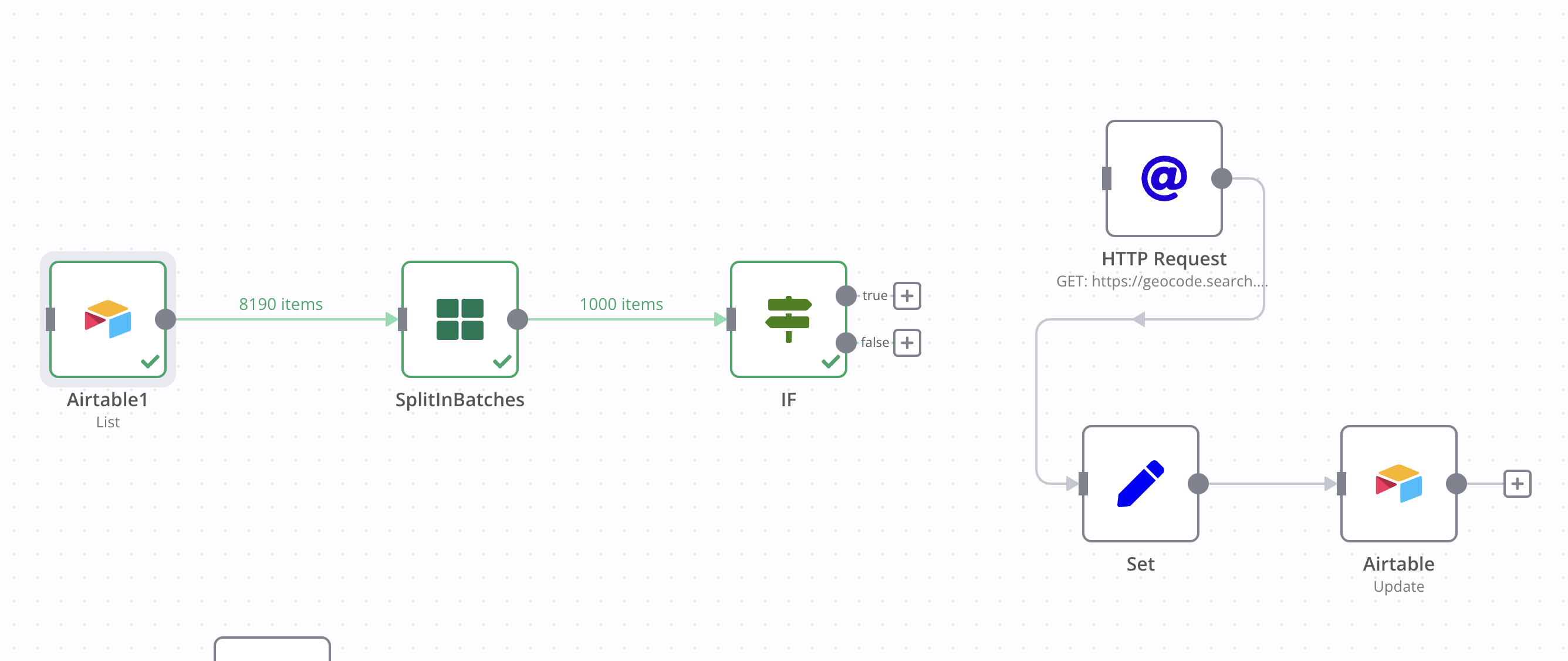
Call in a Table of unstructured addresses from an AirTable Base - THIS IS SUCCESSFUL AND CALLS IN JUST UNDER 9000 fields. This is the first node in the image (Airtable1)
I want to pass these to a Geocoder (HERE.com) to pass the addresses back to me in a Structured format (which I have done successfully by testing one field), but I don’t want to hammer their API with all 9000 at once, so thought I would need something like the Batch node, but I’m struggling to understand how I should implement it. Ideally I would like to Batch them to send 500 addresses to geocode at a time. This is the ‘experimental’ part of the process nodes 2 & 3 in the image (SplitinBatches & IF).
