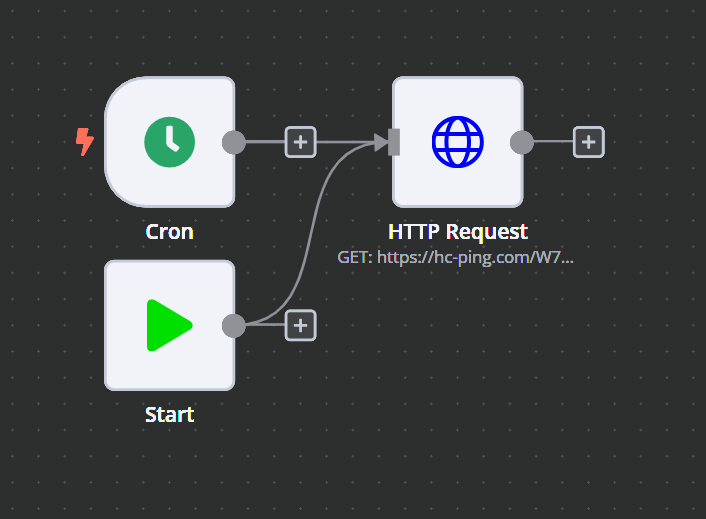
I have plenty of tasks that do simple job - run some http request every minute. The problem is that time to time they hang, and when there is 500+ of hanged running tasks n8n crashes.
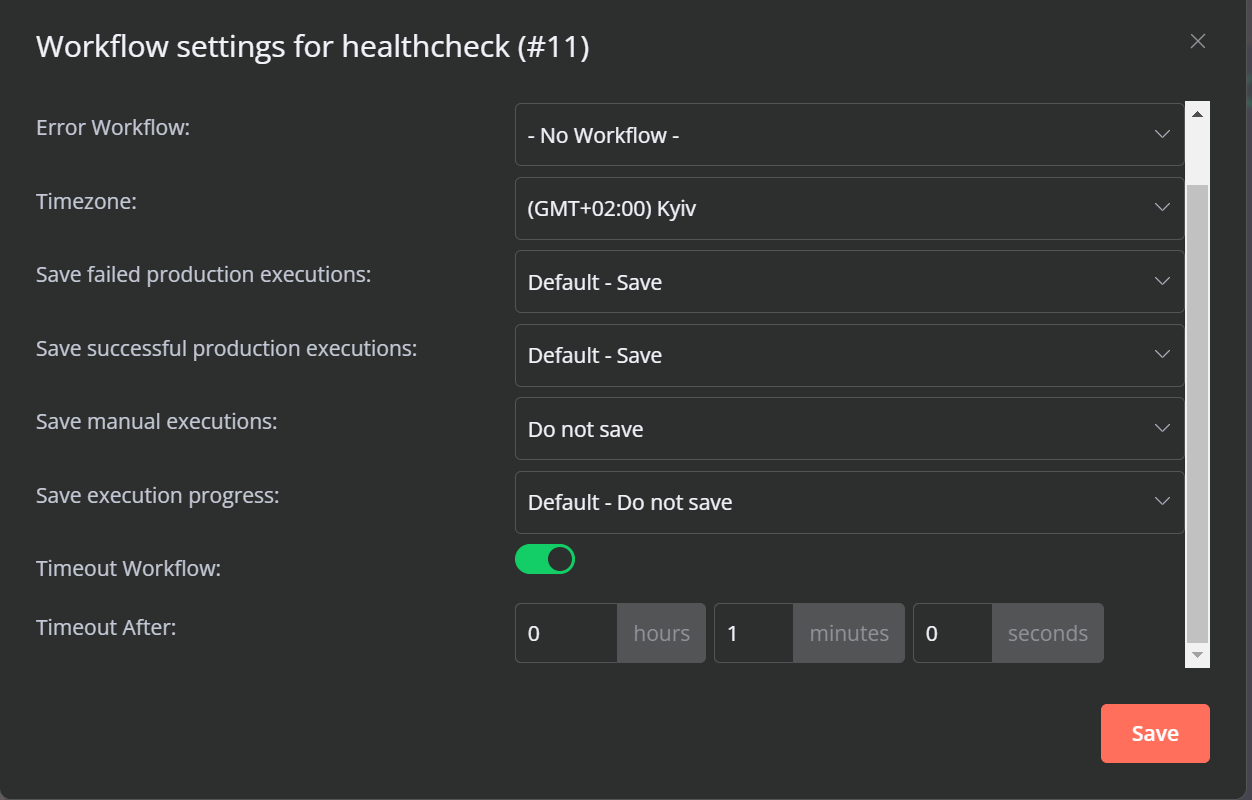
After 1 minute it should be canceled, but it hangs in running state infinitely.
