Maybe I’m missing something here, but I spend most of my time cleaning the output from the LLM.
For example, when I ask for a Markdown document, it is usually wrapped with:
```markdown\n
Similarly, when I ask for JSON, I often get something like:
“Here is the JSON:”
I include instructions to not wrap the content, but I still receive it that way, even with different models.
So, I’d like to ask for some advice on this. How can I get clean JSON/Markdown documents? Or, how do you clean them in n8n? Is there an easy solution for this?
Thank you very much!
What is the error message (if any)?
Please share your workflow
(Select the nodes on your canvas and use the keyboard shortcuts CMD+C/CTRL+C and CMD+V/CTRL+V to copy and paste the workflow.)
LLMs often wrap their responses in extra text (e.g., "Here is the JSON:" or triple backticks for Markdown). Even when explicitly instructed not to, this behavior persists across models. Here are two methods I use to clean the output:
Use a Function Node to Clean JSON/Markdown
To remove extra text and formatting, use a Function node after your LLM response:
let output = $json["response"]; // Adjust based on your LLM output structure
// Remove Markdown code block wrappers
output = output.replace(/^```(?:json|markdown)?\n?/, "").replace(/\n?```$/, "");
// Remove common LLM text prefixes
output = output.replace(/^(Here is the JSON:|Here is your Markdown document:)\s*/, "");
return [{ cleanedOutput: output }];
If you prefer no Function node, use a Set node and add this in an expression field:
{{$json["response"].replace(/^```(?:json|markdown)?\n?/, "").replace(/\n?```$/, "").replace(/^(Here is the JSON:|Here is your Markdown document:)\s*/, "")}}
I had similar problem so I am using JS code to clean the extra texts and reformat the json depends on my expected format. Please check THIS TOPIC for code and workflow.
Instead of adding an instruction to ‘not wrap the content’ you can try to be more specific and tell it to ‘output only basic markdown formatted string that won’t break the json string’
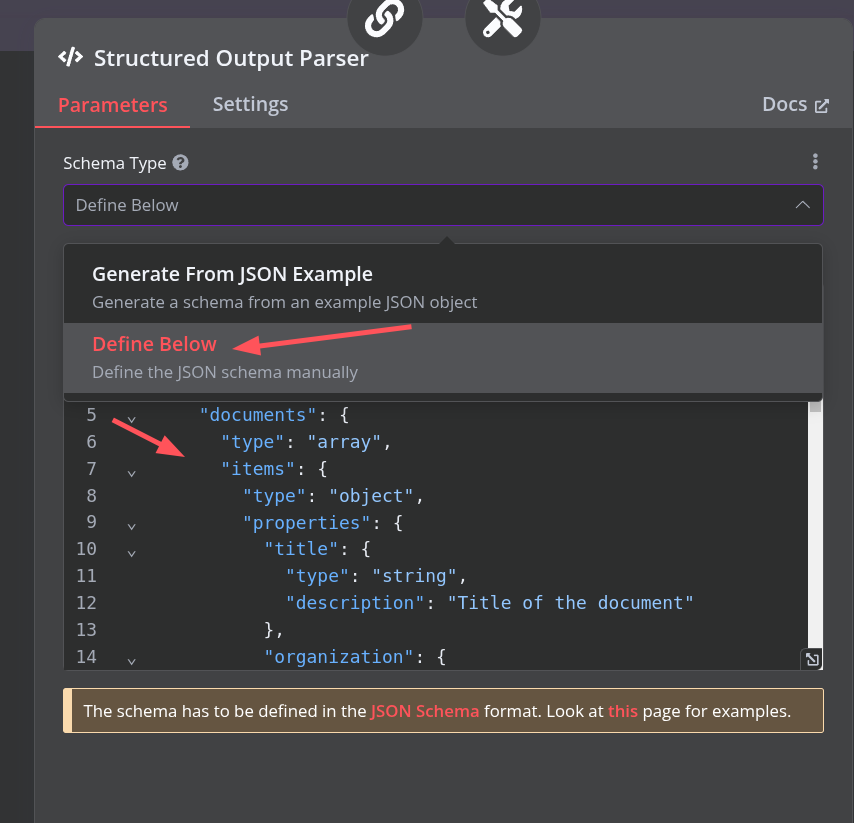
From my experience I get best results by providing JSON Schema to the structured output parser. Most of the times the LLM is smart enough to follow the schema and generates perfect format and if it doesn’t the fail-safe LLM fixes it. You can ask any free ai chatbot to generate the schema for you from an example and review it.
OK but the proposed solution still relies on the LLM to generate a valid JSON without enforcing it. But most LLM’s support an advanced JSON mode where the output is guaranteed to follow a given schema (in most cases a Pydantic schema is used), it’s enforced at the token sampling level in the LLM. Does n8n support this?
See: