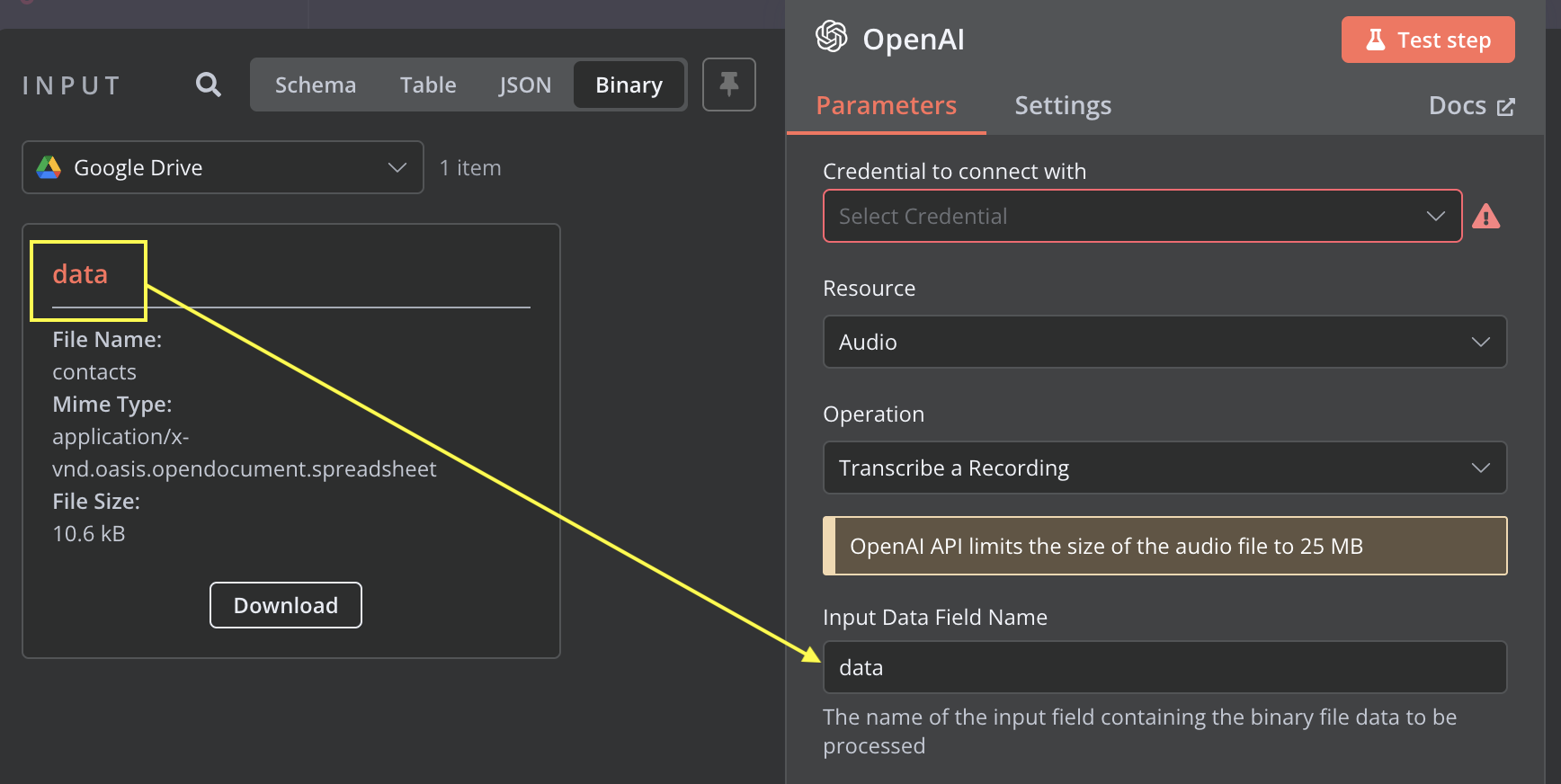
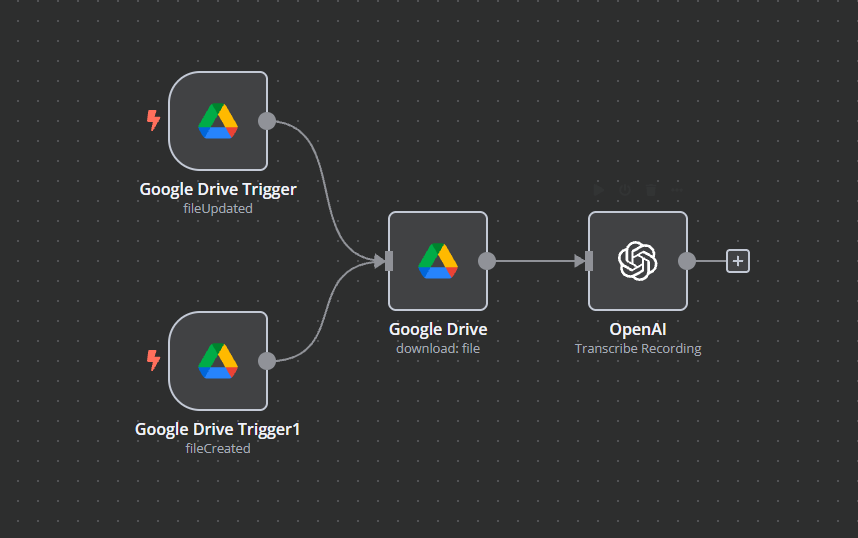
Describe the problem/error/question
How to setup HTTP Request to use Google Cloud Speech-to-Text api ?
Can I use Google Cloud Natural Language OAuth2 API or must use Google Service Account account ?
I had run the on the Google cloud successfully and got the code as following, how can I implement into n8n?
<import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
MAX_AUDIO_LENGTH_SECS = 8 * 60 * 60
def run_batch_recognize():
Instantiates a client.
client = SpeechClient()
The output path of the transcription result.
gcs_output_folder = “gs://bucket”
The name of the audio file to transcribe:
audio_gcs_uri = “gs://bucket/AUDIO_FILE.wav”
config = cloud_speech.RecognitionConfig(
explicit_decoding_config=cloud_speech.ExplicitDecodingConfig(
encoding=cloud_speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=24000,
audio_channel_count=1
),
features=cloud_speech.RecognitionFeatures(
enable_word_confidence=true,
enable_word_time_offsets=true,
multi_channel_mode=cloud_speech.RecognitionFeatures.MultiChannelMode.SEPARATE_RECOGNITION_PER_CHANNEL,
),
model=“long”,
language_codes=[“en-US”],
)
output_config = cloud_speech.RecognitionOutputConfig(
gcs_output_config=cloud_speech.GcsOutputConfig(uri=gcs_output_folder),
)
files = [cloud_speech.BatchRecognizeFileMetadata(uri=audio_gcs_uri)]
request = cloud_speech.BatchRecognizeRequest(
recognizer=“projects/PROJECT_ID/locations/global/recognizers/_”,
config=config,
files=files,
recognition_output_config=output_config,
)
operation = client.batch_recognize(request=request)
print(“Waiting for operation to complete…”)
response = operation.result(timeout=3 * MAX_AUDIO_LENGTH_SECS)
print(response)>
What is the error message (if any)?
JSON parameter need to be an valid JSON
Please share your workflow
Share the output returned by the last node
Information on your n8n setup
- n8n version:
- Database (default: SQLite):
- n8n EXECUTIONS_PROCESS setting (default: own, main):
- Running n8n via (n8n cloud):
- Operating system: Windows