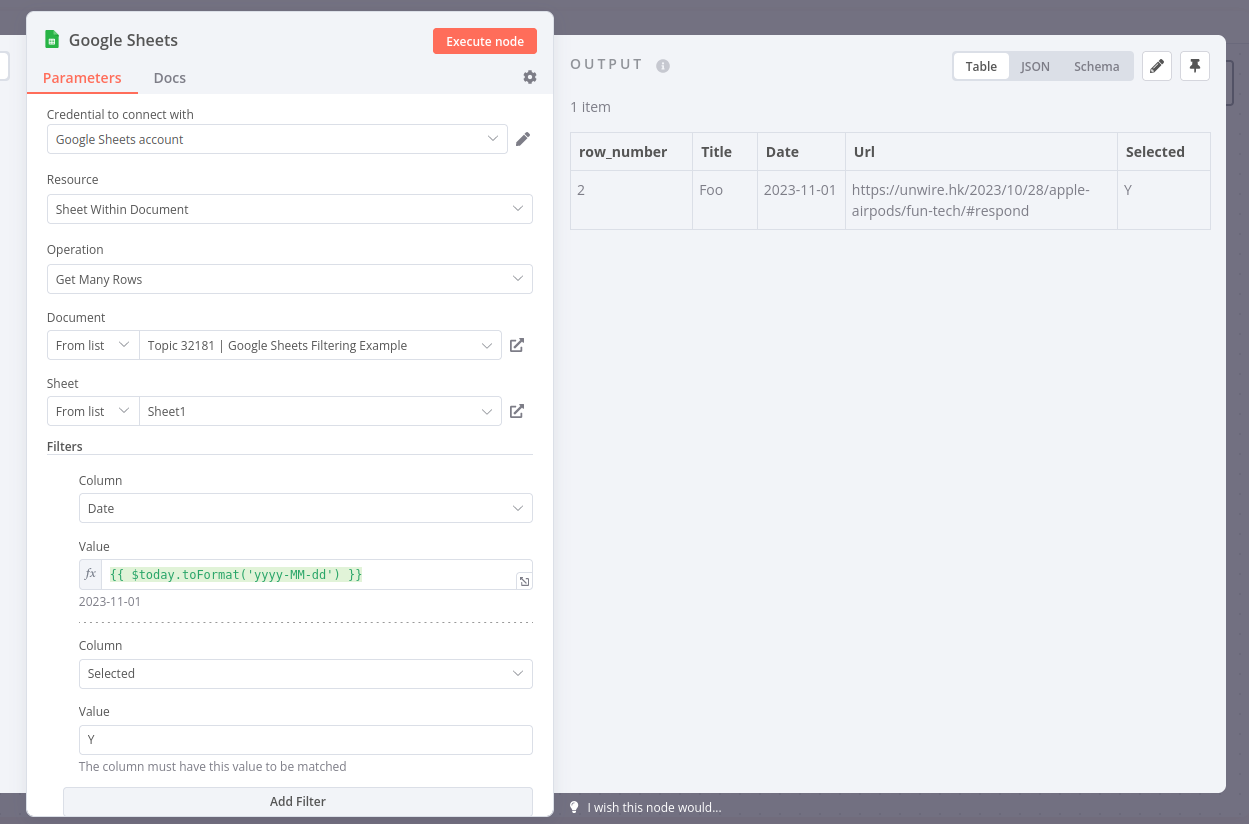
Q1: Should I use Filter, and “Selected” = “Y” ?
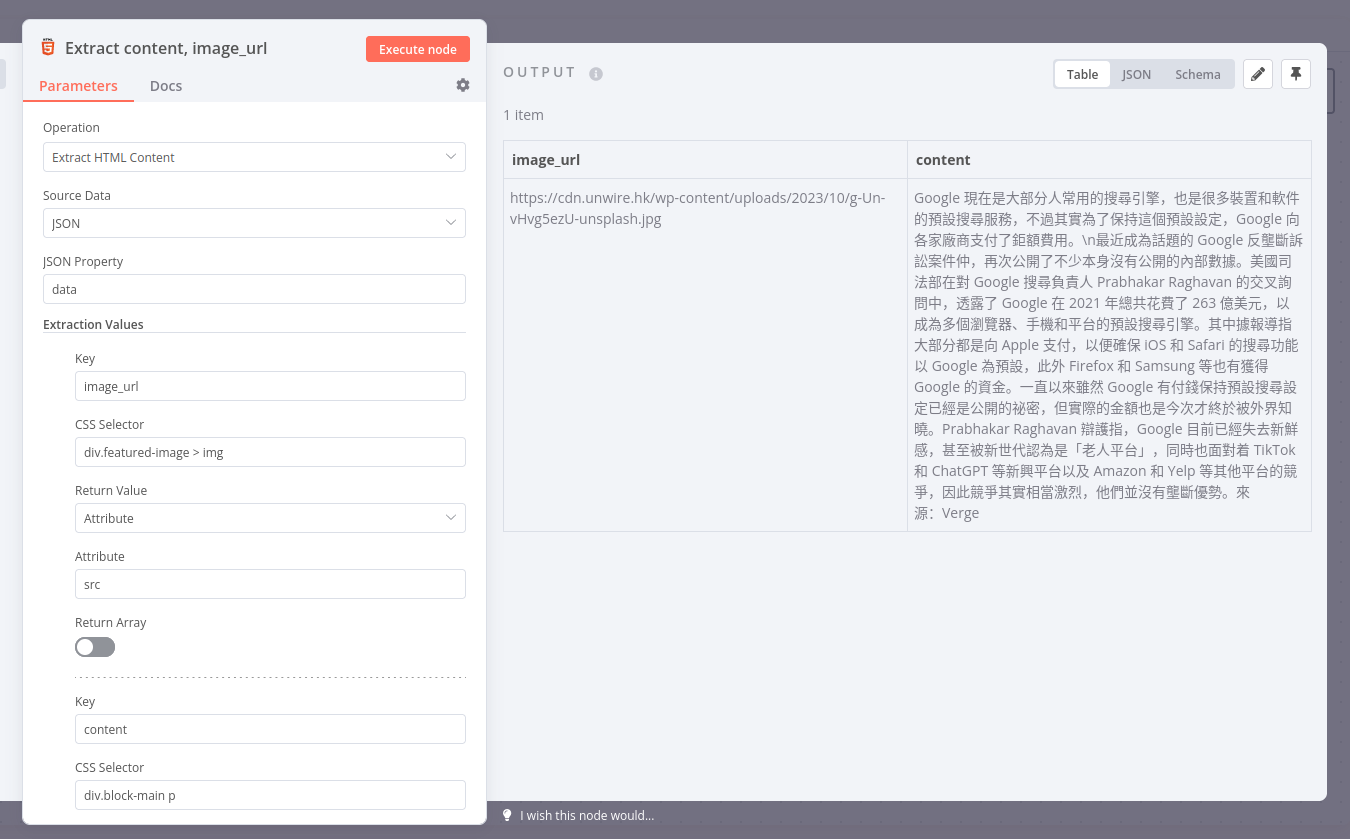
Q2: How to extract the content body , jpg URL and put it back the the Sheet ? ( I have done using HTTP Request, but I don’t know how to fill the HTML5 ExtractHtmlContent fields"
Sample URL: 彭博:新 AirPods、AirPods Max 或明年推出 改善音質、充電盒、耳塞設計 - unwire.hk 香港
the sample JPG I want should be:
“https://cdn.unwire.hk/wp-content/uploads/2023/10/g-Un-vHvg5ezU-unsplash.jpg”
from
{“@id”:“Google 鉅額保持預設搜尋地位 2021 年向不同廠商支付 263 億美元 - unwire.hk 香港”
the sample content body I want should be:
"最近成為話題的 Google 反壟斷訴訟案件仲,再次公開了不少本身沒有公開的內部數據。美國司法部在對 Google 搜尋負責人 Prabhakar Raghavan 的交叉詢問中,透露了 Google 在 2021 年總共花費了 263 億美元,以成為多個瀏覽器、手機和平台的預設搜尋引擎。其中據報導指大部分都是向 Apple 支付,以便確保 iOS 和 Safari 的搜尋功能以 Google 為預設,此外 Firefox 和 Samsung 等也有獲得 Google 的資金。