I have no idea why even simple workflows hang, and it seems that timeout settings inside workflow are ignored.
Information on your n8n setup
n8n version: 1.16.0
Database (default: SQLite): PostgreSQL
n8n EXECUTIONS_PROCESS setting (default: own, main): own
Running n8n via (Docker, npm, n8n cloud, desktop app): Docker
Are you running in queue mode? It may be worth updating as well as I remember there being an issue with executions displaying as still running that was fixed recently.
Something else you could try is if you try to cancel one of the running executions does it show an error or does it stop it?
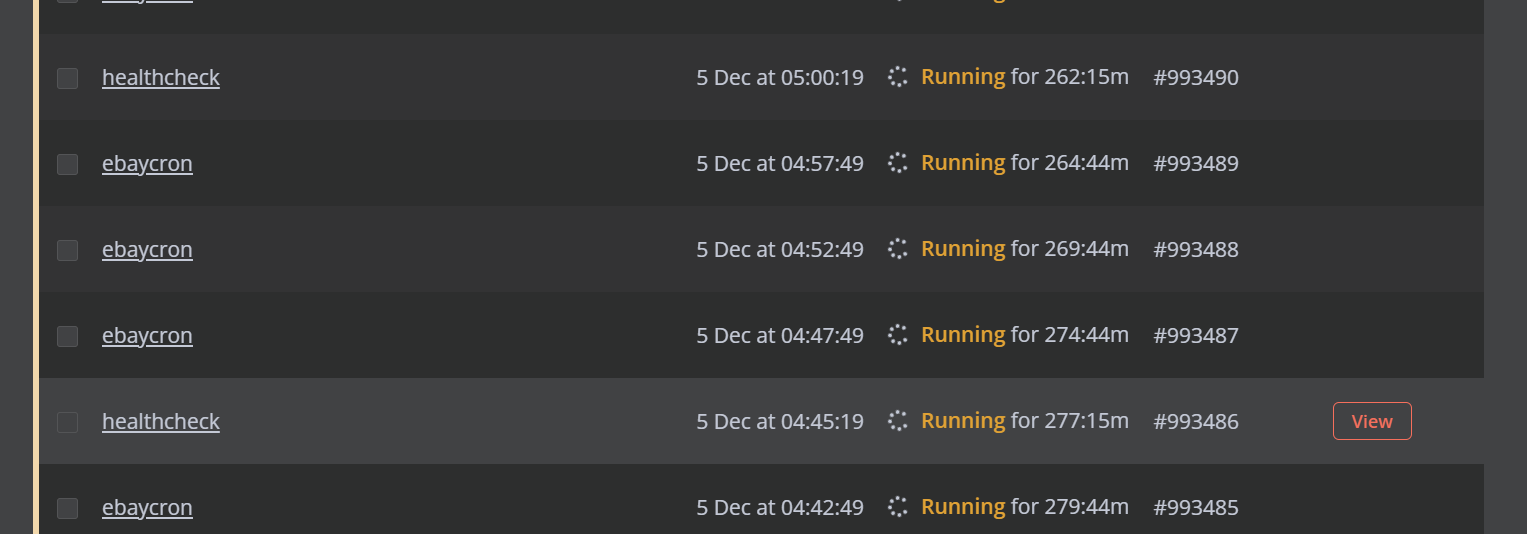
Yep, I’ve manually stop those hanged workflows. There is no error during stop from UI. It just takes some time to stop 200-300 workflows but all removals mostly success from first attempt.
It’s not looks like visualization bug, those workflows are actually running.
I’ve checked up the same on another n8n instance, and it seems that problem exists if I make lots of HTTP requests from n8n. More requests - more chance to hang.
