I have set up a process to store search results from Google into a database. However, everything I’ve tried so far hasn’t worked because I can’t access data from previous nodes. Here’s a brief description of the problem:
Node “HTTP REQUEST”
I call an API and receive a JSON response.
Node “Save Search”
I save some values in the database. I receive the ID of the entry as a result.
Node “Split Out”
Here, I want to split the values for “organic_results” from the JSON of the node “HTTP REQUEST” so that I can store each one individually in the database. However, I can’t access it because there is an error message:
Node “Save Results to DB”
Finally, in this node, the split results should be saved in the database, and when saving, the value from the node “Save Search” containing the ID of the entry should be saved with each entry. However, I can’t access it, and it doesn’t execute.
I’m at a loss here. What am I doing wrong? Can someone please help me?
Note that the field ‘Fields to Split Out’ expects just the name of the field, you’re trying to pass it a value now. So try entering organic_results as text.
I think that’s the problem - this node does not output the organic_results field. What if you attach the Split Out node directly to the HTTP request node?
Hey,
Yes i could attach it directly to the HTTP Request, but than it would run the Save Search Node for each Item and I need it to run only once!
And I need to use from the result the value for “insertId” (from the first sql-result) in the second sql to save for each entry additionaly to the splited data values the “insertId”.
Do you understand what I mean? To me it seems that I can’t use values in nodes that are more than one Step back.
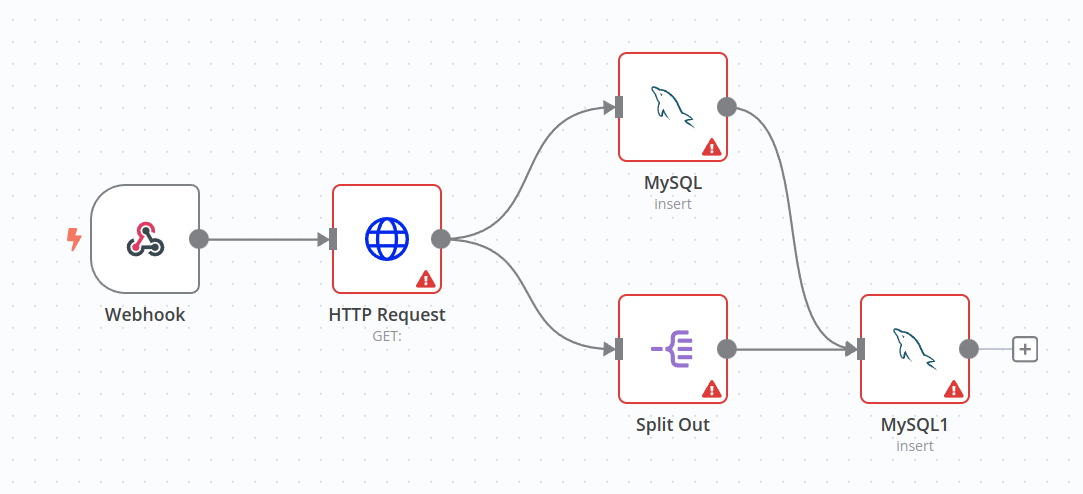
I do! You can nodes in parallel though. In the (untested) example below, the first MySQL node will only be executed once, but you can use its output in the second MySQL node, which will be executed once for each split out item:
Hello barn4k,
Thanks that worked. I made all changes as you proposed, and its working. Could you please explain me why it is nessesary to add this step? I mean the data was there before to, why is it nessesary do merge all needed data in a single array before?
It would help for future solutions to know why it is that way.
There are some key concepts here of how the n8n works.
First - if the output is an object, then it will be processed as one item (one execution per node). If the output is an array - then it will be processed for every item of that array (N executions per node, for each item of N items).
Next, it’s your design. You have an HTTP node that outputs all data as one item. Then you need to save that data into the DB and receive the insertionID for the whole results. That part was quite easy. But after that, you want to save each organic_result of the HTTP node as a separate entry in the DB. To do that, n8n must process items one by one. So how to tell it to do so? You need to output them as an array of elements (see my first paragraph). As your output of the HTTP node is not the array but an object with a nested array, you need to move that array to the top level.
For that, you have the Split Out node. However, it does not work with the absolute references (it cannot access data that is outputted somewhere in the previous nodes. It only accesses the output of the last node. So to force the proper split, we should provide the results of the HTTP node once more. That’s why we have the Edit Fields node. It acts as a proxy. Plus it has one useful ability to add the output of the previous node to the results (the same is for the Split Out node).
Actually, you can omit the insertionID field and not pull it to the last node and use the absolute reference $('nodename').last().json instead.