\n一直以來雖然 Google 有付錢保持預設搜尋設定已經是公開的祕密,但實際的金額也是今次才終於被外界知曉。Prabhakar Raghavan 辯護指,Google 目前已經失去新鮮感,甚至被新世代認為是「老人平台」,同時也面對着 TikTok 和 ChatGPT 等新興平台以及 Amazon 和 Yelp 等其他平台的競爭,因此競爭其實相當激烈,他們並沒有壟斷優勢。
來源:Verge"
from
Google 現在是大部分人常用的搜尋引擎,也是很多裝置和軟件的預設搜尋服務,不過其實為了保持這個預設設定,Google 向各家廠商支付了鉅額費用。
\n
最近成為話題的 Google 反壟斷訴訟案件仲,再次公開了不少本身沒有公開的內部數據。美國司法部在對 Google 搜尋負責人 Prabhakar Raghavan 的交叉詢問中,透露了 Google 在 2021 年總共花費了 263 億美元,以成為多個瀏覽器、手機和平台的預設搜尋引擎。其中據報導指大部分都是向 Apple 支付,以便確保 iOS 和 Safari 的搜尋功能以 Google 為預設,此外 Firefox 和 Samsung 等也有獲得 Google 的資金。
\n一直以來雖然 Google 有付錢保持預設搜尋設定已經是公開的祕密,但實際的金額也是今次才終於被外界知曉。Prabhakar Raghavan 辯護指,Google 目前已經失去新鮮感,甚至被新世代認為是「老人平台」,同時也面對着 TikTok 和 ChatGPT 等新興平台以及 Amazon 和 Yelp 等其他平台的競爭,因此競爭其實相當激烈,他們並沒有壟斷優勢。
\n來源:Verge
\n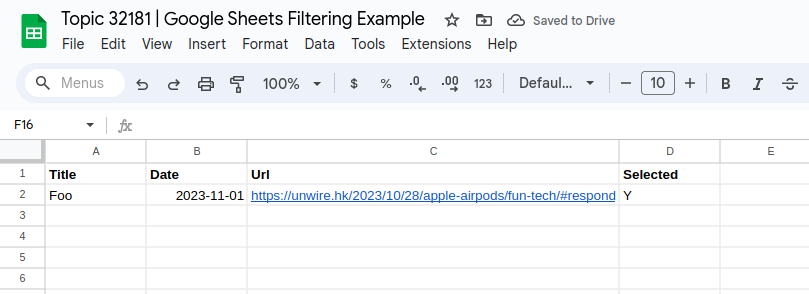
{kind=link}
{kind=link}