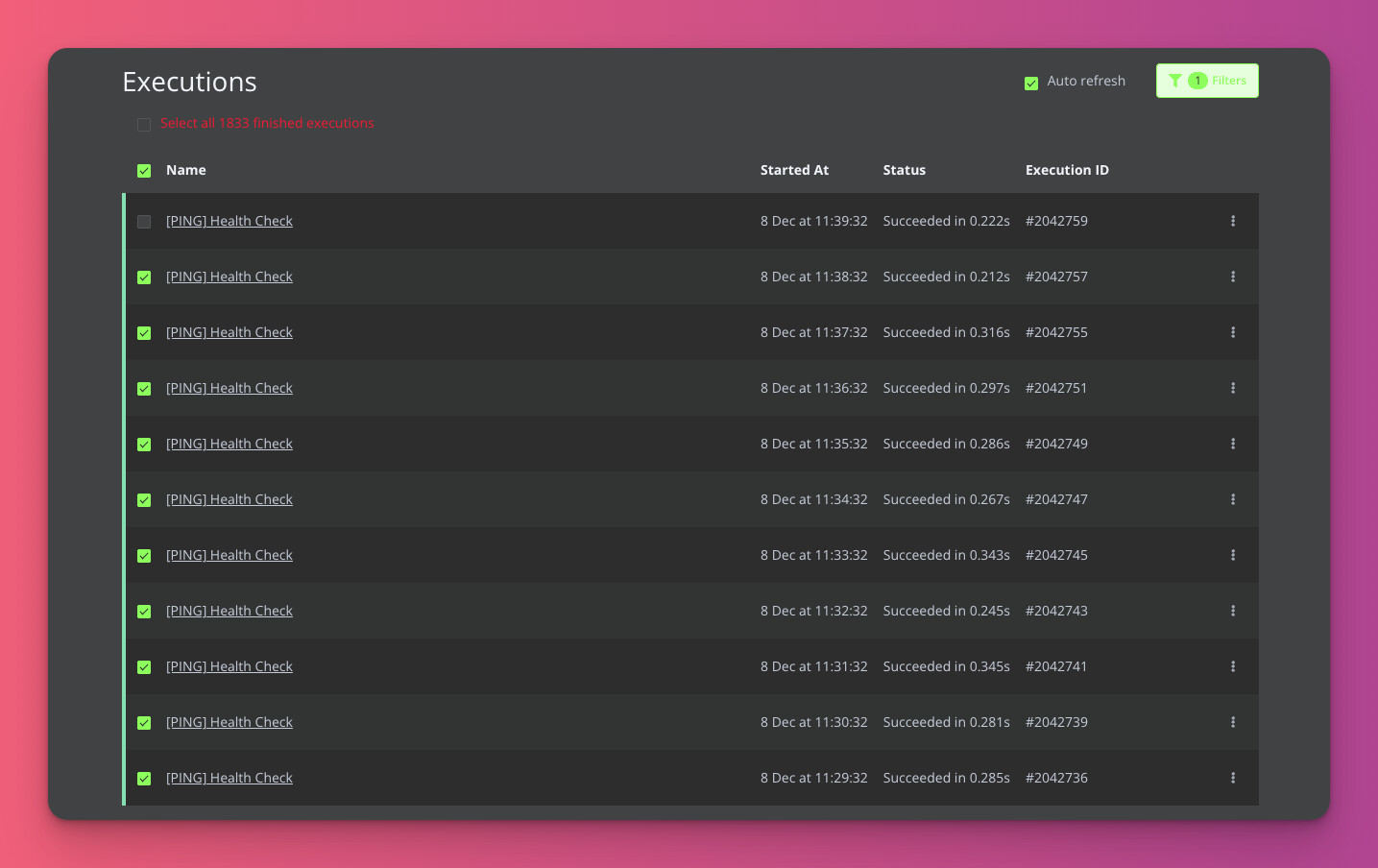
I had forgotten about this and the workflow I had created has been running every minute for a few days now on top of the normal load I put through my instance. Sadly though I have not been able to reproduce this, This is 1833 successful pings since the last restart out of the 5711 total executions my instance has ran.
I am not really sure why your instance is having this issue but as I am not able to reproduce it I suspect it is going to be a configuration or environmental issue. Can you share your n8n configuration so I can set up a local test using the same setup?