After Batching I imagine sending them to the Geocoder (shown in Node 4 - HTTP Request) - THIS IS SUCCESSFUL AND CORRECTLY SPITS OUT MY ADDRESSES IN THE NEW STRUCTURED FORMAT.
I then Set the fields in the Node 5 (Set) - THIS IS SUCCESSFUL
And then Update the Airtable with the new structured address data for those original Airtable IDs - THIS IS SUCCESSFUL
So my main issue is point 2, how to actually Batch the Airtable List, and ensure it (1) loops through all the 9000 addresses until they are complete and (2) only processes addresses/airtable IDs that have not already been processed.
It would be useful to know (1) if there is an API failure at some point (maybe because of contravening Here.com’s API rate limit for instance) and (2) what then happens? Do I then have to run the whole thing again? How do I ensure that those that were successful are not included in the re-run?
Any help or advice would be greatly appreciated.
PS I’m not sure how to add the actual n8n workflow without exposing my confidential data, so if there’s a way, and it’s easier to help me (as opposed to looking at an image) please advise
my main issue is point 2, how to actually Batch the Airtable List, and ensure it (1) loops through all the 9000 addresses until they are complete
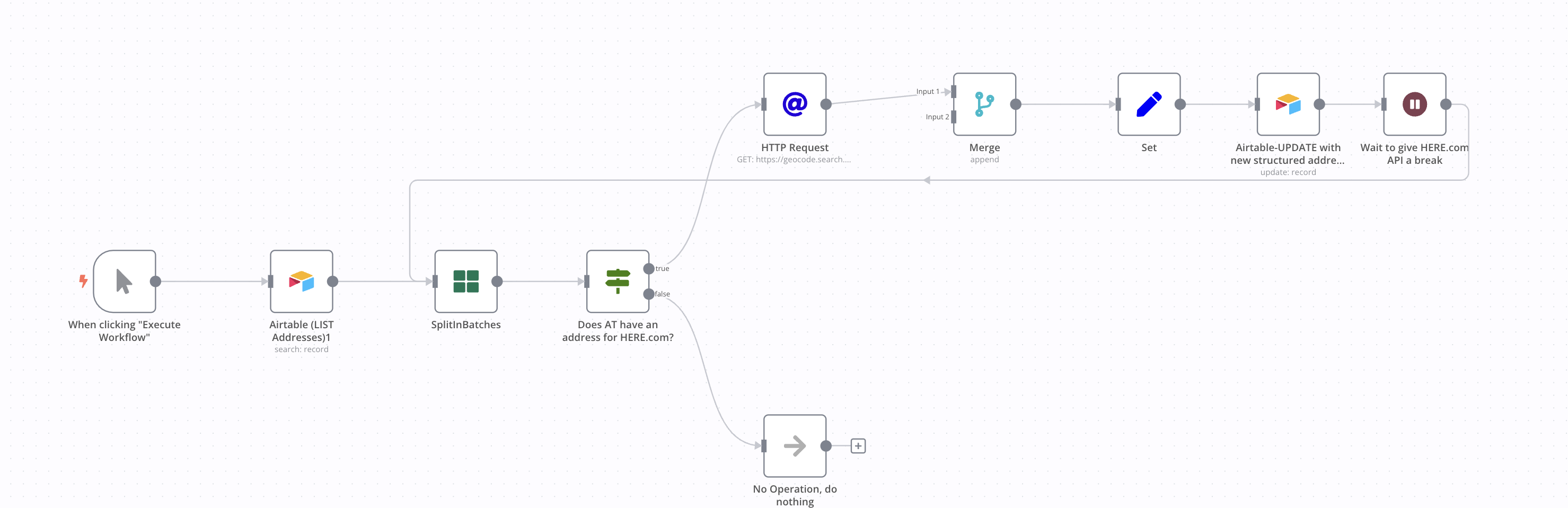
Hi @spessex, it seems you’re on a good path already. The only thing you’d need to add in order to loop through the rest of the items (and not just the first batch) would be to close your loop.
