Describe the issue/error/question
Hello, is there a simple way to extract URLs from the email body [textPlain as received by the “Email Read” node]?
Please share the workflow
Share the output returned by the last node
{{ $node["IMAP Email"].json["textPlain"] }}
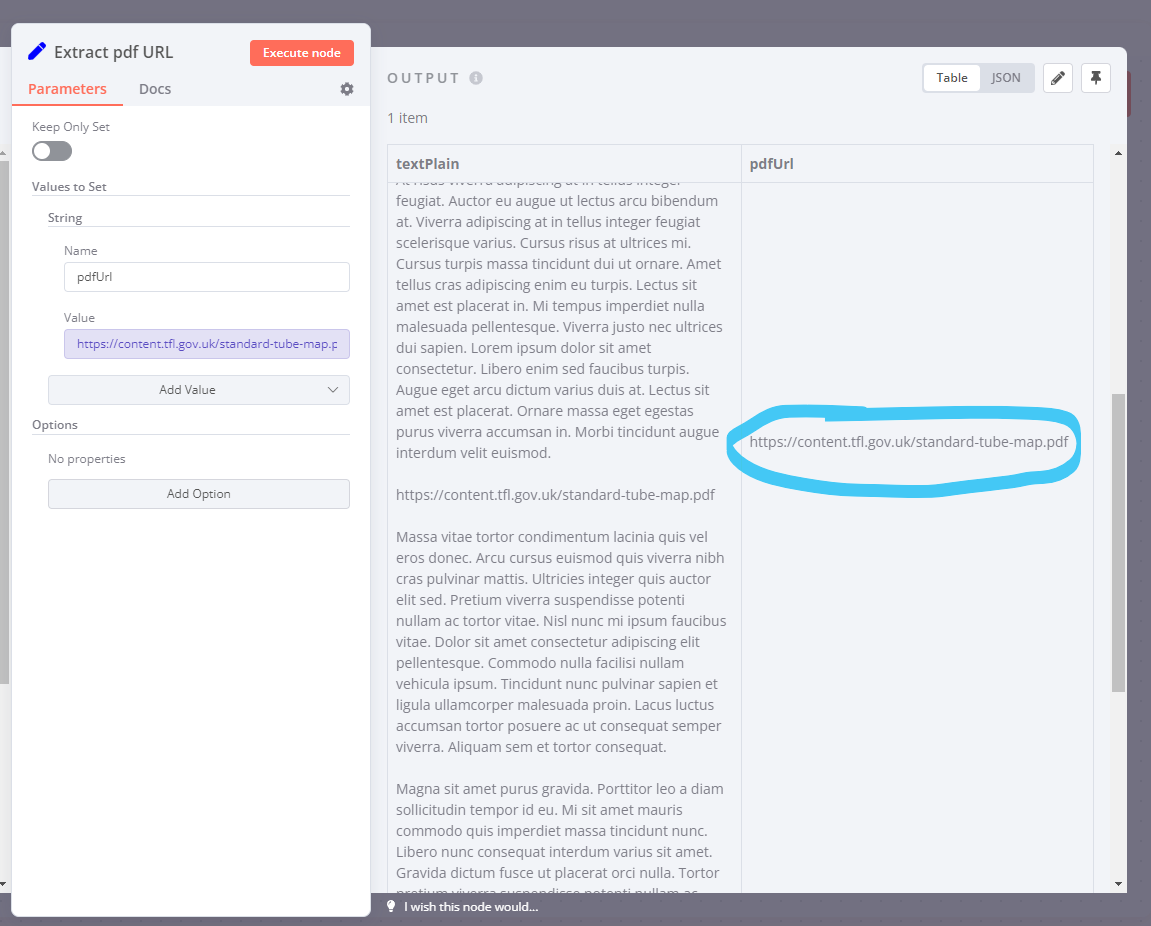
Is there a way to extract this URL everytime the “Email Read” node gets triggered, so I can pass the extracted text into “Get HTTP Request” to obtain the PDF binary? This URL will always end in .pdf and start with https://acme.com
Maybe something along the lines of find/search node using patterns and extract.
This binary will ultimately be used for “Read PDF” node.
Information on your n8n setup
-
n8n version: 0.191.1
-
Database you’re using (default: SQLite): Postgres
-
Running n8n with the execution process [own(default), main]: own
-
Running n8n via [Docker, npm, n8n.cloud, desktop app]: Docker
Hi @physx911, based on your description I think a regular expression might be your best bet. For example like so:
This seems to work fine for my example text.
I’ve built the /(https:\/\/content.tfl.gov.uk.+\.pdf)/gm regular expression with regex101, you can check it out here in more detail: regex101: build, test, and debug regex
Hope this helps! Let me know if you have any questions on this.
1 Like
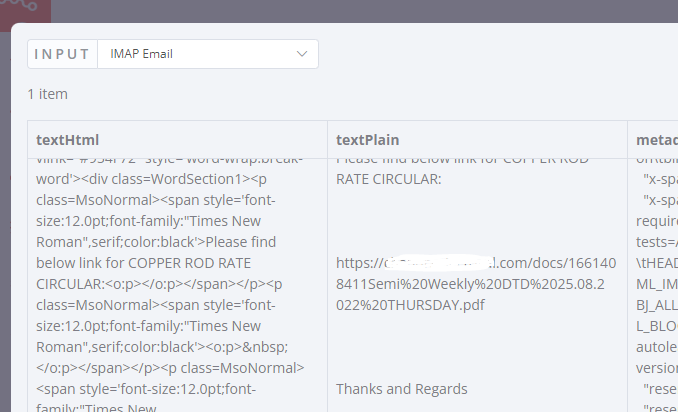
Thank you for your reply. Unfortunately, the results I get in “textPlain” from ReadEmail node seem strange, there appears a random return line.
https://acme.com/docs/
somedirectory/example.pdf
Due to this no match gets returned (https:\/\/acme.com.+\.pdf)/gm
https://regex101.com/r/CqPMGX/1
I tried using /s flag however, the match would now include the return key, making the string for the HTTP Request node invalid.
Is there a way to prevent this behavior of the ReadEmail node?
In that case you could consider replacing line breaks before applying your regex, for example by using .replace() like so:
If this doesn’t work for you, could you share an example of the JSON output from your IMAP Email node? You can, of course, redact the actual values in the text, I am just interested about the exact structure of the data. You can copy the JSON output like so:
Thank you, I performed some workaround to get past this and extracted using your solution.
1 Like