So something like this:
This of course uses dummy data and an IF condition that won’t work for your specific data structure, but the basic idea should of this flow should still work for you.
To avoid hitting rate limits you can reduce the batch size and increase the Wait time as needed. As for retrying, n8n allows to restart a failed execution from the failed node onwards through the execution list. So you wouldn’t have to re-run everything:
It looks like it works, but my question is, what is the Merge node actually doing? Do I need it in my case or can it just go straight to set data?
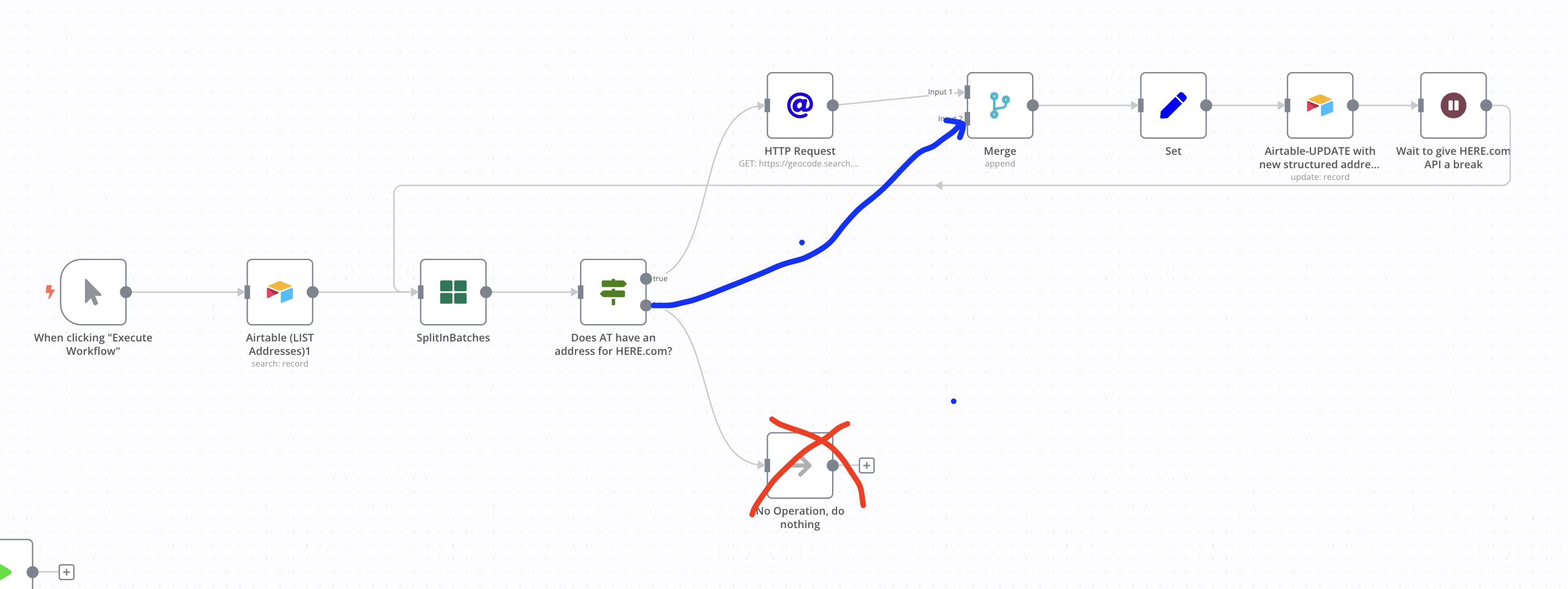
Hi @spessex, I suspect this workflow wouldn’t work if everything goes into the false branch - the workflow would just stop in this case. Connecting the false branch to the Merge node should ensure that looping continues even in this scenario.
Yep, that’s what I had in mind. You can also connect the NoOp node to the Merge node instead in case you want to keep it for workflow readability/documentation.
Yep, that’s how I think it should work, though without knowing your actual data and n8n version it’ll be hard to say with certainty. I tested my example with [email protected] fwiw